 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinetic theory for Transformers and the lost-in-the-middle phenomenon
May 09, 2026We study causal self-attention dynamics -- a toy model for decoder Transformers -- which we interpret as a non-exchangeable interacting particle system. Adapting cumulant expansions to the triangular causal dependency structure of the model, and appealing to non-hierarchical methods to estimate correlations using Glauber calculus, we prove a quantitative mean-field limit result and a next-order characterization of correlations. For iid uniformly distributed tokens, the limiting correlation equation can be solved in closed form and we obtain a rigorous explanation of the empirically observed \emph{lost-in-the-middle} phenomenon: the token retrieval profile, as a function of the source position in the prompt, is $\mathsf{U}$-shaped, with primacy, recency, and a unique interior minimum under an explicit smallness condition.
Homogenized Transformers
Apr 02, 2026We study a random model of deep multi-head self-attention in which the weights are resampled independently across layers and heads, as at initialization of training. Viewing depth as a time variable, the residual stream defines a discrete-time interacting particle system on the unit sphere. We prove that, under suitable joint scalings of the depth, the residual step size, and the number of heads, this dynamics admits a nontrivial homogenized limit. Depending on the scaling, the limit is either deterministic or stochastic with common noise; in the mean-field regime, the latter leads to a stochastic nonlinear Fokker--Planck equation for the conditional law of a representative token. In the Gaussian setting, the limiting drift vanishes, making the homogenized dynamics explicit enough to study representation collapse. This yields quantitative trade-offs between dimension, context length, and temperature, and identifies regimes in which clustering can be mitigated.
Constructive conditional normalizing flows
Feb 09, 2026Motivated by applications in conditional sampling, given a probability measure $μ$ and a diffeomorphism $φ$, we consider the problem of simultaneously approximating $φ$ and the pushforward $φ_{\#}μ$ by means of the flow of a continuity equation whose velocity field is a perceptron neural network with piecewise constant weights. We provide an explicit construction based on a polar-like decomposition of the Lagrange interpolant of $φ$. The latter involves a compressible component, given by the gradient of a particular convex function, which can be realized exactly, and an incompressible component, which -- after approximating via permutations -- can be implemented through shear flows intrinsic to the continuity equation. For more regular maps $φ$ -- such as the Knöthe-Rosenblatt rearrangement -- we provide an alternative, probabilistic construction inspired by the Maurey empirical method, in which the number of discontinuities in the weights doesn't scale inversely with the ambient dimension.
Perceptrons and localization of attention's mean-field landscape
Jan 29, 2026The forward pass of a Transformer can be seen as an interacting particle system on the unit sphere: time plays the role of layers, particles that of token embeddings, and the unit sphere idealizes layer normalization. In some weight settings the system can even be seen as a gradient flow for an explicit energy, and one can make sense of the infinite context length (mean-field) limit thanks to Wasserstein gradient flows. In this paper we study the effect of the perceptron block in this setting, and show that critical points are generically atomic and localized on subsets of the sphere.
Constructive approximate transport maps with normalizing flows
Dec 26, 2024We study an approximate controllability problem for the continuity equation and its application to constructing transport maps with normalizing flows. Specifically, we construct time-dependent controls $\theta=(w, a, b)$ in the vector field $w(a^\top x + b)_+$ to approximately transport a known base density $\rho_{\mathrm{B}}$ to a target density $\rho_*$. The approximation error is measured in relative entropy, and $\theta$ are constructed piecewise constant, with bounds on the number of switches being provided. Our main result relies on an assumption on the relative tail decay of $\rho_*$ and $\rho_{\mathrm{B}}$, and provides hints on characterizing the reachable space of the continuity equation in relative entropy.
On the number of modes of Gaussian kernel density estimators
Dec 12, 2024



We consider the Gaussian kernel density estimator with bandwidth $\beta^{-\frac12}$ of $n$ iid Gaussian samples. Using the Kac-Rice formula and an Edgeworth expansion, we prove that the expected number of modes on the real line scales as $\Theta(\sqrt{\beta\log\beta})$ as $\beta,n\to\infty$ provided $n^c\lesssim \beta\lesssim n^{2-c}$ for some constant $c>0$. An impetus behind this investigation is to determine the number of clusters to which Transformers are drawn in a metastable state.
Measure-to-measure interpolation using Transformers
Nov 07, 2024



