 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Reachability for Safe Control in Unknown Environments
Feb 03, 2026Designing provably safe control is a core problem in trustworthy autonomy. However, most prior work in this regard assumes either that the system dynamics are known or deterministic, or that the state and action space are finite, significantly limiting application scope. We address this limitation by developing a probabilistic verification framework for unknown dynamical systems which combines conformal prediction with reachability analysis. In particular, we use conformal prediction to obtain valid uncertainty intervals for the unknown dynamics at each time step, with reachability then verifying whether safety is maintained within the conformal uncertainty bounds. Next, we develop an algorithmic approach for training control policies that optimize nominal reward while also maximizing the planning horizon with sound probabilistic safety guarantees. We evaluate the proposed approach in seven safe control settings spanning four domains -- cartpole, lane following, drone control, and safe navigation -- for both affine and nonlinear safety specifications. Our experiments show that the policies we learn achieve the strongest provable safety guarantees while still maintaining high average reward.
Verified Safe Reinforcement Learning for Neural Network Dynamic Models
May 25, 2024


Learning reliably safe autonomous control is one of the core problems in trustworthy autonomy. However, training a controller that can be formally verified to be safe remains a major challenge. We introduce a novel approach for learning verified safe control policies in nonlinear neural dynamical systems while maximizing overall performance. Our approach aims to achieve safety in the sense of finite-horizon reachability proofs, and is comprised of three key parts. The first is a novel curriculum learning scheme that iteratively increases the verified safe horizon. The second leverages the iterative nature of gradient-based learning to leverage incremental verification, reusing information from prior verification runs. Finally, we learn multiple verified initial-state-dependent controllers, an idea that is especially valuable for more complex domains where learning a single universal verified safe controller is extremely challenging. Our experiments on five safe control problems demonstrate that our trained controllers can achieve verified safety over horizons that are as much as an order of magnitude longer than state-of-the-art baselines, while maintaining high reward, as well as a perfect safety record over entire episodes.
Axioms for AI Alignment from Human Feedback
May 23, 2024



In the context of reinforcement learning from human feedback (RLHF), the reward function is generally derived from maximum likelihood estimation of a random utility model based on pairwise comparisons made by humans. The problem of learning a reward function is one of preference aggregation that, we argue, largely falls within the scope of social choice theory. From this perspective, we can evaluate different aggregation methods via established axioms, examining whether these methods meet or fail well-known standards. We demonstrate that both the Bradley-Terry-Luce Model and its broad generalizations fail to meet basic axioms. In response, we develop novel rules for learning reward functions with strong axiomatic guarantees. A key innovation from the standpoint of social choice is that our problem has a linear structure, which greatly restricts the space of feasible rules and leads to a new paradigm that we call linear social choice.
Preference Poisoning Attacks on Reward Model Learning
Feb 02, 2024Learning utility, or reward, models from pairwise comparisons is a fundamental component in a number of application domains. These approaches inherently entail collecting preference information from people, with feedback often provided anonymously. Since preferences are subjective, there is no gold standard to compare against; yet, reliance of high-impact systems on preference learning creates a strong motivation for malicious actors to skew data collected in this fashion to their ends. We investigate the nature and extent of this vulnerability systematically by considering a threat model in which an attacker can flip a small subset of preference comparisons with the goal of either promoting or demoting a target outcome. First, we propose two classes of algorithmic approaches for these attacks: a principled gradient-based framework, and several variants of rank-by-distance methods. Next, we demonstrate the efficacy of best attacks in both these classes in successfully achieving malicious goals on datasets from three diverse domains: autonomous control, recommendation system, and textual prompt-response preference learning. We find that the best attacks are often highly successful, achieving in the most extreme case 100% success rate with only 0.3% of the data poisoned. However, which attack is best can vary significantly across domains, demonstrating the value of our comprehensive vulnerability analysis that involves several classes of attack algorithms. In addition, we observe that the simpler and more scalable rank-by-distance approaches are often competitive with the best, and on occasion significantly outperform gradient-based methods. Finally, we show that several state-of-the-art defenses against other classes of poisoning attacks exhibit, at best, limited efficacy in our setting.
