 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Prompting for Improving LLM Generation Diversity
May 21, 2025



Large Language Models (LLMs) are known to lack cultural representation and overall diversity in their generations, from expressing opinions to answering factual questions. To mitigate this problem, we propose multilingual prompting: a prompting method which generates several variations of a base prompt with added cultural and linguistic cues from several cultures, generates responses, and then combines the results. Building on evidence that LLMs have language-specific knowledge, multilingual prompting seeks to increase diversity by activating a broader range of cultural knowledge embedded in model training data. Through experiments across multiple models (GPT-4o, GPT-4o-mini, LLaMA 70B, and LLaMA 8B), we show that multilingual prompting consistently outperforms existing diversity-enhancing techniques such as high-temperature sampling, step-by-step recall, and personas prompting. Further analyses show that the benefits of multilingual prompting vary with language resource level and model size, and that aligning the prompting language with the cultural cues reduces hallucination about culturally-specific information.
LOFT: Finding Lottery Tickets through Filter-wise Training
Oct 28, 2022
Recent work on the Lottery Ticket Hypothesis (LTH) shows that there exist ``\textit{winning tickets}'' in large neural networks. These tickets represent ``sparse'' versions of the full model that can be trained independently to achieve comparable accuracy with respect to the full model. However, finding the winning tickets requires one to \emph{pretrain} the large model for at least a number of epochs, which can be a burdensome task, especially when the original neural network gets larger. In this paper, we explore how one can efficiently identify the emergence of such winning tickets, and use this observation to design efficient pretraining algorithms. For clarity of exposition, our focus is on convolutional neural networks (CNNs). To identify good filters, we propose a novel filter distance metric that well-represents the model convergence. As our theory dictates, our filter analysis behaves consistently with recent findings of neural network learning dynamics. Motivated by these observations, we present the \emph{LOttery ticket through Filter-wise Training} algorithm, dubbed as \textsc{LoFT}. \textsc{LoFT} is a model-parallel pretraining algorithm that partitions convolutional layers by filters to train them independently in a distributed setting, resulting in reduced memory and communication costs during pretraining. Experiments show that \textsc{LoFT} $i)$ preserves and finds good lottery tickets, while $ii)$ it achieves non-trivial computation and communication savings, and maintains comparable or even better accuracy than other pretraining methods.
Provably Efficient Lottery Ticket Discovery
Jul 31, 2021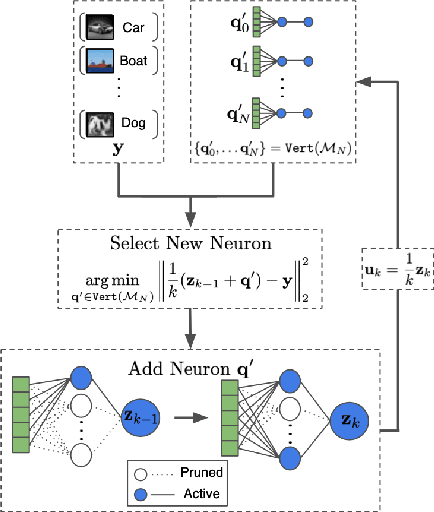
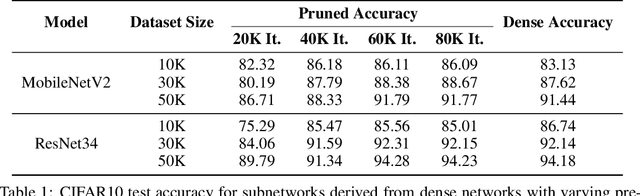
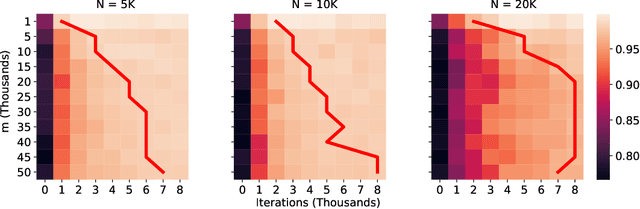

The lottery ticket hypothesis (LTH) claims that randomly-initialized, dense neural networks contain (sparse) subnetworks that, when trained an equal amount in isolation, can match the dense network's performance. Although LTH is useful for discovering efficient network architectures, its three-step process -- pre-training, pruning, and re-training -- is computationally expensive, as the dense model must be fully pre-trained. Luckily, "early-bird" tickets can be discovered within neural networks that are minimally pre-trained, allowing for the creation of efficient, LTH-inspired training procedures. Yet, no theoretical foundation of this phenomenon exists. We derive an analytical bound for the number of pre-training iterations that must be performed for a winning ticket to be discovered, thus providing a theoretical understanding of when and why such early-bird tickets exist. By adopting a greedy forward selection pruning strategy, we directly connect the pruned network's performance to the loss of the dense network from which it was derived, revealing a threshold in the number of pre-training iterations beyond which high-performing subnetworks are guaranteed to exist. We demonstrate the validity of our theoretical results across a variety of architectures and datasets, including multi-layer perceptrons (MLPs) trained on MNIST and several deep convolutional neural network (CNN) architectures trained on CIFAR10 and ImageNet.
