 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning single-index models via harmonic decomposition
Jun 11, 2025We study the problem of learning single-index models, where the label $y \in \mathbb{R}$ depends on the input $\boldsymbol{x} \in \mathbb{R}^d$ only through an unknown one-dimensional projection $\langle \boldsymbol{w}_*,\boldsymbol{x}\rangle$. Prior work has shown that under Gaussian inputs, the statistical and computational complexity of recovering $\boldsymbol{w}_*$ is governed by the Hermite expansion of the link function. In this paper, we propose a new perspective: we argue that "spherical harmonics" -- rather than "Hermite polynomials" -- provide the natural basis for this problem, as they capture its intrinsic "rotational symmetry". Building on this insight, we characterize the complexity of learning single-index models under arbitrary spherically symmetric input distributions. We introduce two families of estimators -- based on tensor unfolding and online SGD -- that respectively achieve either optimal sample complexity or optimal runtime, and argue that estimators achieving both may not exist in general. When specialized to Gaussian inputs, our theory not only recovers and clarifies existing results but also reveals new phenomena that had previously been overlooked.
Dynamic metastability in the self-attention model
Oct 09, 2024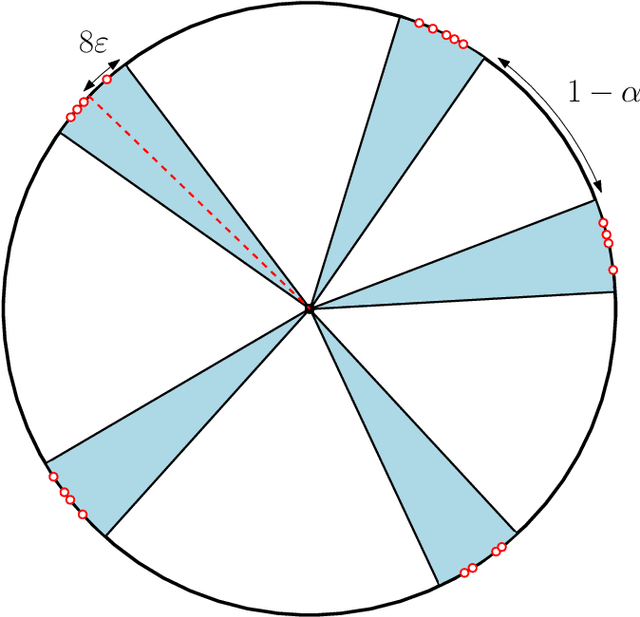

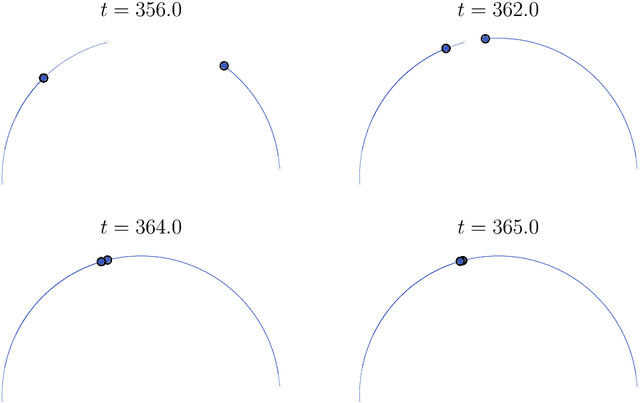

We consider the self-attention model - an interacting particle system on the unit sphere, which serves as a toy model for Transformers, the deep neural network architecture behind the recent successes of large language models. We prove the appearance of dynamic metastability conjectured in [GLPR23] - although particles collapse to a single cluster in infinite time, they remain trapped near a configuration of several clusters for an exponentially long period of time. By leveraging a gradient flow interpretation of the system, we also connect our result to an overarching framework of slow motion of gradient flows proposed by Otto and Reznikoff [OR07] in the context of coarsening and the Allen-Cahn equation. We finally probe the dynamics beyond the exponentially long period of metastability, and illustrate that, under an appropriate time-rescaling, the energy reaches its global maximum in finite time and has a staircase profile, with trajectories manifesting saddle-to-saddle-like behavior, reminiscent of recent works in the analysis of training dynamics via gradient descent for two-layer neural networks.
The Impact of LoRA on the Emergence of Clusters in Transformers
Feb 23, 2024In this paper, we employ the mathematical framework on Transformers developed by \citet{sander2022sinkformers,geshkovski2023emergence,geshkovski2023mathematical} to explore how variations in attention parameters and initial token values impact the structural dynamics of token clusters. Our analysis demonstrates that while the clusters within a modified attention matrix dynamics can exhibit significant divergence from the original over extended periods, they maintain close similarities over shorter intervals, depending on the parameter differences. This work contributes to the fine-tuning field through practical applications to the LoRA algorithm \cite{hu2021lora,peft}, enhancing our understanding of the behavior of LoRA-enhanced Transformer models.