 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse approximation in learning via neural ODEs
Paper and Code

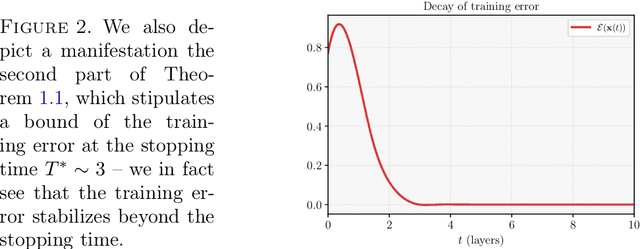

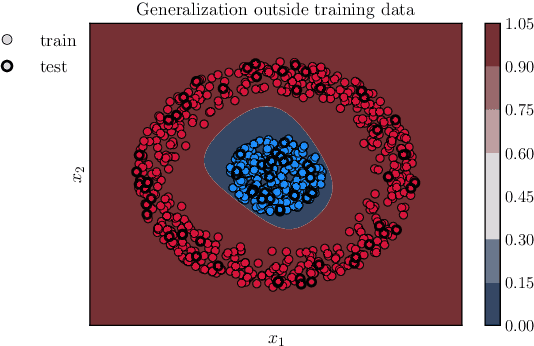
We consider the continuous-time, neural ordinary differential equation (neural ODE) perspective of deep supervised learning, and study the impact of the final time horizon $T$ in training. We focus on a cost consisting of an integral of the empirical risk over the time interval, and $L^1$--parameter regularization. Under homogeneity assumptions on the dynamics (typical for ReLU activations), we prove that any global minimizer is sparse, in the sense that there exists a positive stopping time $T^*$ beyond which the optimal parameters vanish. Moreover, under appropriate interpolation assumptions on the neural ODE, we provide quantitative estimates of the stopping time $T^\ast$, and of the training error of the trajectories at the stopping time. The latter stipulates a quantitative approximation property of neural ODE flows with sparse parameters. In practical terms, a shorter time-horizon in the training problem can be interpreted as considering a shallower residual neural network (ResNet), and since the optimal parameters are concentrated over a shorter time horizon, such a consideration may lower the computational cost of training without discarding relevant information.