 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-driven GUI Grounding: Leveraging Pretrained Multimodal Large Language Models without Fine-Tuning
Dec 14, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have generated significant interest in their ability to autonomously interact with and interpret Graphical User Interfaces (GUIs). A major challenge in these systems is grounding-accurately identifying critical GUI components such as text or icons based on a GUI image and a corresponding text query. Traditionally, this task has relied on fine-tuning MLLMs with specialized training data to predict component locations directly. However, in this paper, we propose a novel Tuning-free Attention-driven Grounding (TAG) method that leverages the inherent attention patterns in pretrained MLLMs to accomplish this task without the need for additional fine-tuning. Our method involves identifying and aggregating attention maps from specific tokens within a carefully constructed query prompt. Applied to MiniCPM-Llama3-V 2.5, a state-of-the-art MLLM, our tuning-free approach achieves performance comparable to tuning-based methods, with notable success in text localization. Additionally, we demonstrate that our attention map-based grounding technique significantly outperforms direct localization predictions from MiniCPM-Llama3-V 2.5, highlighting the potential of using attention maps from pretrained MLLMs and paving the way for future innovations in this domain.
Progressive Feature Adjustment for Semi-supervised Learning from Pretrained Models
Sep 09, 2023



As an effective way to alleviate the burden of data annotation, semi-supervised learning (SSL) provides an attractive solution due to its ability to leverage both labeled and unlabeled data to build a predictive model. While significant progress has been made recently, SSL algorithms are often evaluated and developed under the assumption that the network is randomly initialized. This is in sharp contrast to most vision recognition systems that are built from fine-tuning a pretrained network for better performance. While the marriage of SSL and a pretrained model seems to be straightforward, recent literature suggests that naively applying state-of-the-art SSL with a pretrained model fails to unleash the full potential of training data. In this paper, we postulate the underlying reason is that the pretrained feature representation could bring a bias inherited from the source data, and the bias tends to be magnified through the self-training process in a typical SSL algorithm. To overcome this issue, we propose to use pseudo-labels from the unlabelled data to update the feature extractor that is less sensitive to incorrect labels and only allow the classifier to be trained from the labeled data. More specifically, we progressively adjust the feature extractor to ensure its induced feature distribution maintains a good class separability even under strong input perturbation. Through extensive experimental studies, we show that the proposed approach achieves superior performance over existing solutions.
Towards Domain Generalization for Multi-view 3D Object Detection in Bird-Eye-View
Mar 03, 2023
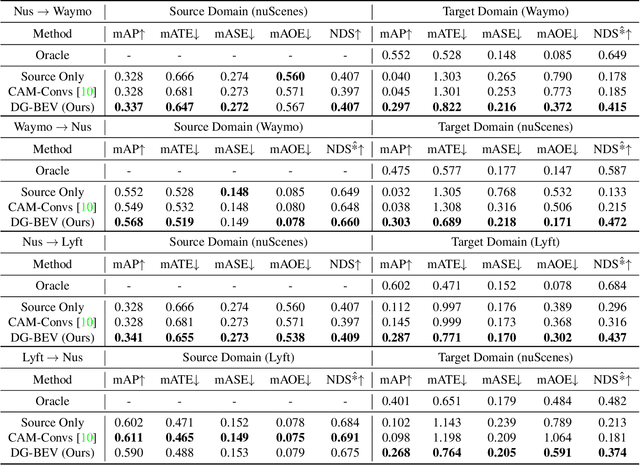
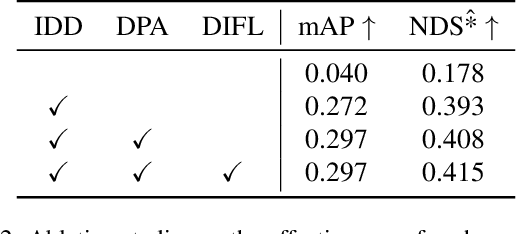
Multi-view 3D object detection (MV3D-Det) in Bird-Eye-View (BEV) has drawn extensive attention due to its low cost and high efficiency. Although new algorithms for camera-only 3D object detection have been continuously proposed, most of them may risk drastic performance degradation when the domain of input images differs from that of training. In this paper, we first analyze the causes of the domain gap for the MV3D-Det task. Based on the covariate shift assumption, we find that the gap mainly attributes to the feature distribution of BEV, which is determined by the quality of both depth estimation and 2D image's feature representation. To acquire a robust depth prediction, we propose to decouple the depth estimation from the intrinsic parameters of the camera (i.e. the focal length) through converting the prediction of metric depth to that of scale-invariant depth and perform dynamic perspective augmentation to increase the diversity of the extrinsic parameters (i.e. the camera poses) by utilizing homography. Moreover, we modify the focal length values to create multiple pseudo-domains and construct an adversarial training loss to encourage the feature representation to be more domain-agnostic. Without bells and whistles, our approach, namely DG-BEV, successfully alleviates the performance drop on the unseen target domain without impairing the accuracy of the source domain. Extensive experiments on various public datasets, including Waymo, nuScenes, and Lyft, demonstrate the generalization and effectiveness of our approach. To the best of our knowledge, this is the first systematic study to explore a domain generalization method for MV3D-Det.
