 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructive interpolation and generalization rates for neural ODEs: a control perspective
May 30, 2026We study supervised regression with neural ODEs (NODEs) from a control-theoretic perspective to derive explicit population-risk bounds. We focus on a widely used class of non-autonomous models with constant parameters and explicit time dependence, which we call semi-autonomous NODEs (SA-NODEs). We constructively prove that SA-NODEs are capable of \emph{exact} interpolation of admissible finite datasets, and even satisfy a stronger property that we call \emph{simultaneous cell controllability} (SCC): their flows can map prescribed disjoint cells into arbitrarily small target balls. This property is the mechanism that upgrades interpolation into quantitative generalization, by allowing SA-NODEs to emulate piecewise-constant nonparametric estimators. Consequently, our risk bounds recover the rates of histogram and nearest-neighbor estimators, provided the network width satisfies a conservative scaling with the sample size. Numerical experiments show that trained SA-NODEs achieve competitive -- often lower -- test errors than these baselines. Finally, we show that the explicit time dependence is essential. Although two-layer autonomous NODEs can interpolate geometrically nondegenerate datasets, structural obstructions prevent them from achieving SCC. These limitations, further confirmed numerically, support the view that SA-NODEs provide a minimal effective architecture for learning.
Towards the Next Frontier of LLMs, Training on Private Data: A Cross-Domain Benchmark for Federated Fine-Tuning
May 13, 2026The recent success of large language models (LLMs) has been largely driven by vast public datasets. However, the next frontier for LLM development lies beyond public data. Much of the world's most valuable information is private, especially in highly regulated sectors such as healthcare and finance, where data include patient histories or customer communications. Unlocking this data could represent a major leap forward, enabling LLMs with deeper domain expertise and stronger real-world utility. Yet, these data cannot be shared because they are distributed across institutions and constrained by privacy, regulatory, and organizational barriers. Moreover, institutional datasets are typically non-independent and identically distributed (non-IID), differing across sites in population characteristics, data modalities, documentation patterns, and task-specific label distributions. In this paper, we demonstrate a practical approach to unlocking private and distributed institutional data for LLM adaptation through federated collaboration across data silos. Built on the Sherpa.ai Federated Learning platform, our framework enables nodes to jointly fine-tune a shared LLM without exchanging private data. We evaluate this approach through a cross-domain benchmark in healthcare and finance, using four closed-ended question answering and classification datasets: MedQA, MedMCQA, FPB, and FiQA-SA. We compare three parameter-efficient fine-tuning (PEFT) strategies-LoRA, QLoRA, and IA3-across pretrained backbones under non-IID settings reflecting institutional data heterogeneity. Our results show that federated fine-tuning performs close to centralized training and outperforms isolated single-institution learning. From a Green AI perspective, QLoRA and IA3 improve efficiency with limited accuracy degradation, supporting federated PEFT as a viable approach for adapting LLMs where data cannot be shared.
Sherpa.ai Privacy-Preserving Multi-Party Entity Alignment without Intersection Disclosure for Noisy Identifiers
Apr 21, 2026Federated Learning (FL) enables collaborative model training among multiple parties without centralizing raw data. There are two main paradigms in FL: Horizontal FL (HFL), where all participants share the same feature space but hold different samples, and Vertical FL (VFL), where parties possess complementary features for the same set of samples. A prerequisite for VFL training is privacy-preserving entity alignment (PPEA), which establishes a common index of samples across parties (alignment) without revealing which samples are shared between them. Conventional private set intersection (PSI) achieves alignment but leaks intersection membership, exposing sensitive relationships between datasets. The standard private set union (PSU) mitigates this risk by aligning on the union of identifiers rather than the intersection. However, existing approaches are often limited to two parties or lack support for typo-tolerant matching. In this paper, we introduce the Sherpa.ai multi-party PSU protocol for VFL, a PPEA method that hides intersection membership and enables both exact and noisy matching. The protocol generalizes two-party approaches to multiple parties with low communication overhead and offers two variants: an order-preserving version for exact alignment and an unordered version tolerant to typographical and formatting discrepancies. We prove correctness and privacy, analyze communication and computational (exponentiation) complexity, and formalize a universal index mapping from local records to a shared index space. This multi-party PSU offers a scalable, mathematically grounded protocol for PPEA in real-world VFL deployments, such as multi-institutional healthcare disease detection, collaborative risk modeling between banks and insurers, and cross-domain fraud detection between telecommunications and financial institutions, while preserving intersection privacy.
Fair feature attribution for multi-output prediction: a Shapley-based perspective
Feb 26, 2026In this article, we provide an axiomatic characterization of feature attribution for multi-output predictors within the Shapley framework. While SHAP explanations are routinely computed independently for each output coordinate, the theoretical necessity of this practice has remained unclear. By extending the classical Shapley axioms to vector-valued cooperative games, we establish a rigidity theorem showing that any attribution rule satisfying efficiency, symmetry, dummy player, and additivity must necessarily decompose component-wise across outputs. Consequently, any joint-output attribution rule must relax at least one of the classical Shapley axioms. This result identifies a previously unformalized structural constraint in Shapley-based interpretability, clarifying the precise scope of fairness-consistent explanations in multi-output learning. Numerical experiments on a biomedical benchmark illustrate that multi-output models can yield computational savings in training and deployment, while producing SHAP explanations that remain fully consistent with the component-wise structure imposed by the Shapley axioms.
