 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic metastability in the self-attention model
Paper and Code
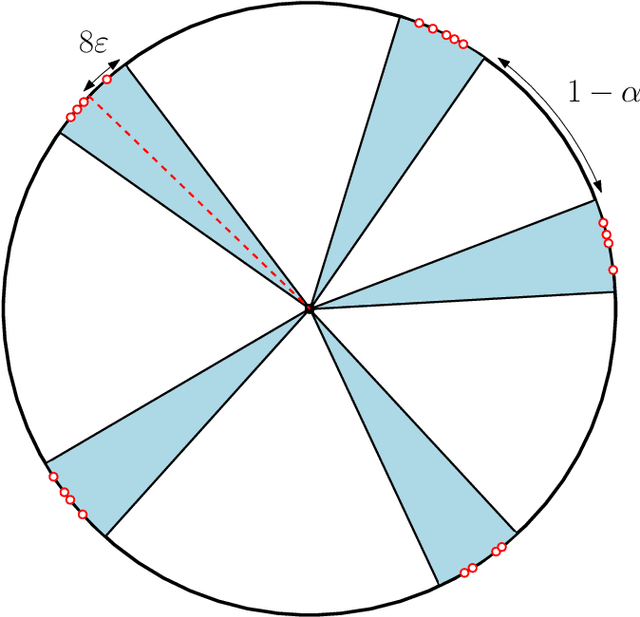

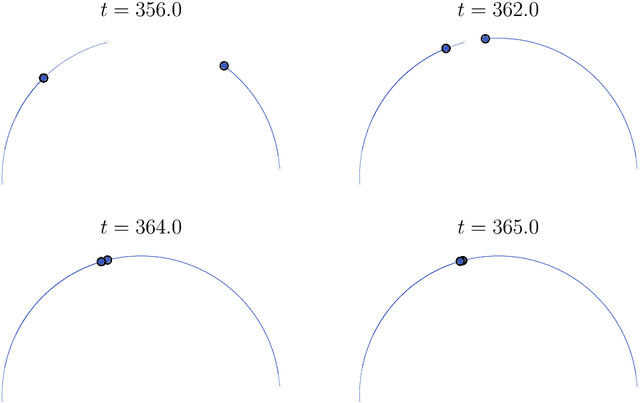

We consider the self-attention model - an interacting particle system on the unit sphere, which serves as a toy model for Transformers, the deep neural network architecture behind the recent successes of large language models. We prove the appearance of dynamic metastability conjectured in [GLPR23] - although particles collapse to a single cluster in infinite time, they remain trapped near a configuration of several clusters for an exponentially long period of time. By leveraging a gradient flow interpretation of the system, we also connect our result to an overarching framework of slow motion of gradient flows proposed by Otto and Reznikoff [OR07] in the context of coarsening and the Allen-Cahn equation. We finally probe the dynamics beyond the exponentially long period of metastability, and illustrate that, under an appropriate time-rescaling, the energy reaches its global maximum in finite time and has a staircase profile, with trajectories manifesting saddle-to-saddle-like behavior, reminiscent of recent works in the analysis of training dynamics via gradient descent for two-layer neural networks.