 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINF: Implicit Neural Fusion for LiDAR and Camera
Aug 28, 2023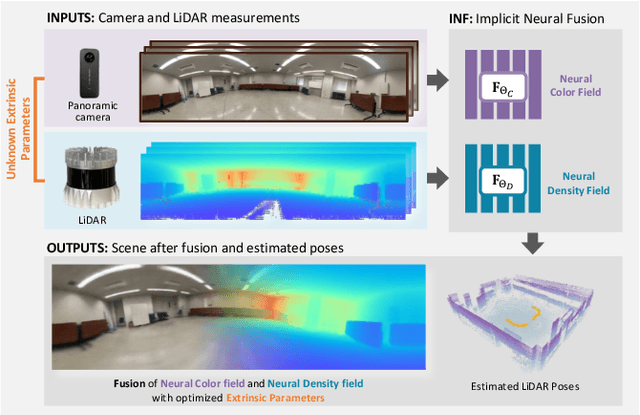
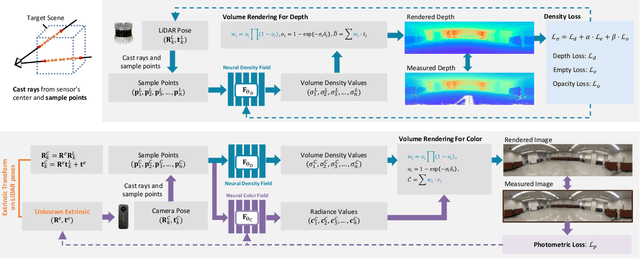


Sensor fusion has become a popular topic in robotics. However, conventional fusion methods encounter many difficulties, such as data representation differences, sensor variations, and extrinsic calibration. For example, the calibration methods used for LiDAR-camera fusion often require manual operation and auxiliary calibration targets. Implicit neural representations (INRs) have been developed for 3D scenes, and the volume density distribution involved in an INR unifies the scene information obtained by different types of sensors. Therefore, we propose implicit neural fusion (INF) for LiDAR and camera. INF first trains a neural density field of the target scene using LiDAR frames. Then, a separate neural color field is trained using camera images and the trained neural density field. Along with the training process, INF both estimates LiDAR poses and optimizes extrinsic parameters. Our experiments demonstrate the high accuracy and stable performance of the proposed method.
Hierarchical Neural Memory Network for Low Latency Event Processing
May 29, 2023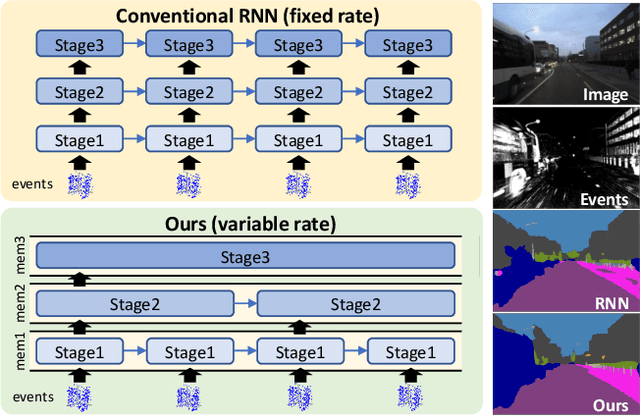



This paper proposes a low latency neural network architecture for event-based dense prediction tasks. Conventional architectures encode entire scene contents at a fixed rate regardless of their temporal characteristics. Instead, the proposed network encodes contents at a proper temporal scale depending on its movement speed. We achieve this by constructing temporal hierarchy using stacked latent memories that operate at different rates. Given low latency event steams, the multi-level memories gradually extract dynamic to static scene contents by propagating information from the fast to the