Mitigating deep double descent by concatenating inputs
Jul 02, 2021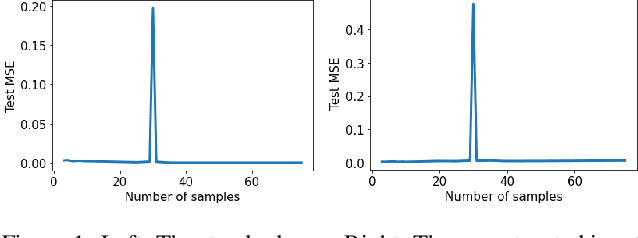
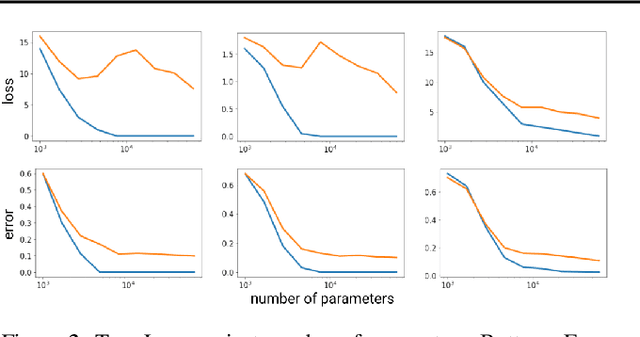
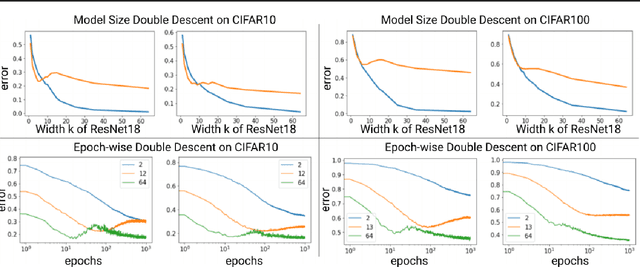
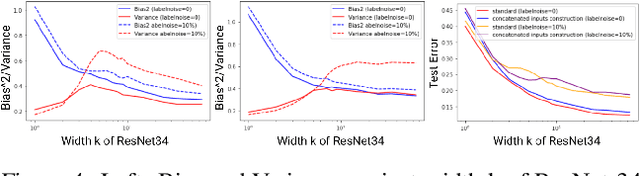
The double descent curve is one of the most intriguing properties of deep neural networks. It contrasts the classical bias-variance curve with the behavior of modern neural networks, occurring where the number of samples nears the number of parameters. In this work, we explore the connection between the double descent phenomena and the number of samples in the deep neural network setting. In particular, we propose a construction which augments the existing dataset by artificially increasing the number of samples. This construction empirically mitigates the double descent curve in this setting. We reproduce existing work on deep double descent, and observe a smooth descent into the overparameterized region for our construction. This occurs both with respect to the model size, and with respect to the number epochs.