 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverBERT: A State Space Model for Efficient Text-Driven Speech Style Transfer
Mar 26, 2025Text-driven speech style transfer aims to mold the intonation, pace, and timbre of a spoken utterance to match stylistic cues from text descriptions. While existing methods leverage large-scale neural architectures or pre-trained language models, the computational costs often remain high. In this paper, we present \emph{ReverBERT}, an efficient framework for text-driven speech style transfer that draws inspiration from a state space model (SSM) paradigm, loosely motivated by the image-based method of Wang and Liu~\cite{wang2024stylemamba}. Unlike image domain techniques, our method operates in the speech space and integrates a discrete Fourier transform of latent speech features to enable smooth and continuous style modulation. We also propose a novel \emph{Transformer-based SSM} layer for bridging textual style descriptors with acoustic attributes, dramatically reducing inference time while preserving high-quality speech characteristics. Extensive experiments on benchmark speech corpora demonstrate that \emph{ReverBERT} significantly outperforms baselines in terms of naturalness, expressiveness, and computational efficiency. We release our model and code publicly to foster further research in text-driven speech style transfer.
Cross-Modal State-Space Graph Reasoning for Structured Summarization
Mar 26, 2025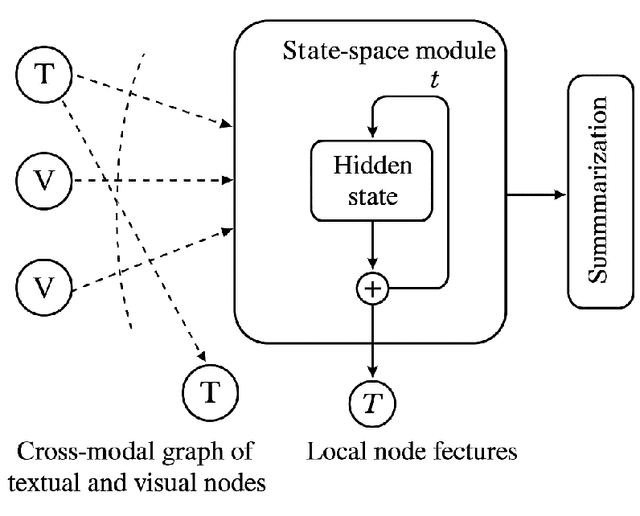
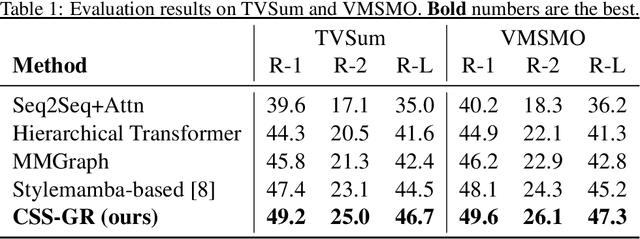

The ability to extract compact, meaningful summaries from large-scale and multimodal data is critical for numerous applications, ranging from video analytics to medical reports. Prior methods in cross-modal summarization have often suffered from high computational overheads and limited interpretability. In this paper, we propose a \textit{Cross-Modal State-Space Graph Reasoning} (\textbf{CSS-GR}) framework that incorporates a state-space model with graph-based message passing, inspired by prior work on efficient state-space models. Unlike existing approaches relying on purely sequential models, our method constructs a graph that captures inter- and intra-modal relationships, allowing more holistic reasoning over both textual and visual streams. We demonstrate that our approach significantly improves summarization quality and interpretability while maintaining computational efficiency, as validated on standard multimodal summarization benchmarks. We also provide a thorough ablation study to highlight the contributions of each component.