 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydra-Nav: Object Navigation via Adaptive Dual-Process Reasoning
Feb 10, 2026While large vision-language models (VLMs) show promise for object goal navigation, current methods still struggle with low success rates and inefficient localization of unseen objects--failures primarily attributed to weak temporal-spatial reasoning. Meanwhile, recent attempts to inject reasoning into VLM-based agents improve success rates but incur substantial computational overhead. To address both the ineffectiveness and inefficiency of existing approaches, we introduce Hydra-Nav, a unified VLM architecture that adaptively switches between a deliberative slow system for analyzing exploration history and formulating high-level plans, and a reactive fast system for efficient execution. We train Hydra-Nav through a three-stage curriculum: (i) spatial-action alignment to strengthen trajectory planning, (ii) memory-reasoning integration to enhance temporal-spatial reasoning over long-horizon exploration, and (iii) iterative rejection fine-tuning to enable selective reasoning at critical decision points. Extensive experiments demonstrate that Hydra-Nav achieves state-of-the-art performance on the HM3D, MP3D, and OVON benchmarks, outperforming the second-best methods by 11.1%, 17.4%, and 21.2%, respectively. Furthermore, we introduce SOT (Success weighted by Operation Time), a new metric to measure search efficiency across VLMs with varying reasoning intensity. Results show that adaptive reasoning significantly enhances search efficiency over fixed-frequency baselines.
ROMA: Real-time Omni-Multimodal Assistant with Interactive Streaming Understanding
Jan 15, 2026Recent Omni-multimodal Large Language Models show promise in unified audio, vision, and text modeling. However, streaming audio-video understanding remains challenging, as existing approaches suffer from disjointed capabilities: they typically exhibit incomplete modality support or lack autonomous proactive monitoring. To address this, we present ROMA, a real-time omni-multimodal assistant for unified reactive and proactive interaction. ROMA processes continuous inputs as synchronized multimodal units, aligning dense audio with discrete video frames to handle granularity mismatches. For online decision-making, we introduce a lightweight speak head that decouples response initiation from generation to ensure precise triggering without task conflict. We train ROMA with a curated streaming dataset and a two-stage curriculum that progressively optimizes for streaming format adaptation and proactive responsiveness. To standardize the fragmented evaluation landscape, we reorganize diverse benchmarks into a unified suite covering both proactive (alert, narration) and reactive (QA) settings. Extensive experiments across 12 benchmarks demonstrate ROMA achieves state-of-the-art performance on proactive tasks while competitive in reactive settings, validating its robustness in unified real-time omni-multimodal understanding.
Learning from Mistakes: Negative Reasoning Samples Enhance Out-of-Domain Generalization
Jan 08, 2026Supervised fine-tuning (SFT) on chain-of-thought (CoT) trajectories demonstrations is a common approach for enabling reasoning in large language models. Standard practices typically only retain trajectories with correct final answers (positives) while ignoring the rest (negatives). We argue that this paradigm discards substantial supervision and exacerbates overfitting, limiting out-of-domain (OOD) generalization. Specifically, we surprisingly find that incorporating negative trajectories into SFT yields substantial OOD generalization gains over positive-only training, as these trajectories often retain valid intermediate reasoning despite incorrect final answers. To understand this effect in depth, we systematically analyze data, training dynamics, and inference behavior, identifying 22 recurring patterns in negative chains that serve a dual role: they moderate loss descent to mitigate overfitting during training and boost policy entropy by 35.67% during inference to facilitate exploration. Motivated by these observations, we further propose Gain-based LOss Weighting (GLOW), an adaptive, sample-aware scheme that exploits such distinctive training dynamics by rescaling per-sample loss based on inter-epoch progress. Empirically, GLOW efficiently leverages unfiltered trajectories, yielding a 5.51% OOD gain over positive-only SFT on Qwen2.5-7B and boosting MMLU from 72.82% to 76.47% as an RL initialization.
AREE-Based Decoupled Design of Hybrid Beamformers in mmWave XL-MIMO Systems
Jul 03, 2025