On the Exploitability of Reinforcement Learning with Human Feedback for Large Language Models
Nov 16, 2023Reinforcement Learning with Human Feedback (RLHF) is a methodology designed to align Large Language Models (LLMs) with human preferences, playing an important role in LLMs alignment. Despite its advantages, RLHF relies on human annotators to rank the text, which can introduce potential security vulnerabilities if any adversarial annotator (i.e., attackers) manipulates the ranking score by up-ranking any malicious text to steer the LLM adversarially. To assess the red-teaming of RLHF against human preference data poisoning, we propose RankPoison, a poisoning attack method on candidates' selection of preference rank flipping to reach certain malicious behaviors (e.g., generating longer sequences, which can increase the computational cost). With poisoned dataset generated by RankPoison, we can perform poisoning attacks on LLMs to generate longer tokens without hurting the original safety alignment performance. Moreover, applying RankPoison, we also successfully implement a backdoor attack where LLMs can generate longer answers under questions with the trigger word. Our findings highlight critical security challenges in RLHF, underscoring the necessity for more robust alignment methods for LLMs.
Exact Verification of ReLU Neural Control Barrier Functions
Oct 13, 2023



Control Barrier Functions (CBFs) are a popular approach for safe control of nonlinear systems. In CBF-based control, the desired safety properties of the system are mapped to nonnegativity of a CBF, and the control input is chosen to ensure that the CBF remains nonnegative for all time. Recently, machine learning methods that represent CBFs as neural networks (neural control barrier functions, or NCBFs) have shown great promise due to the universal representability of neural networks. However, verifying that a learned CBF guarantees safety remains a challenging research problem. This paper presents novel exact conditions and algorithms for verifying safety of feedforward NCBFs with ReLU activation functions. The key challenge in doing so is that, due to the piecewise linearity of the ReLU function, the NCBF will be nondifferentiable at certain points, thus invalidating traditional safety verification methods that assume a smooth barrier function. We resolve this issue by leveraging a generalization of Nagumo's theorem for proving invariance of sets with nonsmooth boundaries to derive necessary and sufficient conditions for safety. Based on this condition, we propose an algorithm for safety verification of NCBFs that first decomposes the NCBF into piecewise linear segments and then solves a nonlinear program to verify safety of each segment as well as the intersections of the linear segments. We mitigate the complexity by only considering the boundary of the safe region and by pruning the segments with Interval Bound Propagation (IBP) and linear relaxation. We evaluate our approach through numerical studies with comparison to state-of-the-art SMT-based methods. Our code is available at https://github.com/HongchaoZhang-HZ/exactverif-reluncbf-nips23.
Neural Lyapunov Control for Discrete-Time Systems
May 11, 2023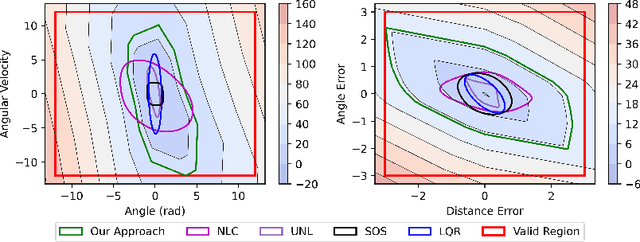



While ensuring stability for linear systems is well understood, it remains a major challenge for systems with nonlinear dynamics. A general approach in such cases is to leverage Lyapunov stability theory to compute a combination of a Lyapunov control function and an associated control policy. However, finding Lyapunov functions for general nonlinear systems is a challenging task. To address this challenge, several methods have been recently proposed that represent Lyapunov functions using neural networks. However, such approaches have been designed exclusively for continuous-time systems. We propose the first approach for learning neural Lyapunov control in discrete-time systems. Three key ingredients enable us to effectively learn provably stable control policies. The first is a novel mixed-integer linear programming approach for verifying the stability conditions in discrete-time systems. The second is a novel approach for computing sub-level sets which characterize the region of attraction. Finally, we rely on a heuristic gradient-based approach for quickly finding counterexamples to significantly speed up Lyapunov function learning. Our experiments on four standard benchmarks demonstrate that our approach significantly outperforms state-of-the-art baselines. For example, on the path tracking benchmark, we outperform recent neural Lyapunov control baselines by an order of magnitude in both running time and the size of the region of attraction, and on two of the four benchmarks (cartpole and PVTOL), ours is the first automated approach to return a provably stable controller.