Transformers are deep neural network architectures that underpin the recent successes of large language models. Unlike more classical architectures that can be viewed as point-to-point maps, a Transformer acts as a measure-to-measure map implemented as specific interacting particle system on the unit sphere: the input is the empirical measure of tokens in a prompt and its evolution is governed by the continuity equation. In fact, Transformers are not limited to empirical measures and can in principle process any input measure. As the nature of data processed by Transformers is expanding rapidly, it is important to investigate their expressive power as maps from an arbitrary measure to another arbitrary measure. To that end, we provide an explicit choice of parameters that allows a single Transformer to match $N$ arbitrary input measures to $N$ arbitrary target measures, under the minimal assumption that every pair of input-target measures can be matched by some transport map.
Dynamic metastability in the self-attention model
Oct 09, 2024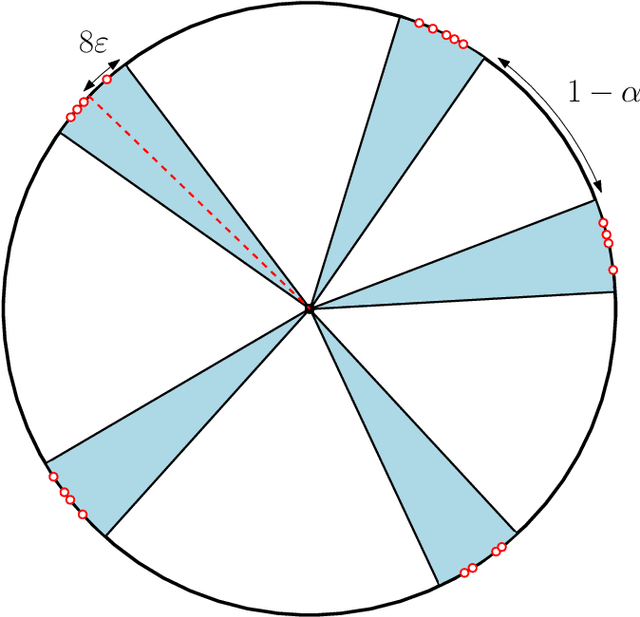

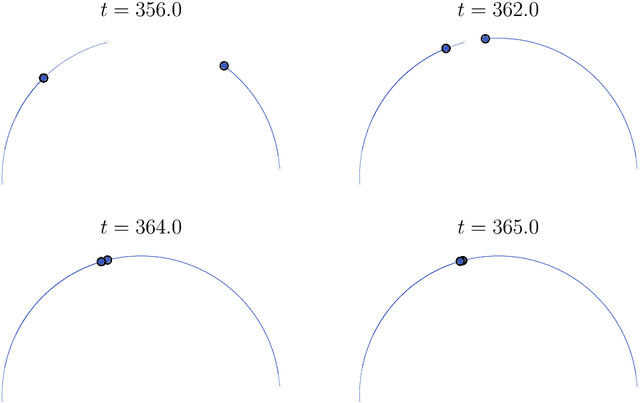

We consider the self-attention model - an interacting particle system on the unit sphere, which serves as a toy model for Transformers, the deep neural network architecture behind the recent successes of large language models. We prove the appearance of dynamic metastability conjectured in [GLPR23] - although particles collapse to a single cluster in infinite time, they remain trapped near a configuration of several clusters for an exponentially long period of time. By leveraging a gradient flow interpretation of the system, we also connect our result to an overarching framework of slow motion of gradient flows proposed by Otto and Reznikoff [OR07] in the context of coarsening and the Allen-Cahn equation. We finally probe the dynamics beyond the exponentially long period of metastability, and illustrate that, under an appropriate time-rescaling, the energy reaches its global maximum in finite time and has a staircase profile, with trajectories manifesting saddle-to-saddle-like behavior, reminiscent of recent works in the analysis of training dynamics via gradient descent for two-layer neural networks.
A mathematical perspective on Transformers
Dec 22, 2023



Transformers play a central role in the inner workings of large language models. We develop a mathematical framework for analyzing Transformers based on their interpretation as interacting particle systems, which reveals that clusters emerge in long time. Our study explores the underlying theory and offers new perspectives for mathematicians as well as computer scientists.
The emergence of clusters in self-attention dynamics
May 17, 2023



Viewing Transformers as interacting particle systems, we describe the geometry of learned representations when the weights are not time dependent. We show that particles, representing tokens, tend to cluster toward particular limiting objects as time tends to infinity. Cluster locations are determined by the initial tokens, confirming context-awareness of representations learned by Transformers. Using techniques from dynamical systems and partial differential equations, we show that the type of limiting object that emerges depends on the spectrum of the value matrix. Additionally, in the one-dimensional case we prove that the self-attention matrix converges to a low-rank Boolean matrix. The combination of these results mathematically confirms the empirical observation made by Vaswani et al. [VSP'17] that leaders appear in a sequence of tokens when processed by Transformers.