 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient-LVSM: Faster, Cheaper, and Better Large View Synthesis Model via Decoupled Co-Refinement Attention
Feb 06, 2026Feedforward models for novel view synthesis (NVS) have recently advanced by transformer-based methods like LVSM, using attention among all input and target views. In this work, we argue that its full self-attention design is suboptimal, suffering from quadratic complexity with respect to the number of input views and rigid parameter sharing among heterogeneous tokens. We propose Efficient-LVSM, a dual-stream architecture that avoids these issues with a decoupled co-refinement mechanism. It applies intra-view self-attention for input views and self-then-cross attention for target views, eliminating unnecessary computation. Efficient-LVSM achieves 29.86 dB PSNR on RealEstate10K with 2 input views, surpassing LVSM by 0.2 dB, with 2x faster training convergence and 4.4x faster inference speed. Efficient-LVSM achieves state-of-the-art performance on multiple benchmarks, exhibits strong zero-shot generalization to unseen view counts, and enables incremental inference with KV-cache, thanks to its decoupled designs.
Interleave-VLA: Enhancing Robot Manipulation with Interleaved Image-Text Instructions
May 04, 2025Vision-Language-Action (VLA) models have shown great promise for generalist robotic manipulation in the physical world. However, existing models are restricted to robot observations and text-only instructions, lacking the flexibility of interleaved multimodal instructions enabled by recent advances in foundation models in the digital world. In this paper, we present Interleave-VLA, the first framework capable of comprehending interleaved image-text instructions and directly generating continuous action sequences in the physical world. It offers a flexible, model-agnostic paradigm that extends state-of-the-art VLA models with minimal modifications and strong zero-shot generalization. A key challenge in realizing Interleave-VLA is the absence of large-scale interleaved embodied datasets. To bridge this gap, we develop an automatic pipeline that converts text-only instructions from real-world datasets in Open X-Embodiment into interleaved image-text instructions, resulting in the first large-scale real-world interleaved embodied dataset with 210k episodes. Through comprehensive evaluation on simulation benchmarks and real-robot experiments, we demonstrate that Interleave-VLA offers significant benefits: 1) it improves out-of-domain generalization to unseen objects by 2-3x compared to state-of-the-art baselines, 2) supports flexible task interfaces, and 3) handles diverse user-provided image instructions in a zero-shot manner, such as hand-drawn sketches. We further analyze the factors behind Interleave-VLA's strong zero-shot performance, showing that the interleaved paradigm effectively leverages heterogeneous datasets and diverse instruction images, including those from the Internet, which demonstrates strong potential for scaling up. Our model and dataset will be open-sourced.
GraphEval: A Lightweight Graph-Based LLM Framework for Idea Evaluation
Mar 16, 2025The powerful capabilities of Large Language Models (LLMs) have led to their growing use in evaluating human-generated content, particularly in evaluating research ideas within academic settings. Existing solutions primarily rely on prompt-based LLM methods or fine-tuned lightweight language models for idea evaluation. However, these methods are often unstable and struggle to comprehend the complex semantic information embedded in the ideas, impeding their ability to perform high-quality evaluations. To address the above challenges, we propose GraphEval, a lightweight graph-based LLM framework for idea evaluation. Our insight is that a complex idea can be broken down into comprehensible viewpoint nodes using prompts from small LLMs. These viewpoint nodes can then be linked together through edges created from LLM-based relation extraction and/or BERT similarity scores. The created viewpoint-graph can be used to conveniently propagate scores across view-nodes to improve the robustness of the idea evaluations. In particular, we propose two lightweight graph-based methods for idea evaluation: (1) GraphEval-LP: a training-free label propagation algorithm that propagates evaluation scores from known view-nodes to unknown nodes; (2) GraphEval-GNN: a Graph Neural Networks (GNN) that is trained to predict the evaluation scores given the observed graph with minimal computation resources. Moreover, to overcome LLM's limitation in objectively assessing the novelty of ideas, we further propose a novelty detection model to GraphEval-GNN to enhance its capability in judging idea novelty. Experiments on two datasets show GraphEval improves F1 scores by at least 14% with low computation and API costs. Additionally, GraphEval can effectively detect plagiarized ideas.