Hybrid beamforming has been widely employed in mmWave communications such as vehicular-to-everything (V2X) scenarios, as a compromise between hardware complexity and spectral efficiency. However, the inherent coupling between analog and digital precoders in hybrid array architecture significantly limits the computational and spectral efficiency of existing algorithms. To address this issue, we propose an alternating residual error elimination (AREE) algorithm, which decomposes the hybrid beamforming problem into two low-dimensional subproblems, each exhibiting a favorable matrix structure that enables effective decoupling of analog and digital precoders from the matrix product formulation. These subproblems iteratively eliminate each other's residual errors, driving the original problem toward the optimal hybrid beamforming performance. The proposed initialization ensures rapid convergence, while a low-complexity geometric channel SVD algorithm is developed by transforming the high-dimensional sparse channel into a low-dimensional equivalent, thereby simplifying the derivation of subproblems. Simulation results demonstrate that the AREE algorithm effectively decouples analog and digital precoders with low complexity, achieves fast convergence, and offers higher spectral efficiency than existing beamforming methods.
Enhancing Decision-Making of Large Language Models via Actor-Critic
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable advancements in natural language processing tasks, yet they encounter challenges in complex decision-making scenarios that require long-term reasoning and alignment with high-level objectives. Existing methods either rely on short-term auto-regressive action generation or face limitations in accurately simulating rollouts and assessing outcomes, leading to sub-optimal decisions. This paper introduces a novel LLM-based Actor-Critic framework, termed LAC, that effectively improves LLM policies with long-term action evaluations in a principled and scalable way. Our approach addresses two key challenges: (1) extracting robust action evaluations by computing Q-values via token logits associated with positive/negative outcomes, enhanced by future trajectory rollouts and reasoning; and (2) enabling efficient policy improvement through a gradient-free mechanism. Experiments across diverse environments -- including high-level decision-making (ALFWorld), low-level action spaces (BabyAI-Text), and large action spaces (WebShop) -- demonstrate the framework's generality and superiority over state-of-the-art methods. Notably, our approach achieves competitive performance using 7B/8B parameter LLMs, even outperforming baseline methods employing GPT-4 in complex tasks. These results underscore the potential of integrating structured policy optimization with LLMs' intrinsic knowledge to advance decision-making capabilities in multi-step environments.
Policy-to-Language: Train LLMs to Explain Decisions with Flow-Matching Generated Rewards
Feb 18, 2025As humans increasingly share environments with diverse agents powered by RL, LLMs, and beyond, the ability to explain their policies in natural language will be vital for reliable coexistence. In this paper, we build a model-agnostic explanation generator based on an LLM. The technical novelty is that the rewards for training this LLM are generated by a generative flow matching model. This model has a specially designed structure with a hidden layer merged with an LLM to harness the linguistic cues of explanations into generating appropriate rewards. Experiments on both RL and LLM tasks demonstrate that our method can generate dense and effective rewards while saving on expensive human feedback; it thus enables effective explanations and even improves the accuracy of the decisions in original tasks.
On Diffusion Models for Multi-Agent Partial Observability: Shared Attractors, Error Bounds, and Composite Flow
Oct 17, 2024



Multiagent systems grapple with partial observability (PO), and the decentralized POMDP (Dec-POMDP) model highlights the fundamental nature of this challenge. Whereas recent approaches to address PO have appealed to deep learning models, providing a rigorous understanding of how these models and their approximation errors affect agents' handling of PO and their interactions remain a challenge. In addressing this challenge, we investigate reconstructing global states from local action-observation histories in Dec-POMDPs using diffusion models. We first find that diffusion models conditioned on local history represent possible states as stable fixed points. In collectively observable (CO) Dec-POMDPs, individual diffusion models conditioned on agents' local histories share a unique fixed point corresponding to the global state, while in non-CO settings, the shared fixed points yield a distribution of possible states given joint history. We further find that, with deep learning approximation errors, fixed points can deviate from true states and the deviation is negatively correlated to the Jacobian rank. Inspired by this low-rank property, we bound the deviation by constructing a surrogate linear regression model that approximates the local behavior of diffusion models. With this bound, we propose a composite diffusion process iterating over agents with theoretical convergence guarantees to the true state.
Underwater Acoustic Signal Denoising Algorithms: A Survey of the State-of-the-art
Jul 18, 2024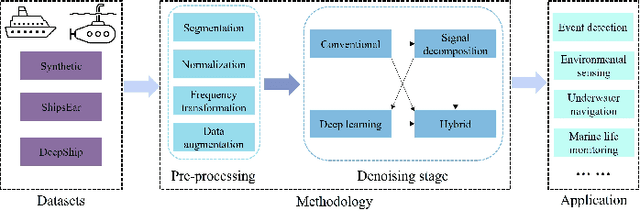
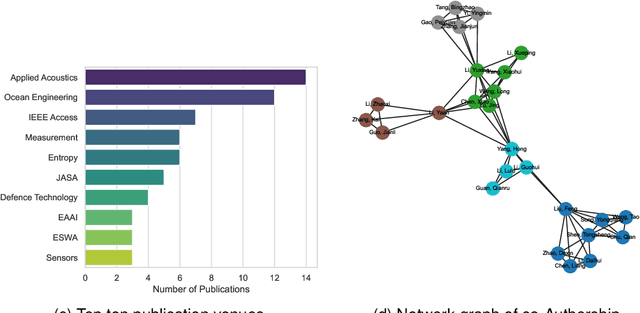

