 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Bandit Whisperer: Communication Learning for Restless Bandits
Paper and Code
Aug 11, 2024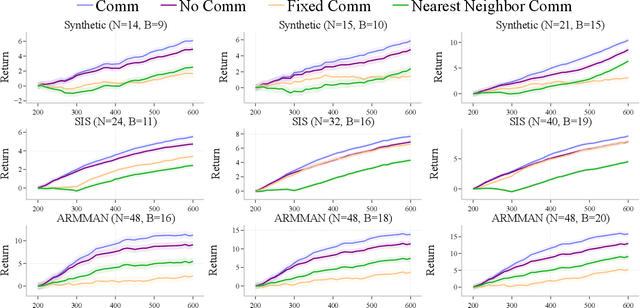
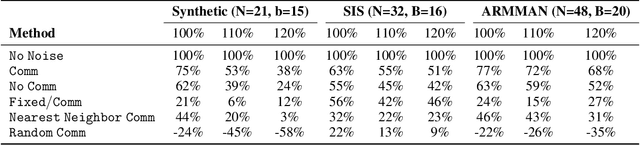
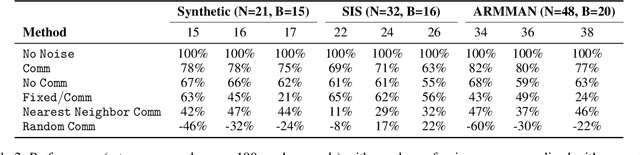
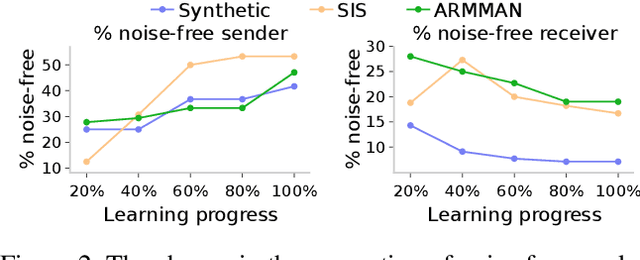
Applying Reinforcement Learning (RL) to Restless Multi-Arm Bandits (RMABs) offers a promising avenue for addressing allocation problems with resource constraints and temporal dynamics. However, classic RMAB models largely overlook the challenges of (systematic) data errors - a common occurrence in real-world scenarios due to factors like varying data collection protocols and intentional noise for differential privacy. We demonstrate that conventional RL algorithms used to train RMABs can struggle to perform well in such settings. To solve this problem, we propose the first communication learning approach in RMABs, where we study which arms, when involved in communication, are most effective in mitigating the influence of such systematic data errors. In our setup, the arms receive Q-function parameters from similar arms as messages to guide behavioral policies, steering Q-function updates. We learn communication strategies by considering the joint utility of messages across all pairs of arms and using a Q-network architecture that decomposes the joint utility. Both theoretical and empirical evidence validate the effectiveness of our method in significantly improving RMAB performance across diverse problems.