On the number of modes of Gaussian kernel density estimators
Dec 12, 2024



We consider the Gaussian kernel density estimator with bandwidth $\beta^{-\frac12}$ of $n$ iid Gaussian samples. Using the Kac-Rice formula and an Edgeworth expansion, we prove that the expected number of modes on the real line scales as $\Theta(\sqrt{\beta\log\beta})$ as $\beta,n\to\infty$ provided $n^c\lesssim \beta\lesssim n^{2-c}$ for some constant $c>0$. An impetus behind this investigation is to determine the number of clusters to which Transformers are drawn in a metastable state.
ProAgent: Building Proactive Cooperative AI with Large Language Models
Aug 28, 2023


Building AIs with adaptive behaviors in human-AI cooperation stands as a pivotal focus in AGI research. Current methods for developing cooperative agents predominantly rely on learning-based methods, where policy generalization heavily hinges on past interactions with specific teammates. These approaches constrain the agent's capacity to recalibrate its strategy when confronted with novel teammates. We propose \textbf{ProAgent}, a novel framework that harnesses large language models (LLMs) to fashion a \textit{pro}active \textit{agent} empowered with the ability to anticipate teammates' forthcoming decisions and formulate enhanced plans for itself. ProAgent excels at cooperative reasoning with the capacity to dynamically adapt its behavior to enhance collaborative efforts with teammates. Moreover, the ProAgent framework exhibits a high degree of modularity and interpretability, facilitating seamless integration to address a wide array of coordination scenarios. Experimental evaluations conducted within the framework of \textit{Overcook-AI} unveil the remarkable performance superiority of ProAgent, outperforming five methods based on self-play and population-based training in cooperation with AI agents. Further, when cooperating with human proxy models, its performance exhibits an average improvement exceeding 10\% compared to the current state-of-the-art, COLE. The advancement was consistently observed across diverse scenarios involving interactions with both AI agents of varying characteristics and human counterparts. These findings inspire future research for human-robot collaborations. For a hands-on demonstration, please visit \url{https://pku-proagent.github.io}.
Randomly Initialized One-Layer Neural Networks Make Data Linearly Separable
May 24, 2022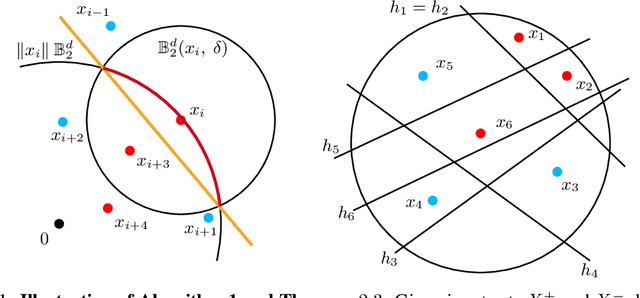
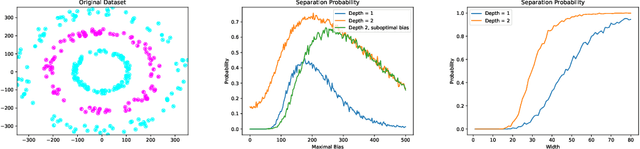
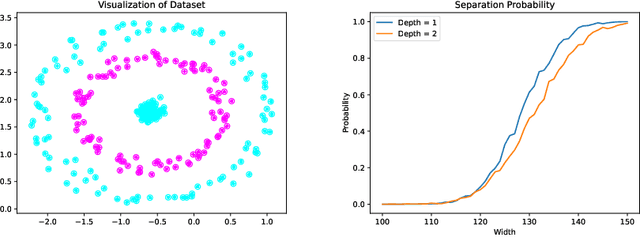
Recently, neural networks have been shown to perform exceptionally well in transforming two arbitrary sets into two linearly separable sets. Doing this with a randomly initialized neural network is of immense interest because the associated computation is cheaper than using fully trained networks. In this paper, we show that, with sufficient width, a randomly initialized one-layer neural network transforms two sets into two linearly separable sets with high probability. Furthermore, we provide explicit bounds on the required width of the neural network for this to occur. Our first bound is exponential in the input dimension and polynomial in all other parameters, while our second bound is independent of the input dimension, thereby overcoming the curse of dimensionality. We also perform an experimental study comparing the separation capacity of randomly initialized one-layer and two-layer neural networks. With correctly chosen biases, our study shows for low-dimensional data, the two-layer neural network outperforms the one-layer network. However, the opposite is observed for higher-dimensional data.