slow memory modules. The architecture not only reduces the redundancy of conventional architectures but also exploits long-term dependencies. Furthermore, an attention-based event representation efficiently encodes sparse event streams into the memory cells. We conduct extensive evaluations on three event-based dense prediction tasks, where the proposed approach outperforms the existing methods on accuracy and latency, while demonstrating effective event and image fusion capabilities. The code is available at https://hamarh.github.io/hmnet/
Heterogeneous Grid Convolution for Adaptive, Efficient, and Controllable Computation
Apr 22, 2021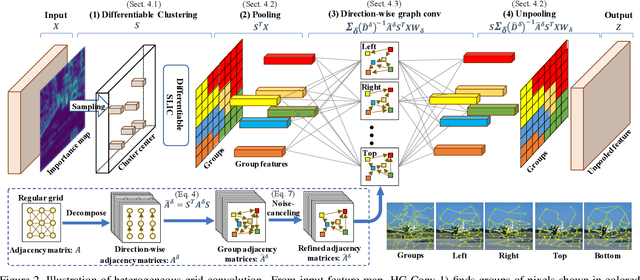
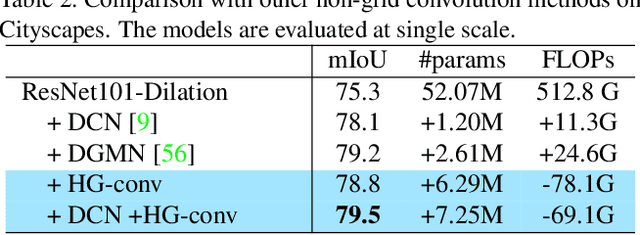

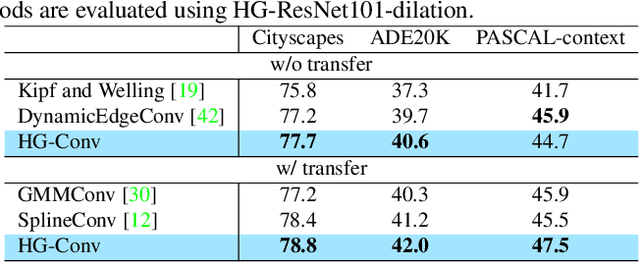
This paper proposes a novel heterogeneous grid convolution that builds a graph-based image representation by exploiting heterogeneity in the image content, enabling adaptive, efficient, and controllable computations in a convolutional architecture. More concretely, the approach builds a data-adaptive graph structure from a convolutional layer by a differentiable clustering method, pools features to the graph, performs a novel direction-aware graph convolution, and unpool features back to the convolutional layer. By using the developed module, the paper proposes heterogeneous grid convolutional networks, highly efficient yet strong extension of existing architectures. We have evaluated the proposed approach on four image understanding tasks, semantic segmentation, object localization, road extraction, and salient object detection. The proposed method is effective on three of the four tasks. Especially, the method outperforms a strong baseline with more than 90% reduction in floating-point operations for semantic segmentation, and achieves the state-of-the-art result for road extraction. We will share our code, model, and data.
