 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Robot 3D Scene Understanding
Paper and Code
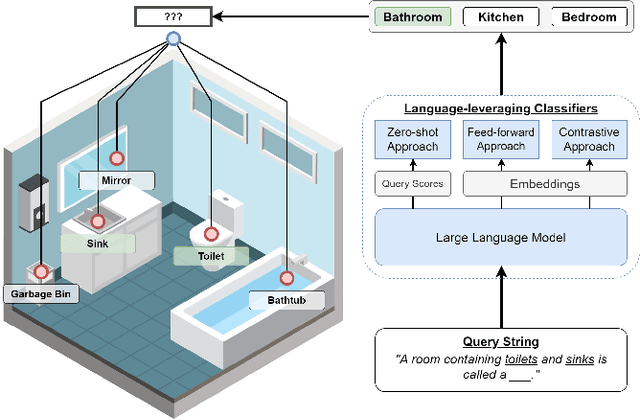

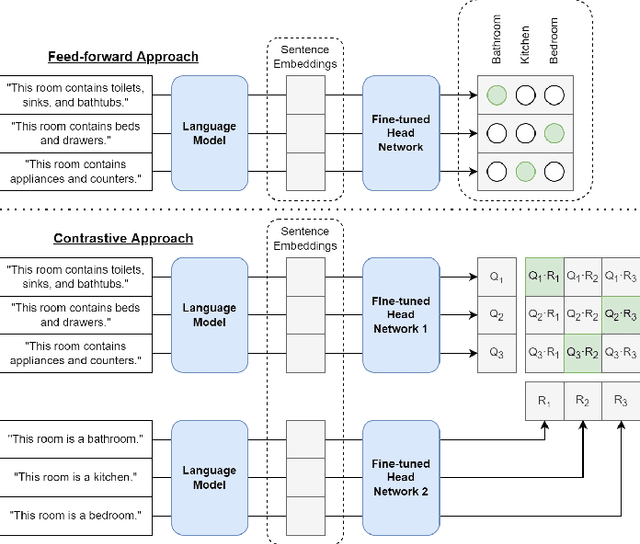
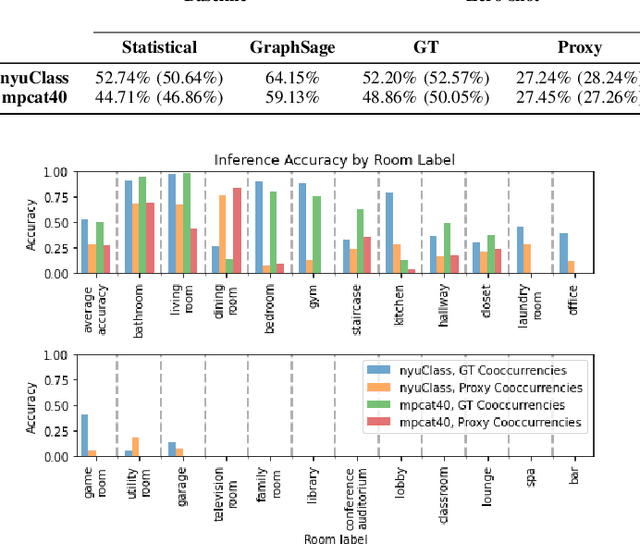
Semantic 3D scene understanding is a problem of critical importance in robotics. While significant advances have been made in spatial perception, robots are still far from having the common-sense knowledge about household objects and locations of an average human. We thus investigate the use of large language models to impart common sense for scene understanding. Specifically, we introduce three paradigms for leveraging language for classifying rooms in indoor environments based on their contained objects: (i) a zero-shot approach, (ii) a feed-forward classifier approach, and (iii) a contrastive classifier approach. These methods operate on 3D scene graphs produced by modern spatial perception systems. We then analyze each approach, demonstrating notable zero-shot generalization and transfer capabilities stemming from their use of language. Finally, we show these approaches also apply to inferring building labels from contained rooms and demonstrate our zero-shot approach on a real environment. All code can be found at https://github.com/MIT-SPARK/llm_scene_understanding.