 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing Voting Rules with Improvement Feedback
Feb 18, 2025Aggregating preferences under incomplete or constrained feedback is a fundamental problem in social choice and related domains. While prior work has established strong impossibility results for pairwise comparisons, this paper extends the inquiry to improvement feedback, where voters express incremental adjustments rather than complete preferences. We provide a complete characterization of the positional scoring rules that can be computed given improvement feedback. Interestingly, while plurality is learnable under improvement feedback--unlike with pairwise feedback--strong impossibility results persist for many other positional scoring rules. Furthermore, we show that improvement feedback, unlike pairwise feedback, does not suffice for the computation of any Condorcet-consistent rule. We complement our theoretical findings with experimental results, providing further insights into the practical implications of improvement feedback for preference aggregation.
Proportional Fairness in Non-Centroid Clustering
Oct 30, 2024We revisit the recently developed framework of proportionally fair clustering, where the goal is to provide group fairness guarantees that become stronger for groups of data points (agents) that are large and cohesive. Prior work applies this framework to centroid clustering, where the loss of an agent is its distance to the centroid assigned to its cluster. We expand the framework to non-centroid clustering, where the loss of an agent is a function of the other agents in its cluster, by adapting two proportional fairness criteria -- the core and its relaxation, fully justified representation (FJR) -- to this setting. We show that the core can be approximated only under structured loss functions, and even then, the best approximation we are able to establish, using an adaptation of the GreedyCapture algorithm developed for centroid clustering [Chen et al., 2019; Micha and Shah, 2020], is unappealing for a natural loss function. In contrast, we design a new (inefficient) algorithm, GreedyCohesiveClustering, which achieves the relaxation FJR exactly under arbitrary loss functions, and show that the efficient GreedyCapture algorithm achieves a constant approximation of FJR. We also design an efficient auditing algorithm, which estimates the FJR approximation of any given clustering solution up to a constant factor. Our experiments on real data suggest that traditional clustering algorithms are highly unfair, whereas GreedyCapture is considerably fairer and incurs only a modest loss in common clustering objectives.
Strategic Classification With Externalities
Oct 10, 2024We propose a new variant of the strategic classification problem: a principal reveals a classifier, and $n$ agents report their (possibly manipulated) features to be classified. Motivated by real-world applications, our model crucially allows the manipulation of one agent to affect another; that is, it explicitly captures inter-agent externalities. The principal-agent interactions are formally modeled as a Stackelberg game, with the resulting agent manipulation dynamics captured as a simultaneous game. We show that under certain assumptions, the pure Nash Equilibrium of this agent manipulation game is unique and can be efficiently computed. Leveraging this result, PAC learning guarantees are established for the learner: informally, we show that it is possible to learn classifiers that minimize loss on the distribution, even when a random number of agents are manipulating their way to a pure Nash Equilibrium. We also comment on the optimization of such classifiers through gradient-based approaches. This work sets the theoretical foundations for a more realistic analysis of classifiers that are robust against multiple strategic actors interacting in a common environment.
Group Fairness in Peer Review
Oct 04, 2024Large conferences such as NeurIPS and AAAI serve as crossroads of various AI fields, since they attract submissions from a vast number of communities. However, in some cases, this has resulted in a poor reviewing experience for some communities, whose submissions get assigned to less qualified reviewers outside of their communities. An often-advocated solution is to break up any such large conference into smaller conferences, but this can lead to isolation of communities and harm interdisciplinary research. We tackle this challenge by introducing a notion of group fairness, called the core, which requires that every possible community (subset of researchers) to be treated in a way that prevents them from unilaterally benefiting by withdrawing from a large conference. We study a simple peer review model, prove that it always admits a reviewing assignment in the core, and design an efficient algorithm to find one such assignment. We use real data from CVPR and ICLR conferences to compare our algorithm to existing reviewing assignment algorithms on a number of metrics.
Axioms for AI Alignment from Human Feedback
May 23, 2024



In the context of reinforcement learning from human feedback (RLHF), the reward function is generally derived from maximum likelihood estimation of a random utility model based on pairwise comparisons made by humans. The problem of learning a reward function is one of preference aggregation that, we argue, largely falls within the scope of social choice theory. From this perspective, we can evaluate different aggregation methods via established axioms, examining whether these methods meet or fail well-known standards. We demonstrate that both the Bradley-Terry-Luce Model and its broad generalizations fail to meet basic axioms. In response, we develop novel rules for learning reward functions with strong axiomatic guarantees. A key innovation from the standpoint of social choice is that our problem has a linear structure, which greatly restricts the space of feasible rules and leads to a new paradigm that we call linear social choice.
Two-Sided Matching Meets Fair Division
Jul 15, 2021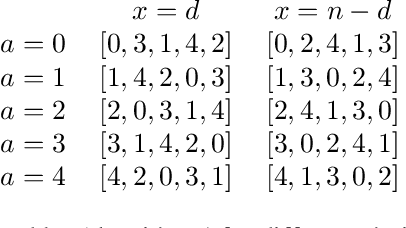
We introduce a new model for two-sided matching which allows us to borrow popular fairness notions from the fair division literature such as envy-freeness up to one good and maximin share guarantee. In our model, each agent is matched to multiple agents on the other side over whom she has additive preferences. We demand fairness for each side separately, giving rise to notions such as double envy-freeness up to one match (DEF1) and double maximin share guarantee (DMMS). We show that (a slight strengthening of) DEF1 cannot always be achieved, but in the special case where both sides have identical preferences, the round-robin algorithm with a carefully designed agent ordering achieves it. In contrast, DMMS cannot be achieved even when both sides have identical preferences.
Fair Algorithms for Multi-Agent Multi-Armed Bandits
Jul 13, 2020We propose a multi-agent variant of the classical multi-armed bandit problem, in which there are N agents and K arms, and pulling an arm generates a (possibly different) stochastic reward to each agent. Unlike the classical multi-armed bandit problem, the goal is not to learn the "best arm", as each agent may perceive a different arm as best for her. Instead, we seek to learn a fair distribution over arms. Drawing on a long line of research in economics and computer science, we use the Nash social welfare as our notion of fairness. We design multi-agent variants of three classic multi-armed bandit algorithms, and show that they achieve sublinear regret, now measured in terms of the Nash social welfare.