Epipolar-Guided Deep Object Matching for Scene Change Detection
Jul 30, 2020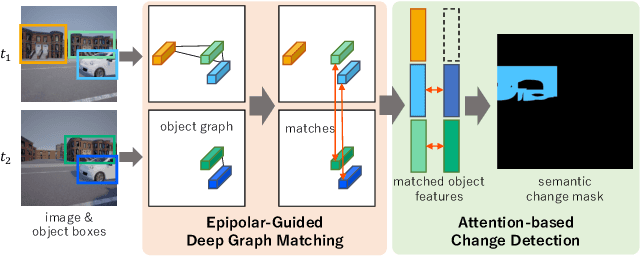
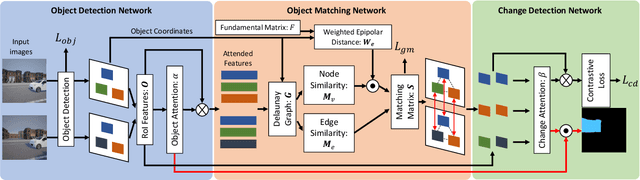
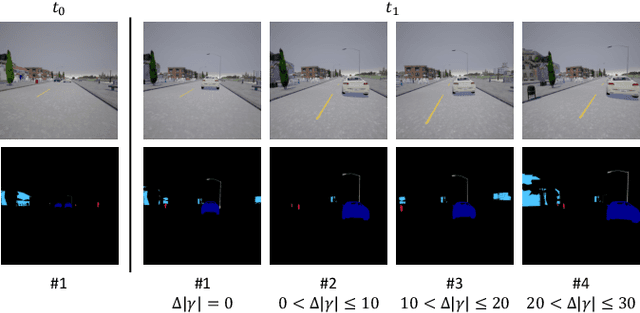

This paper describes a viewpoint-robust object-based change detection network (OBJ-CDNet). Mobile cameras such as drive recorders capture images from different viewpoints each time due to differences in camera trajectory and shutter timing. However, previous methods for pixel-wise change detection are vulnerable to the viewpoint differences because they assume aligned image pairs as inputs. To cope with the difficulty, we introduce a deep graph matching network that establishes object correspondence between an image pair. The introduction enables us to detect object-wise scene changes without precise image alignment. For more accurate object matching, we propose an epipolar-guided deep graph matching network (EGMNet), which incorporates the epipolar constraint into the deep graph matching layer used in OBJCDNet. To evaluate our network's robustness against viewpoint differences, we created synthetic and real datasets for scene change detection from an image pair. The experimental results verified the effectiveness of our network.
Privacy Preserving Visual SLAM
Jul 27, 2020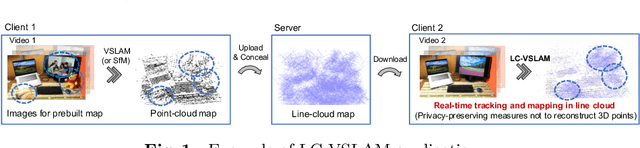

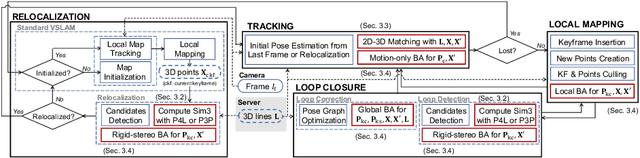

This study proposes a privacy-preserving Visual SLAM framework for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Previous studies have proposed localization methods to estimate a camera pose using a line-cloud map for a single image or a reconstructed point cloud. These methods offer a scene privacy protection against the inversion attacks by converting a point cloud to a line cloud, which reconstruct the scene images from the point cloud. However, they are not directly applicable to a video sequence because they do not address computational efficiency. This is a critical issue to solve for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Moreover, there has been no study on a method to optimize a line-cloud map of a server with a point cloud reconstructed from a client video because any observation points on the image coordinates are not available to prevent the inversion attacks, namely the reversibility of the 3D lines. The experimental results with synthetic and real data show that our Visual SLAM framework achieves the intended privacy-preserving formation and real-time performance using a line-cloud map.