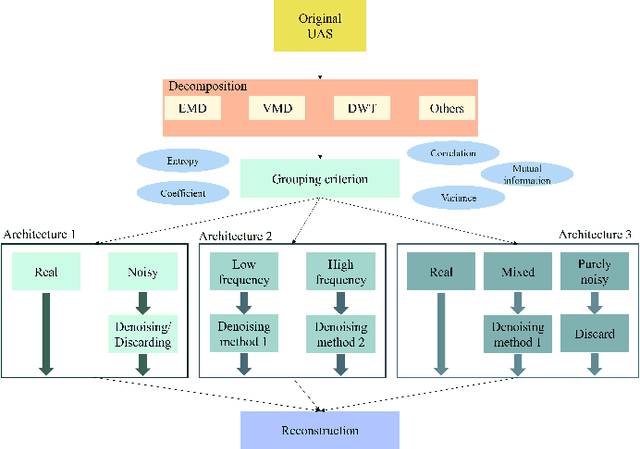
This paper comprehensively reviews recent advances in underwater acoustic signal denoising, an area critical for improving the reliability and clarity of underwater communication and monitoring systems. Despite significant progress in the field, the complex nature of underwater environments poses unique challenges that complicate the denoising process. We begin by outlining the fundamental challenges associated with underwater acoustic signal processing, including signal attenuation, noise variability, and the impact of environmental factors. The review then systematically categorizes and discusses various denoising algorithms, such as conventional, decomposition-based, and learning-based techniques, highlighting their applications, advantages, and limitations. Evaluation metrics and experimental datasets are also reviewed. The paper concludes with a list of open questions and recommendations for future research directions, emphasizing the need for developing more robust denoising techniques that can adapt to the dynamic underwater acoustic environment.
Leveraging Hyperbolic Embeddings for Coarse-to-Fine Robot Design
Nov 02, 2023



Multi-cellular robot design aims to create robots comprised of numerous cells that can be efficiently controlled to perform diverse tasks. Previous research has demonstrated the ability to generate robots for various tasks, but these approaches often optimize robots directly in the vast design space, resulting in robots with complicated morphologies that are hard to control. In response, this paper presents a novel coarse-to-fine method for designing multi-cellular robots. Initially, this strategy seeks optimal coarse-grained robots and progressively refines them. To mitigate the challenge of determining the precise refinement juncture during the coarse-to-fine transition, we introduce the Hyperbolic Embeddings for Robot Design (HERD) framework. HERD unifies robots of various granularity within a shared hyperbolic space and leverages a refined Cross-Entropy Method for optimization. This framework enables our method to autonomously identify areas of exploration in hyperbolic space and concentrate on regions demonstrating promise. Finally, the extensive empirical studies on various challenging tasks sourced from EvoGym show our approach's superior efficiency and generalization capability.
Symmetry-Aware Robot Design with Structured Subgroups
May 31, 2023



Robot design aims at learning to create robots that can be easily controlled and perform tasks efficiently. Previous works on robot design have proven its ability to generate robots for various tasks. However, these works searched the robots directly from the vast design space and ignored common structures, resulting in abnormal robots and poor performance. To tackle this problem, we propose a Symmetry-Aware Robot Design (SARD) framework that exploits the structure of the design space by incorporating symmetry searching into the robot design process. Specifically, we represent symmetries with the subgroups of the dihedral group and search for the optimal symmetry in structured subgroups. Then robots are designed under the searched symmetry. In this way, SARD can design efficient symmetric robots while covering the original design space, which is theoretically analyzed. We further empirically evaluate SARD on various tasks, and the results show its superior efficiency and generalizability.