Training Together, Diagnosing Better: Federated Learning for Collagen VI-Related Dystrophies
Dec 18, 2025The application of Machine Learning (ML) to the diagnosis of rare diseases, such as collagen VI-related dystrophies (COL6-RD), is fundamentally limited by the scarcity and fragmentation of available data. Attempts to expand sampling across hospitals, institutions, or countries with differing regulations face severe privacy, regulatory, and logistical obstacles that are often difficult to overcome. The Federated Learning (FL) provides a promising solution by enabling collaborative model training across decentralized datasets while keeping patient data local and private. Here, we report a novel global FL initiative using the Sherpa.ai FL platform, which leverages FL across distributed datasets in two international organizations for the diagnosis of COL6-RD, using collagen VI immunofluorescence microscopy images from patient-derived fibroblast cultures. Our solution resulted in an ML model capable of classifying collagen VI patient images into the three primary pathogenic mechanism groups associated with COL6-RD: exon skipping, glycine substitution, and pseudoexon insertion. This new approach achieved an F1-score of 0.82, outperforming single-organization models (0.57-0.75). These results demonstrate that FL substantially improves diagnostic utility and generalizability compared to isolated institutional models. Beyond enabling more accurate diagnosis, we anticipate that this approach will support the interpretation of variants of uncertain significance and guide the prioritization of sequencing strategies to identify novel pathogenic variants.
Federated Learning for Pediatric Pneumonia Detection: Enabling Collaborative Diagnosis Without Sharing Patient Data
Nov 12, 2025Early and accurate pneumonia detection from chest X-rays (CXRs) is clinically critical to expedite treatment and isolation, reduce complications, and curb unnecessary antibiotic use. Although artificial intelligence (AI) substantially improves CXR-based detection, development is hindered by globally distributed data, high inter-hospital variability, and strict privacy regulations (e.g., HIPAA, GDPR) that make centralization impractical. These constraints are compounded by heterogeneous imaging protocols, uneven data availability, and the costs of transferring large medical images across geographically dispersed sites. In this paper, we evaluate Federated Learning (FL) using the Sherpa.ai FL platform, enabling multiple hospitals (nodes) to collaboratively train a CXR classifier for pneumonia while keeping data in place and private. Using the Pediatric Pneumonia Chest X-ray dataset, we simulate cross-hospital collaboration with non-independent and non-identically distributed (non-IID) data, reproducing real-world variability across institutions and jurisdictions. Our experiments demonstrate that collaborative and privacy-preserving training across multiple hospitals via FL led to a dramatic performance improvement achieving 0.900 Accuracy and 0.966 ROC-AUC, corresponding to 47.5% and 50.0% gains over single-hospital models (0.610; 0.644), without transferring any patient CXR. These results indicate that FL delivers high-performing, generalizable, secure and private pneumonia detection across healthcare networks, with data kept local. This is especially relevant for rare diseases, where FL enables secure multi-institutional collaboration without data movement, representing a breakthrough for accelerating diagnosis and treatment development in low-data domains.
A PDE Perspective on Generative Diffusion Models
Nov 08, 2025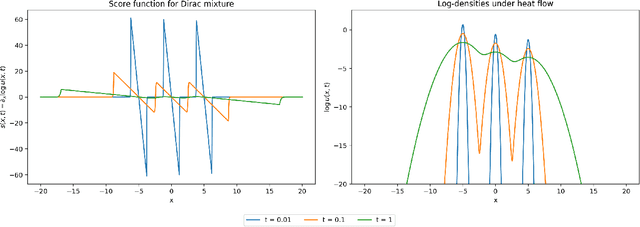
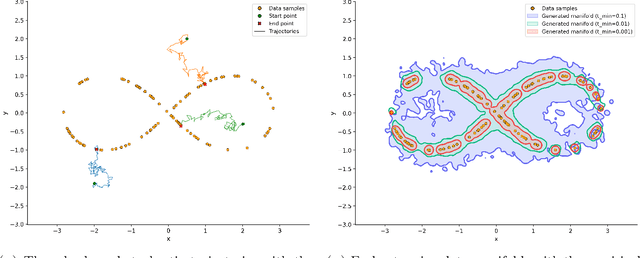
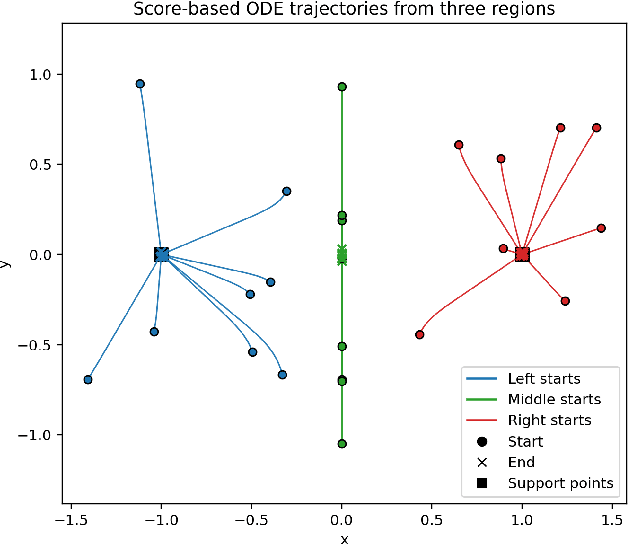
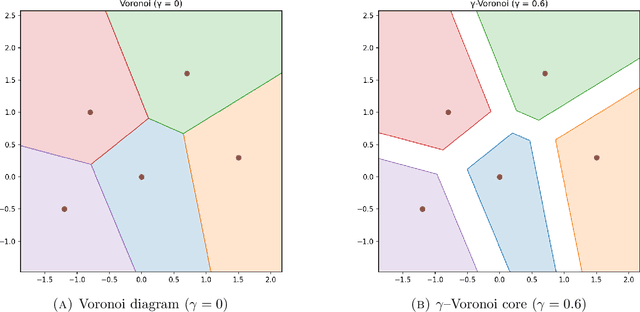