SOIC: Semantic Online Initialization and Calibration for LiDAR and Camera
Mar 09, 2020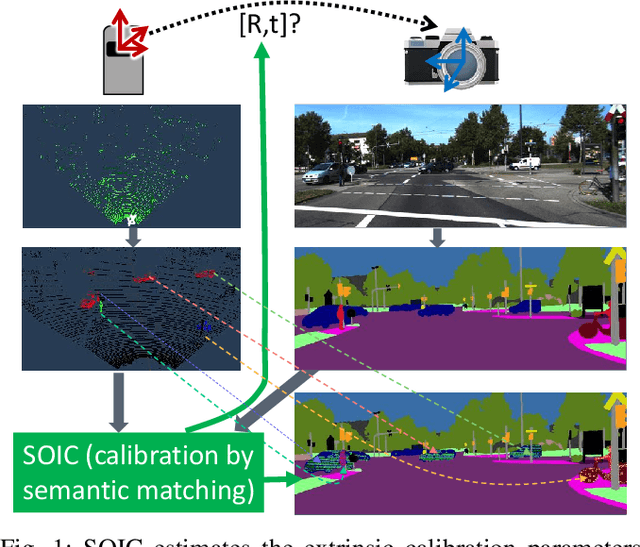
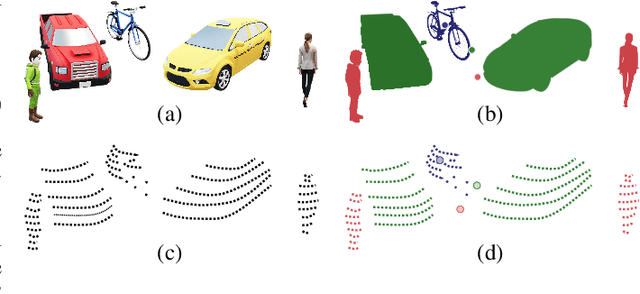
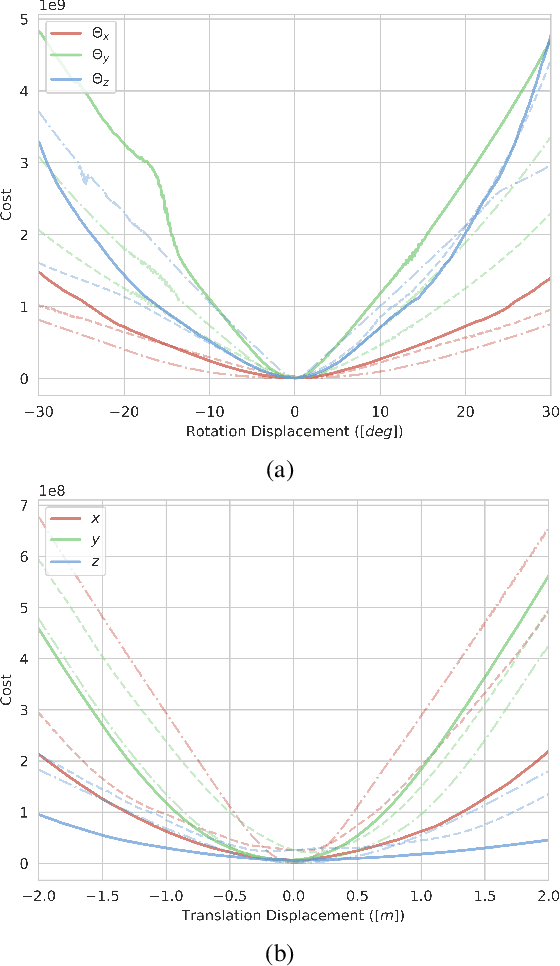
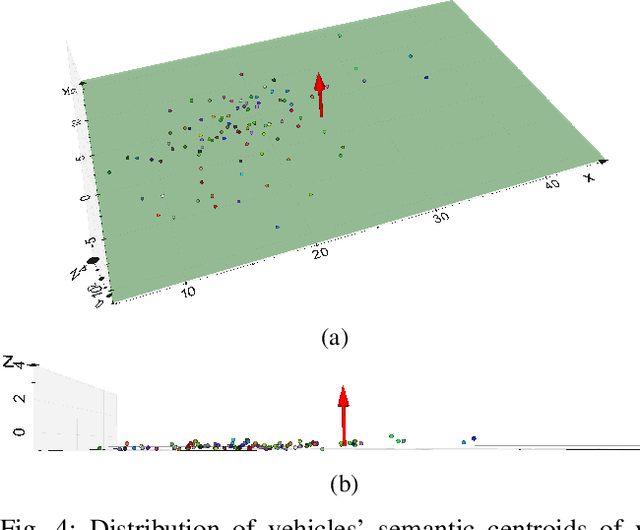
This paper presents a novel semantic-based online extrinsic calibration approach, SOIC (so, I see), for Light Detection and Ranging (LiDAR) and camera sensors. Previous online calibration methods usually need prior knowledge of rough initial values for optimization. The proposed approach removes this limitation by converting the initialization problem to a Perspective-n-Point (PnP) problem with the introduction of semantic centroids (SCs). The closed-form solution of this PnP problem has been well researched and can be found with existing PnP methods. Since the semantic centroid of the point cloud usually does not accurately match with that of the corresponding image, the accuracy of parameters are not improved even after a nonlinear refinement process. Thus, a cost function based on the constraint of the correspondence between semantic elements from both point cloud and image data is formulated. Subsequently, optimal extrinsic parameters are estimated by minimizing the cost function. We evaluate the proposed method either with GT or predicted semantics on KITTI dataset. Experimental results and comparisons with the baseline method verify the feasibility of the initialization strategy and the accuracy of the calibration approach. In addition, we release the source code at https://github.com/--/SOIC.
