 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial-Time Relational Probabilistic Inference in Open Universes
May 07, 2025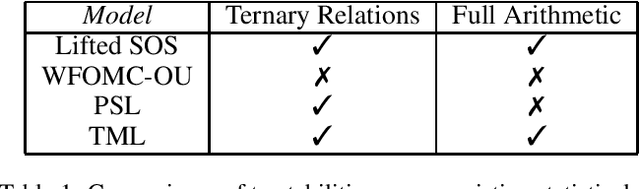
Reasoning under uncertainty is a fundamental challenge in Artificial Intelligence. As with most of these challenges, there is a harsh dilemma between the expressive power of the language used, and the tractability of the computational problem posed by reasoning. Inspired by human reasoning, we introduce a method of first-order relational probabilistic inference that satisfies both criteria, and can handle hybrid (discrete and continuous) variables. Specifically, we extend sum-of-squares logic of expectation to relational settings, demonstrating that lifted reasoning in the bounded-degree fragment for knowledge bases of bounded quantifier rank can be performed in polynomial time, even with an a priori unknown and/or countably infinite set of objects. Crucially, our notion of tractability is framed in proof-theoretic terms, which extends beyond the syntactic properties of the language or queries. We are able to derive the tightest bounds provable by proofs of a given degree and size and establish completeness in our sum-of-squares refutations for fixed degrees.
Axioms for AI Alignment from Human Feedback
May 23, 2024



In the context of reinforcement learning from human feedback (RLHF), the reward function is generally derived from maximum likelihood estimation of a random utility model based on pairwise comparisons made by humans. The problem of learning a reward function is one of preference aggregation that, we argue, largely falls within the scope of social choice theory. From this perspective, we can evaluate different aggregation methods via established axioms, examining whether these methods meet or fail well-known standards. We demonstrate that both the Bradley-Terry-Luce Model and its broad generalizations fail to meet basic axioms. In response, we develop novel rules for learning reward functions with strong axiomatic guarantees. A key innovation from the standpoint of social choice is that our problem has a linear structure, which greatly restricts the space of feasible rules and leads to a new paradigm that we call linear social choice.
Learning Linear Utility Functions From Pairwise Comparison Queries
May 07, 2024
We study learnability of linear utility functions from pairwise comparison queries. In particular, we consider two learning objectives. The first objective is to predict out-of-sample responses to pairwise comparisons, whereas the second is to approximately recover the true parameters of the utility function. We show that in the passive learning setting, linear utilities are efficiently learnable with respect to the first objective, both when query responses are uncorrupted by noise, and under Tsybakov noise when the distributions are sufficiently "nice". In contrast, we show that utility parameters are not learnable for a large set of data distributions without strong modeling assumptions, even when query responses are noise-free. Next, we proceed to analyze the learning problem in an active learning setting. In this case, we show that even the second objective is efficiently learnable, and present algorithms for both the noise-free and noisy query response settings. Our results thus exhibit a qualitative learnability gap between passive and active learning from pairwise preference queries, demonstrating the value of the ability to select pairwise queries for utility learning.