 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREX: Revisiting Budgeted Training with an Improved Schedule
Jul 09, 2021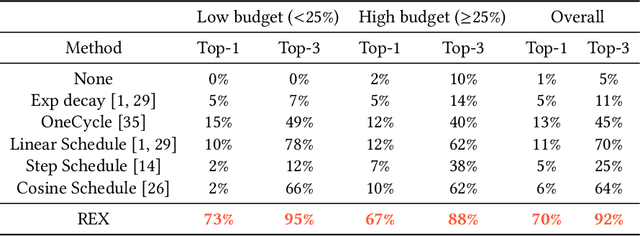

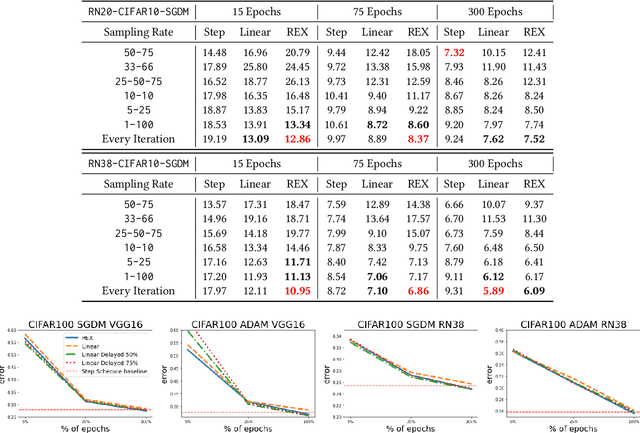
Deep learning practitioners often operate on a computational and monetary budget. Thus, it is critical to design optimization algorithms that perform well under any budget. The linear learning rate schedule is considered the best budget-aware schedule, as it outperforms most other schedules in the low budget regime. On the other hand, learning rate schedules -- such as the \texttt{30-60-90} step schedule -- are known to achieve high performance when the model can be trained for many epochs. Yet, it is often not known a priori whether one's budget will be large or small; thus, the optimal choice of learning rate schedule is made on a case-by-case basis. In this paper, we frame the learning rate schedule selection problem as a combination of $i)$ selecting a profile (i.e., the continuous function that models the learning rate schedule), and $ii)$ choosing a sampling rate (i.e., how frequently the learning rate is updated/sampled from this profile). We propose a novel profile and sampling rate combination called the Reflected Exponential (REX) schedule, which we evaluate across seven different experimental settings with both SGD and Adam optimizers. REX outperforms the linear schedule in the low budget regime, while matching or exceeding the performance of several state-of-the-art learning rate schedules (linear, step, exponential, cosine, step decay on plateau, and OneCycle) in both high and low budget regimes. Furthermore, REX requires no added computation, storage, or hyperparameters.
Momentum-inspired Low-Rank Coordinate Descent for Diagonally Constrained SDPs
Jul 03, 2021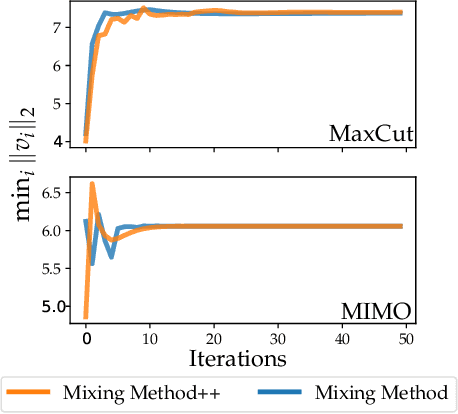
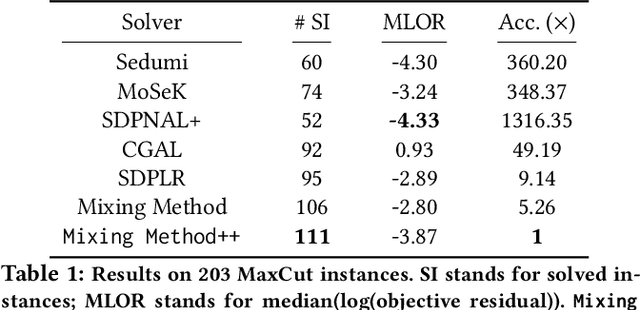
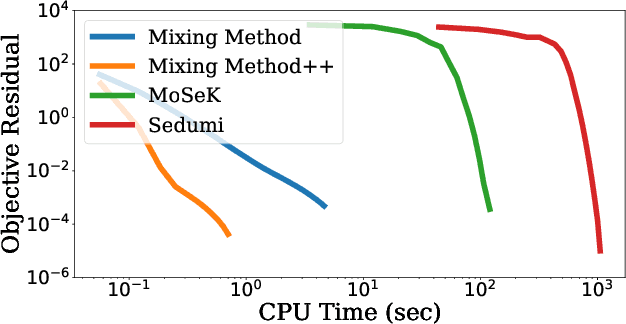

We present a novel, practical, and provable approach for solving diagonally constrained semi-definite programming (SDP) problems at scale using accelerated non-convex programming. Our algorithm non-trivially combines acceleration motions from convex optimization with coordinate power iteration and matrix factorization techniques. The algorithm is extremely simple to implement, and adds only a single extra hyperparameter -- momentum. We prove that our method admits local linear convergence in the neighborhood of the optimum and always converges to a first-order critical point. Experimentally, we showcase the merits of our method on three major application domains: MaxCut, MaxSAT, and MIMO signal detection. In all cases, our methodology provides significant speedups over non-convex and convex SDP solvers -- 5X faster than state-of-the-art non-convex solvers, and 9 to 10^3 X faster than convex SDP solvers -- with comparable or improved solution quality.