OpenVSLAM: A Versatile Visual SLAM Framework
Oct 10, 2019
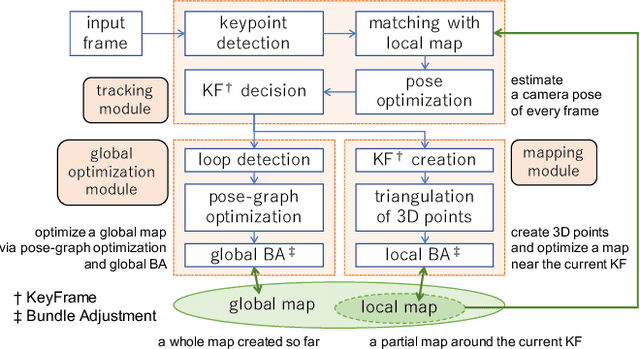
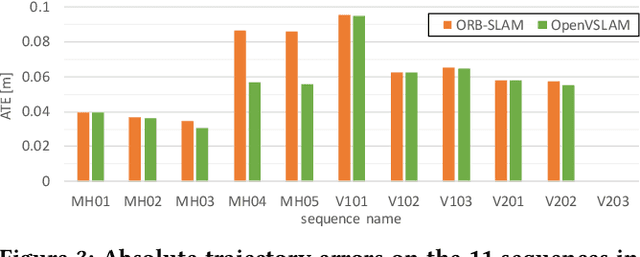
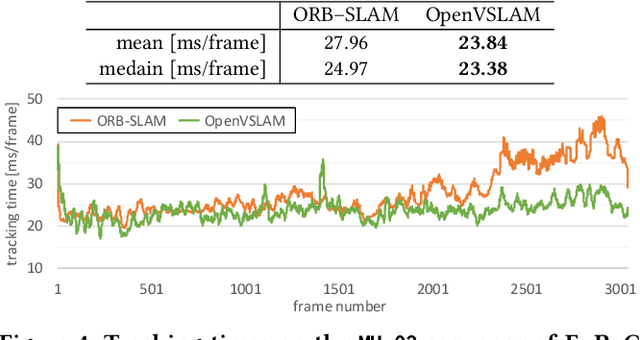
In this paper, we introduce OpenVSLAM, a visual SLAM framework with high usability and extensibility. Visual SLAM systems are essential for AR devices, autonomous control of robots and drones, etc. However, conventional open-source visual SLAM frameworks are not appropriately designed as libraries called from third-party programs. To overcome this situation, we have developed a novel visual SLAM framework. This software is designed to be easily used and extended. It incorporates several useful features and functions for research and development. OpenVSLAM is released at https://github.com/xdspacelab/openvslam under the 2-clause BSD license.
