 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImCLR: Implicit Contrastive Learning for Image Classification
Paper and Code
Nov 25, 2020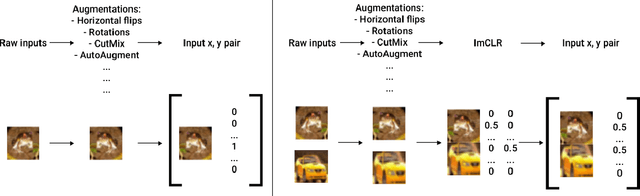


Contrastive learning is an effective method for learning visual representations. In most cases, this involves adding an explicit loss function to encourage similar images to have similar representations, and different images to have different representations. Inspired by contrastive learning, we introduce a clever input construction for Implicit Contrastive Learning (ImCLR), primarily in the supervised setting: there, the network can implicitly learn to differentiate between similar and dissimilar images. Each input is presented as a concatenation of two images, and the label is the mean of the two one-hot labels. Furthermore, this requires almost no change to existing pipelines, which allows for easy integration and for fair demonstration of effectiveness on a wide range of well-accepted benchmarks. Namely, there is no change to loss, no change to hyperparameters, and no change to general network architecture. We show that ImCLR improves the test error in the supervised setting across a variety of settings, including 3.24% on Tiny ImageNet, 1.30% on CIFAR-100, 0.14% on CIFAR-10, and 2.28% on STL-10. We show that this holds across different number of labeled samples, maintaining approximately a 2% gap in test accuracy down to using only 5% of the whole dataset. We further show that gains hold for robustness to common input corruptions and perturbations at varying severities with a 0.72% improvement on CIFAR-100-C, and in the semi-supervised setting with a 2.16% improvement with the standard benchmark $\Pi$-model. We demonstrate that ImCLR is complementary to existing data augmentation techniques, achieving over 1% improvement on CIFAR-100 and 2% improvement on Tiny ImageNet by combining ImCLR with CutMix over either baseline, and 2% by combining ImCLR with AutoAugment over either baseline.