Semi-supervised Semantic Segmentation with Prototype-based Consistency Regularization
Oct 10, 2022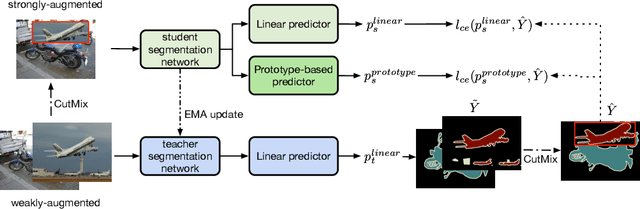
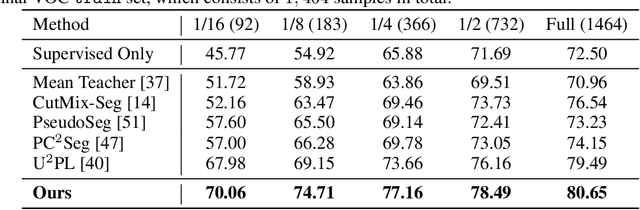
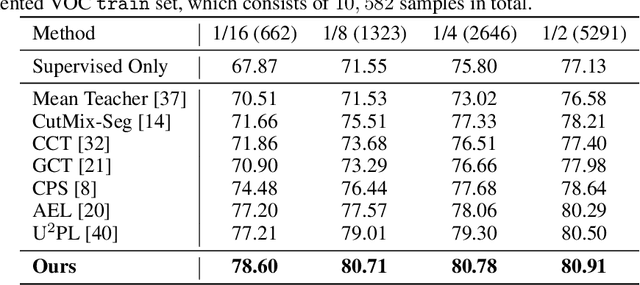
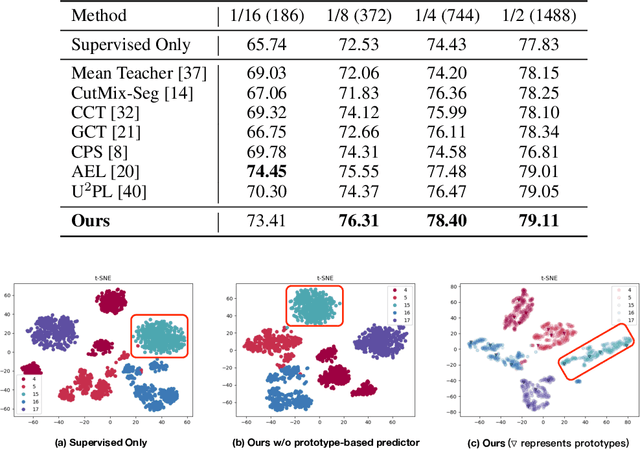
Semi-supervised semantic segmentation requires the model to effectively propagate the label information from limited annotated images to unlabeled ones. A challenge for such a per-pixel prediction task is the large intra-class variation, i.e., regions belonging to the same class may exhibit a very different appearance even in the same picture. This diversity will make the label propagation hard from pixels to pixels. To address this problem, we propose a novel approach to regularize the distribution of within-class features to ease label propagation difficulty. Specifically, our approach encourages the consistency between the prediction from a linear predictor and the output from a prototype-based predictor, which implicitly encourages features from the same pseudo-class to be close to at least one within-class prototype while staying far from the other between-class prototypes. By further incorporating CutMix operations and a carefully-designed prototype maintenance strategy, we create a semi-supervised semantic segmentation algorithm that demonstrates superior performance over the state-of-the-art methods from extensive experimental evaluation on both Pascal VOC and Cityscapes benchmarks.