MeshDepth: Disconnected Mesh-based Deep Depth Prediction
May 03, 2019
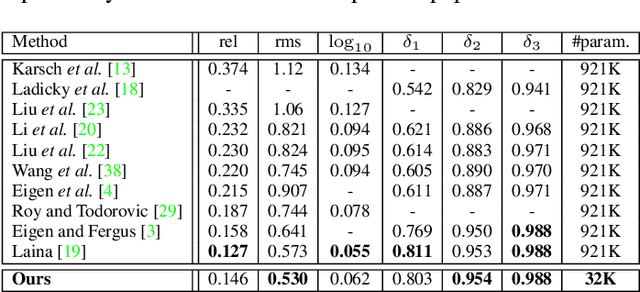


We propose a novel method for mesh-based single-view depth estimation using Convolutional Neural Networks (CNNs). Conventional CNN-based methods are only suitable for representing simple 3D objects because they estimate the deformation from a predefined simple mesh such as a cube or sphere. As a 3D scene representation, we introduce a disconnected mesh made of 2D mesh adaptively determined on the input image. We made a CNN-based framework to compute depths and normals of faces of the mesh. Because of the representation, our method can handle complex indoor scenes. Using common RGBD datasets, we show that our model achieved best or comparable performance comparing to the state-of-the-art pixel-wise dense methods. It should be noted that our method significantly reduces the number of the parameter representing the 3D structure.
Rare Event Detection using Disentangled Representation Learning
Dec 04, 2018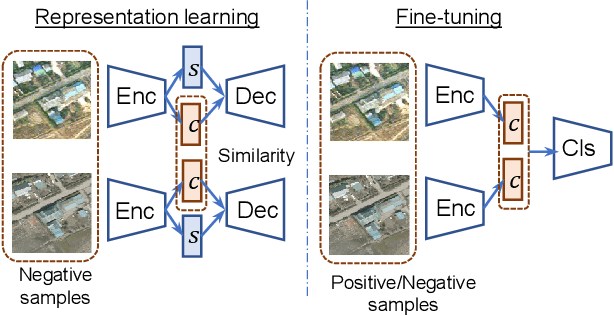
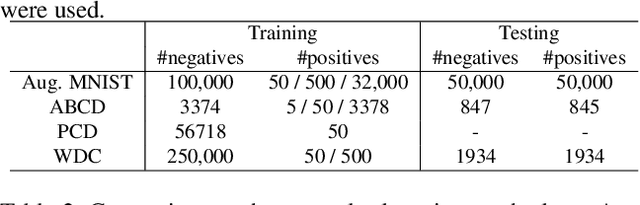
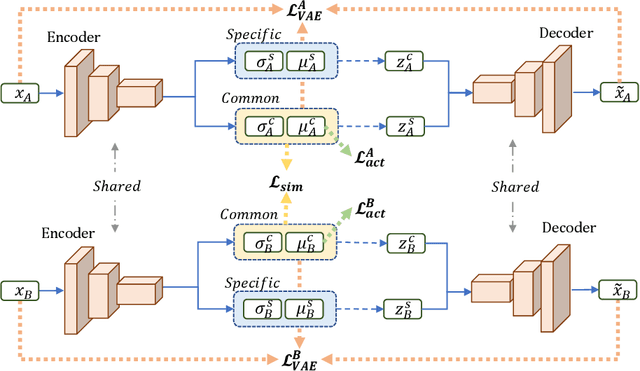
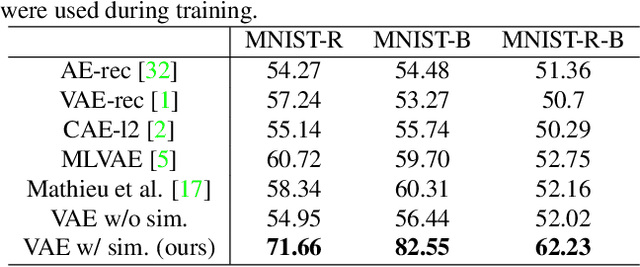
This paper presents a novel method for rare event detection from an image pair with class-imbalanced datasets. A straightforward approach for event detection tasks is to train a detection network from a large-scale dataset in an end-to-end manner. However, in many applications such as building change detection on satellite images, few positive samples are available for the training. Moreover, scene image pairs contain many trivial events, such as in illumination changes or background motions. These many trivial events and the class imbalance problem lead to false alarms for rare event detection. In order to overcome these difficulties, we propose a novel method to learn disentangled representations from only low-cost negative samples. The proposed method disentangles different aspects in a pair of observations: variant and invariant factors that represent trivial events and image contents, respectively. The effectiveness of the proposed approach is verified by the quantitative evaluations on four change detection datasets, and the qualitative analysis shows that the proposed method can acquire the representations that disentangle rare events from trivial ones.