Score-based diffusion models have emerged as a powerful class of generative methods, achieving state-of-the-art performance across diverse domains. Despite their empirical success, the mathematical foundations of those models remain only partially understood, particularly regarding the stability and consistency of the underlying stochastic and partial differential equations governing their dynamics. In this work, we develop a rigorous partial differential equation (PDE) framework for score-based diffusion processes. Building on the Li--Yau differential inequality for the heat flow, we prove well-posedness and derive sharp $L^p$-stability estimates for the associated score-based Fokker--Planck dynamics, providing a mathematically consistent description of their temporal evolution. Through entropy stability methods, we further show that the reverse-time dynamics of diffusion models concentrate on the data manifold for compactly supported data distributions and a broad class of initialization schemes, with a concentration rate of order $\sqrt{t}$ as $t \to 0$. These results yield a theoretical guarantee that, under exact score guidance, diffusion trajectories return to the data manifold while preserving imitation fidelity. Our findings also provide practical insights for designing diffusion models, including principled criteria for score-function construction, loss formulation, and stopping-time selection. Altogether, this framework provides a quantitative understanding of the trade-off between generative capacity and imitation fidelity, bridging rigorous analysis and model design within a unified mathematical perspective.
Exact Sequence Classification with Hardmax Transformers
Feb 04, 2025



We prove that hardmax attention transformers perfectly classify datasets of $N$ labeled sequences in $\mathbb{R}^d$, $d\geq 2$. Specifically, given $N$ sequences with an arbitrary but finite length in $\mathbb{R}^d$, we construct a transformer with $\mathcal{O}(N)$ blocks and $\mathcal{O}(Nd)$ parameters perfectly classifying this dataset. Our construction achieves the best complexity estimate to date, independent of the length of the sequences, by innovatively alternating feed-forward and self-attention layers and by capitalizing on the clustering effect inherent to the latter. Our novel constructive method also uses low-rank parameter matrices within the attention mechanism, a common practice in real-life transformer implementations. Consequently, our analysis holds twofold significance: it substantially advances the mathematical theory of transformers and it rigorously justifies their exceptional real-world performance in sequence classification tasks.
Representation and Regression Problems in Neural Networks: Relaxation, Generalization, and Numerics
Dec 02, 2024



In this work, we address three non-convex optimization problems associated with the training of shallow neural networks (NNs) for exact and approximate representation, as well as for regression tasks. Through a mean-field approach, we convexify these problems and, applying a representer theorem, prove the absence of relaxation gaps. We establish generalization bounds for the resulting NN solutions, assessing their predictive performance on test datasets and, analyzing the impact of key hyperparameters on these bounds, propose optimal choices. On the computational side, we examine the discretization of the convexified problems and derive convergence rates. For low-dimensional datasets, these discretized problems are efficiently solvable using the simplex method. For high-dimensional datasets, we propose a sparsification algorithm that, combined with gradient descent for over-parameterized shallow NNs, yields effective solutions to the primal problems.
A Potential Game Perspective in Federated Learning
Nov 18, 2024Federated learning (FL) is an emerging paradigm for training machine learning models across distributed clients. Traditionally, in FL settings, a central server assigns training efforts (or strategies) to clients. However, from a market-oriented perspective, clients may independently choose their training efforts based on rational self-interest. To explore this, we propose a potential game framework where each client's payoff is determined by their individual efforts and the rewards provided by the server. The rewards are influenced by the collective efforts of all clients and can be modulated through a reward factor. Our study begins by establishing the existence of Nash equilibria (NEs), followed by an investigation of uniqueness in homogeneous settings. We demonstrate a significant improvement in clients' training efforts at a critical reward factor, identifying it as the optimal choice for the server. Furthermore, we prove the convergence of the best-response algorithm to compute NEs for our FL game. Finally, we apply the training efforts derived from specific NEs to a real-world FL scenario, validating the effectiveness of the identified optimal reward factor.