Two-stage Decision Improves Open-Set Panoptic Segmentation
Jul 09, 2022
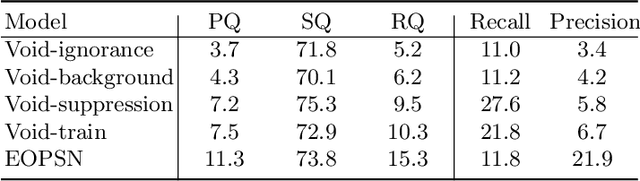


Open-set panoptic segmentation (OPS) problem is a new research direction aiming to perform segmentation for both \known classes and \unknown classes, i.e., the objects ("things") that are never annotated in the training set. The main challenges of OPS are twofold: (1) the infinite possibility of the \unknown object appearances makes it difficult to model them from a limited number of training data. (2) at training time, we are only provided with the "void" category, which essentially mixes the "unknown thing" and "background" classes. We empirically find that directly using "void" category to supervise \known class or "background" without screening will not lead to a satisfied OPS result. In this paper, we propose a divide-and-conquer scheme to develop a two-stage decision process for OPS. We show that by properly combining a \known class discriminator with an additional class-agnostic object prediction head, the OPS performance can be significantly improved. Specifically, we first propose to create a classifier with only \known categories and let the "void" class proposals achieve low prediction probability from those categories. Then we distinguish the "unknown things" from the background by using the additional object prediction head. To further boost performance, we introduce "unknown things" pseudo-labels generated from up-to-date models and a heuristic rule to enrich the training set. Our extensive experimental evaluation shows that our approach significantly improves \unknown class panoptic quality, with more than 30\% relative improvements than the existing best-performed method.
Progressive Class Semantic Matching for Semi-supervised Text Classification
May 20, 2022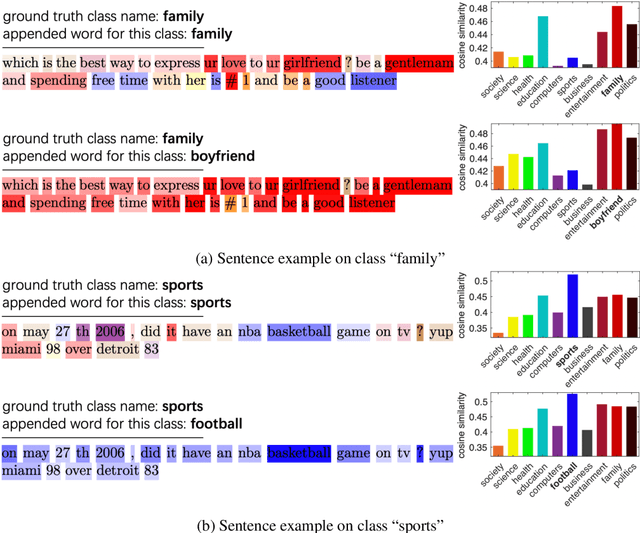
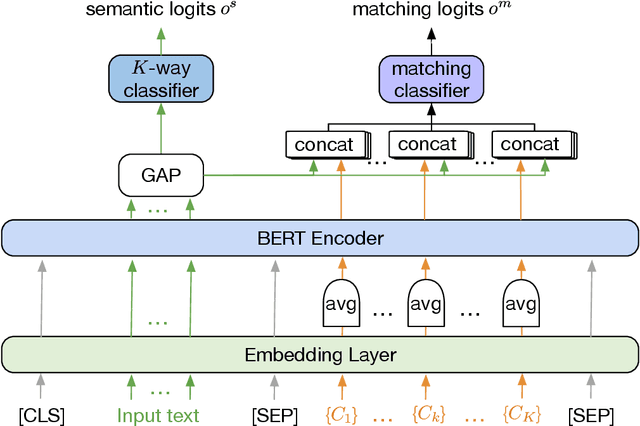
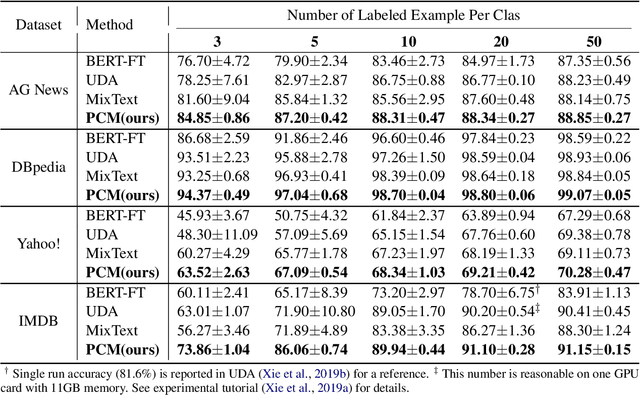
Semi-supervised learning is a promising way to reduce the annotation cost for text-classification. Combining with pre-trained language models (PLMs), e.g., BERT, recent semi-supervised learning methods achieved impressive performance. In this work, we further investigate the marriage between semi-supervised learning and a pre-trained language model. Unlike existing approaches that utilize PLMs only