Weakly Supervised Silhouette-based Semantic Change Detection
Nov 29, 2018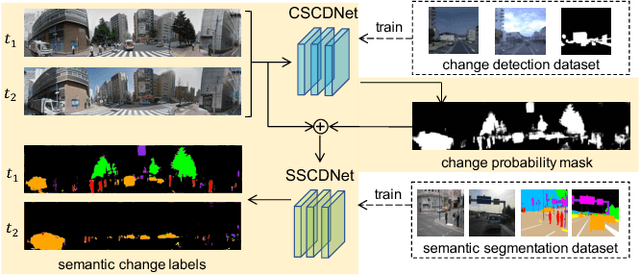
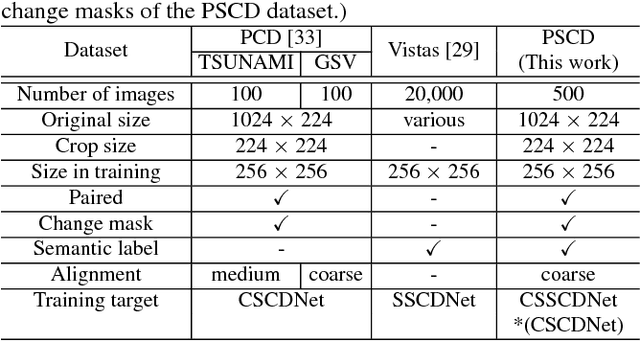
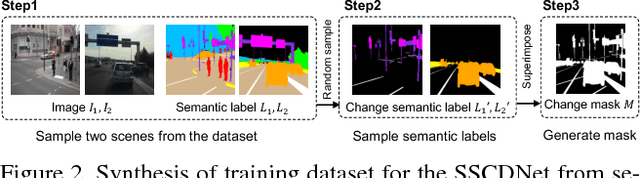
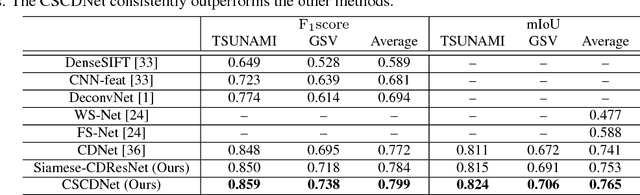
This paper presents a novel semantic change detection scheme with only weak supervision. A straightforward approach for this task is to train a semantic change detection network directly from a large-scale dataset in an end-to-end manner. However, a specific dataset for this new task, which is usually labor-intensive and time-consuming, becomes indispensable. To avoid this problem, we propose to train this kind of network from existing datasets by dividing this task into change detection and semantic extraction. On the other hand, the difference in camera viewpoints, for example images of the same scene captured from a vehicle-mounted camera at different time points, usually brings a challenge to the change detection task. To address this challenge, we propose a new siamese network structure with the introduction of correlation layer. In addition, we create a publicly available dataset for semantic change detection to evaluate the proposed method. Both the robustness to viewpoint difference in change detection task and the effectiveness for semantic change detection of the proposed networks are verified by the experimental results.