Certifying Safety in Reinforcement Learning under Adversarial Perturbation Attacks
Dec 28, 2022
Function approximation has enabled remarkable advances in applying reinforcement learning (RL) techniques in environments with high-dimensional inputs, such as images, in an end-to-end fashion, mapping such inputs directly to low-level control. Nevertheless, these have proved vulnerable to small adversarial input perturbations. A number of approaches for improving or certifying robustness of end-to-end RL to adversarial perturbations have emerged as a result, focusing on cumulative reward. However, what is often at stake in adversarial scenarios is the violation of fundamental properties, such as safety, rather than the overall reward that combines safety with efficiency. Moreover, properties such as safety can only be defined with respect to true state, rather than the high-dimensional raw inputs to end-to-end policies. To disentangle nominal efficiency and adversarial safety, we situate RL in deterministic partially-observable Markov decision processes (POMDPs) with the goal of maximizing cumulative reward subject to safety constraints. We then propose a partially-supervised reinforcement learning (PSRL) framework that takes advantage of an additional assumption that the true state of the POMDP is known at training time. We present the first approach for certifying safety of PSRL policies under adversarial input perturbations, and two adversarial training approaches that make direct use of PSRL. Our experiments demonstrate both the efficacy of the proposed approach for certifying safety in adversarial environments, and the value of the PSRL framework coupled with adversarial training in improving certified safety while preserving high nominal reward and high-quality predictions of true state.
Robust Deep Reinforcement Learning through Bootstrapped Opportunistic Curriculum
Jun 21, 2022
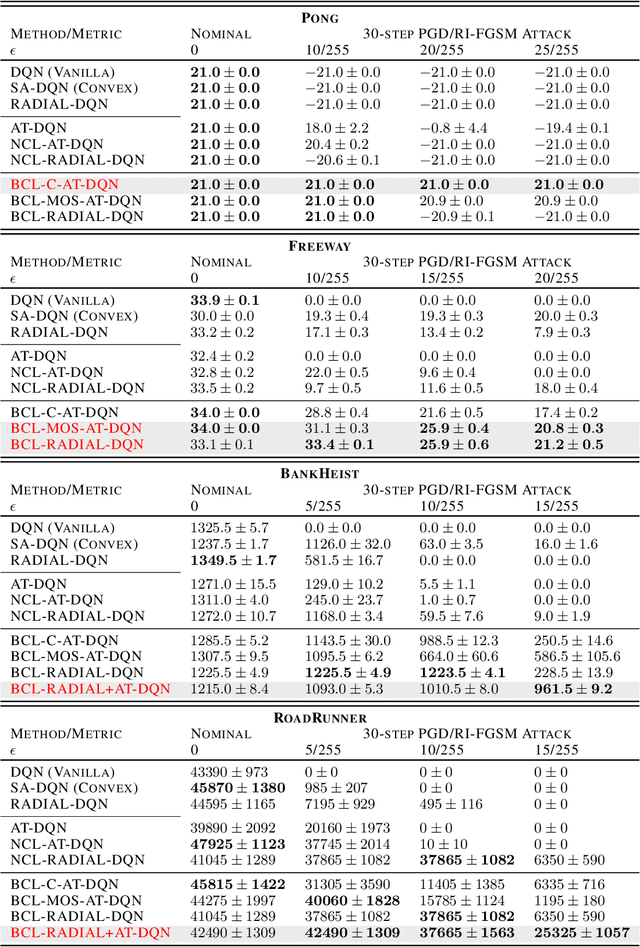
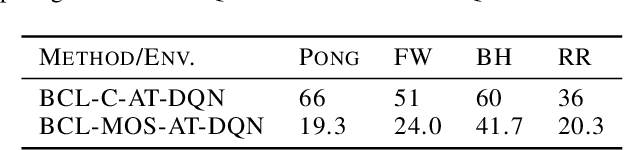

Despite considerable advances in deep reinforcement learning, it has been shown to be highly vulnerable to adversarial perturbations to state observations. Recent efforts that have attempted to improve adversarial robustness of reinforcement learning can nevertheless tolerate only very small perturbations, and remain fragile as perturbation size increases. We propose Bootstrapped Opportunistic Adversarial Curriculum Learning (BCL), a novel flexible adversarial curriculum learning framework for robust reinforcement learning. Our framework combines two ideas: conservatively bootstrapping each curriculum phase with highest quality solutions obtained from multiple runs of the previous phase, and opportunistically skipping forward in the curriculum. In our experiments we show that the proposed BCL framework enables dramatic improvements in robustness of learned policies to adversarial perturbations. The greatest improvement is for Pong, where our framework yields robustness to perturbations of up to 25/255; in contrast, the best existing approach can only tolerate adversarial noise up to 5/255. Our code is available at: https://github.com/jlwu002/BCL.
