 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Cycle-consistent Generalized Zero-Shot Learning
Aug 02, 2018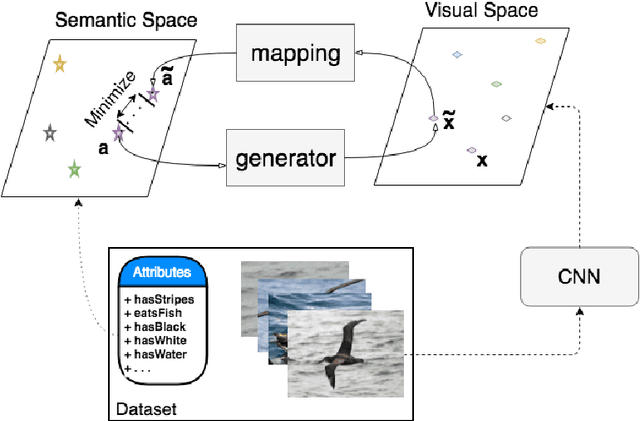
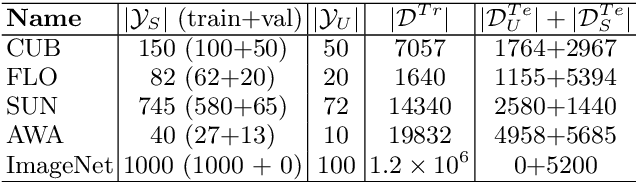
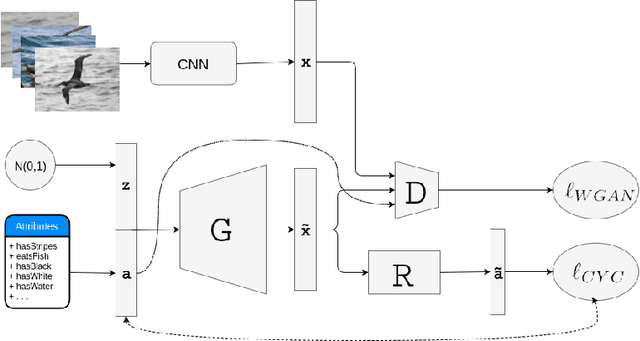

In generalized zero shot learning (GZSL), the set of classes are split into seen and unseen classes, where training relies on the semantic features of the seen and unseen classes and the visual representations of only the seen classes, while testing uses the visual representations of the seen and unseen classes. Current methods address GZSL by learning a transformation from the visual to the semantic space, exploring the assumption that the distribution of classes in the semantic and visual spaces is relatively similar. Such methods tend to transform unseen testing visual representations into one of the seen classes' semantic features instead of the semantic features of the correct unseen class, resulting in low accuracy GZSL classification. Recently, generative adversarial networks (GAN) have been explored to synthesize visual representations of the unseen classes from their semantic features - the synthesized representations of the seen and unseen classes are then used to train the GZSL classifier. This approach has been shown to boost GZSL classification accuracy, however, there is no guarantee that synthetic visual representations can generate back their semantic feature in a multi-modal cycle-consistent manner. This constraint can result in synthetic visual representations that do not represent well their semantic features. In this paper, we propose the use of such constraint based on a new regularization for the GAN training that forces the generated visual features to reconstruct their original semantic features. Once our model is trained with this multi-modal cycle-consistent semantic compatibility, we can then synthesize more representative visual representations for the seen and, more importantly, for the unseen classes. Our proposed approach shows the best GZSL classification results in the field in several publicly available datasets.