 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal State-Space Graph Reasoning for Structured Summarization
Paper and Code
Mar 26, 2025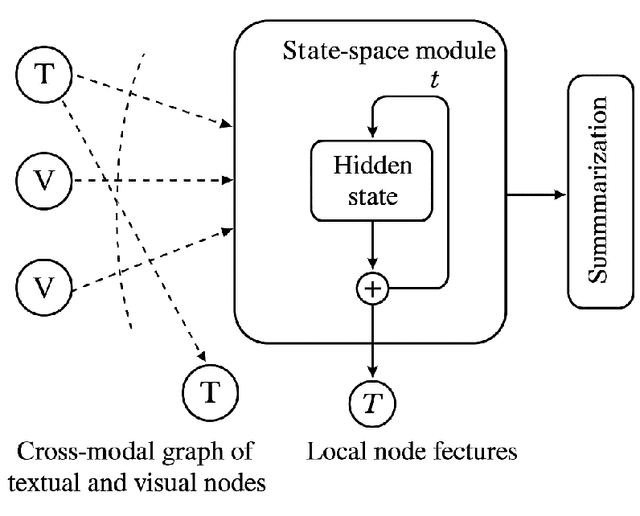
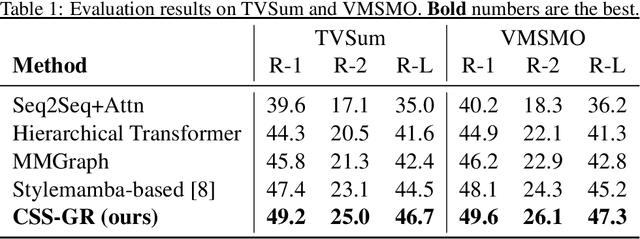

The ability to extract compact, meaningful summaries from large-scale and multimodal data is critical for numerous applications, ranging from video analytics to medical reports. Prior methods in cross-modal summarization have often suffered from high computational overheads and limited interpretability. In this paper, we propose a \textit{Cross-Modal State-Space Graph Reasoning} (\textbf{CSS-GR}) framework that incorporates a state-space model with graph-based message passing, inspired by prior work on efficient state-space models. Unlike existing approaches relying on purely sequential models, our method constructs a graph that captures inter- and intra-modal relationships, allowing more holistic reasoning over both textual and visual streams. We demonstrate that our approach significantly improves summarization quality and interpretability while maintaining computational efficiency, as validated on standard multimodal summarization benchmarks. We also provide a thorough ablation study to highlight the contributions of each component.