Learning Generative Deception Strategies in Combinatorial Masking Games
Sep 23, 2021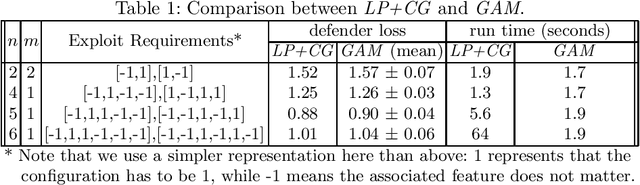
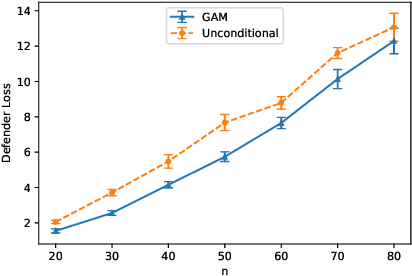
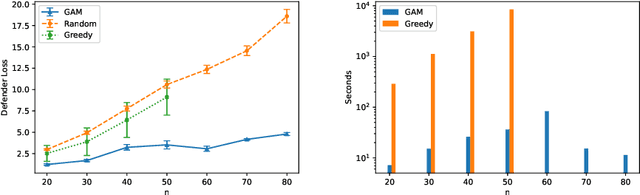
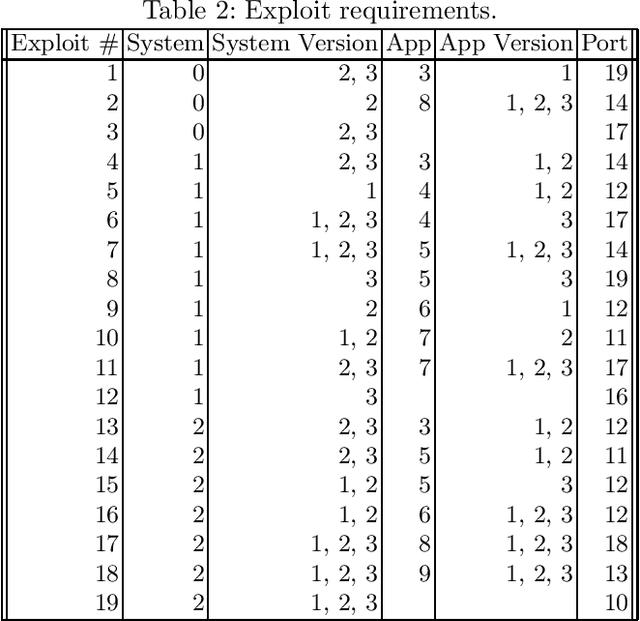
Deception is a crucial tool in the cyberdefence repertoire, enabling defenders to leverage their informational advantage to reduce the likelihood of successful attacks. One way deception can be employed is through obscuring, or masking, some of the information about how systems are configured, increasing attacker's uncertainty about their targets. We present a novel game-theoretic model of the resulting defender-attacker interaction, where the defender chooses a subset of attributes to mask, while the attacker responds by choosing an exploit to execute. The strategies of both players have combinatorial structure with complex informational dependencies, and therefore even representing these strategies is not trivial. First, we show that the problem of computing an equilibrium of the resulting zero-sum defender-attacker game can be represented as a linear program with a combinatorial number of system configuration variables and constraints, and develop a constraint generation approach for solving this problem. Next, we present a novel highly scalable approach for approximately solving such games by representing the strategies of both players as neural networks. The key idea is to represent the defender's mixed strategy using a deep neural network generator, and then using alternating gradient-descent-ascent algorithm, analogous to the training of Generative Adversarial Networks. Our experiments, as well as a case study, demonstrate the efficacy of the proposed approach.