for model parameter initialization, we explore the inherent topic matching capability inside PLMs for building a more powerful semi-supervised learning approach. Specifically, we propose a joint semi-supervised learning process that can progressively build a standard $K$-way classifier and a matching network for the input text and the Class Semantic Representation (CSR). The CSR will be initialized from the given labeled sentences and progressively updated through the training process. By means of extensive experiments, we show that our method can not only bring remarkable improvement to baselines, but also overall be more stable, and achieves state-of-the-art performance in semi-supervised text classification.
Semi-supervised Learning via Conditional Rotation Angle Estimation
Jan 09, 2020
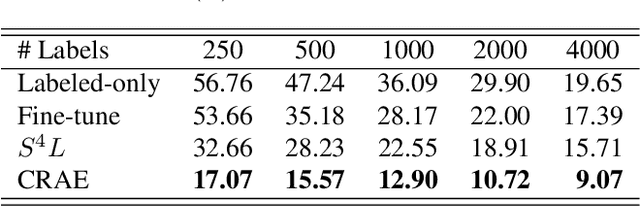
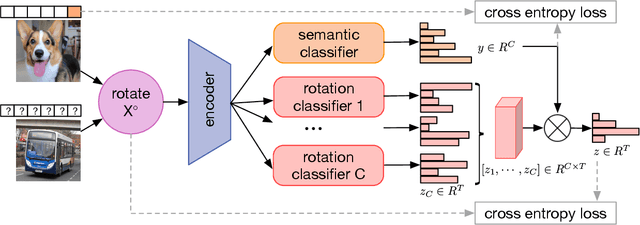
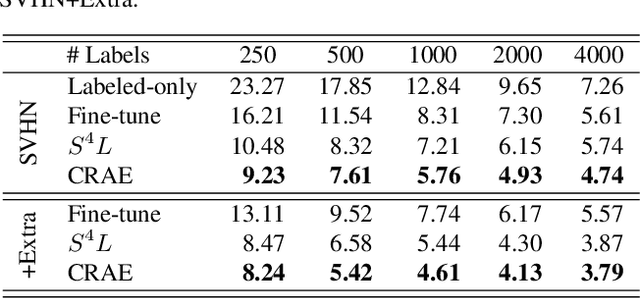
Self-supervised learning (SlfSL), aiming at learning feature representations through ingeniously designed pretext tasks without human annotation, has achieved compelling progress in the past few years. Very recently, SlfSL has also been identified as a promising solution for semi-supervised learning (SemSL) since it offers a new paradigm to utilize unlabeled data. This work further explores this direction by proposing to couple SlfSL with SemSL. Our insight is that the prediction target in SemSL can be modeled as the latent factor in the predictor for the SlfSL target. Marginalizing over the latent factor naturally derives a new formulation which marries the prediction targets of these two learning processes. By implementing this idea through a simple-but-effective SlfSL approach -- rotation angle prediction, we create a new SemSL approach called Conditional Rotation Angle Estimation (CRAE). Specifically, CRAE is featured by adopting a module which predicts the image rotation angle conditioned on the candidate image class. Through experimental evaluation, we show that CRAE achieves superior performance over the other existing ways of combining SlfSL and SemSL. To further boost CRAE, we propose two extensions to strengthen the coupling between SemSL target and SlfSL target in basic CRAE. We show that this leads to an improved CRAE method which can achieve the state-of-the-art SemSL performance.