 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer Based User Equipment Positioning
Nov 11, 2025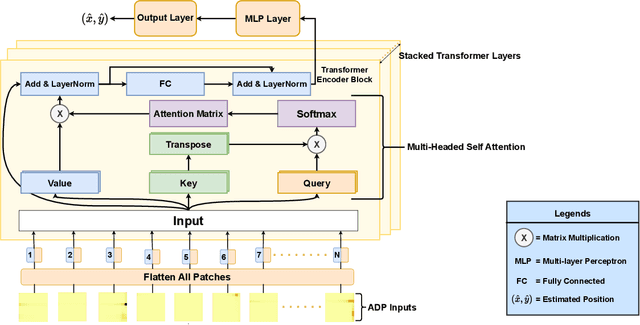
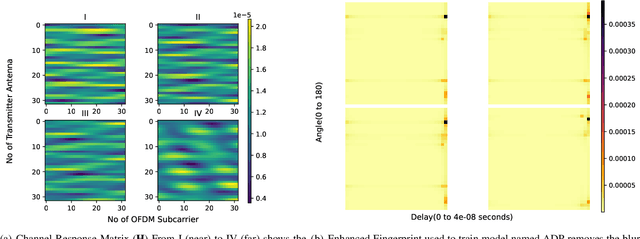
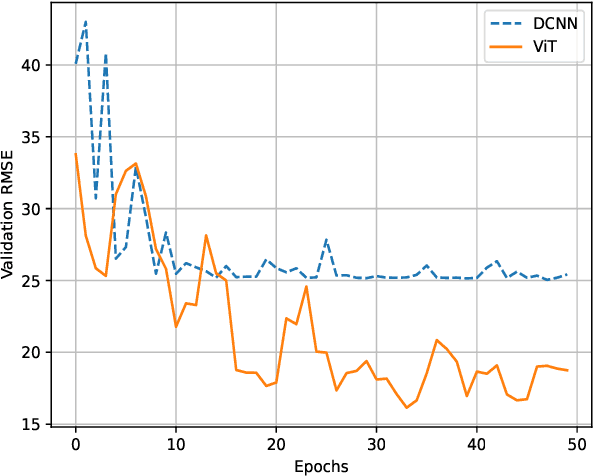
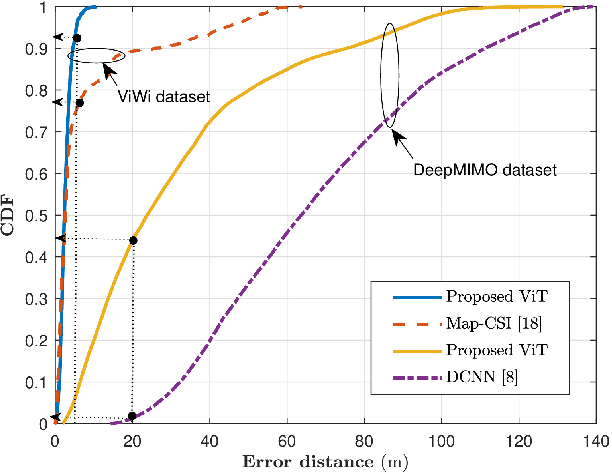
Recently, Deep Learning (DL) techniques have been used for User Equipment (UE) positioning. However, the key shortcomings of such models is that: i) they weigh the same attention to the entire input; ii) they are not well suited for the non-sequential data e.g., when only instantaneous Channel State Information (CSI) is available. In this context, we propose an attention-based Vision Transformer (ViT) architecture that focuses on the Angle Delay Profile (ADP) from CSI matrix. Our approach, validated on the `DeepMIMO' and `ViWi' ray-tracing datasets, achieves an Root Mean Squared Error (RMSE) of 0.55m indoors, 13.59m outdoors in DeepMIMO, and 3.45m in ViWi's outdoor blockage scenario. The proposed scheme outperforms state-of-the-art schemes by $\sim$ 38\%. It also performs substantially better than other approaches that we have considered in terms of the distribution of error distance.
DanceMosaic: High-Fidelity Dance Generation with Multimodal Editability
Apr 06, 2025Recent advances in dance generation have enabled automatic synthesis of 3D dance motions. However, existing methods still struggle to produce high-fidelity dance sequences that simultaneously deliver exceptional realism, precise dance-music synchronization, high motion diversity, and physical plausibility. Moreover, existing methods lack the flexibility to edit dance sequences according to diverse guidance signals, such as musical prompts, pose constraints, action labels, and genre descriptions, significantly restricting their creative utility and adaptability. Unlike the existing approaches, DanceMosaic enables fast and high-fidelity dance generation, while allowing multimodal motion editing. Specifically, we propose a multimodal masked motion model that fuses the text-to-motion model with music and pose adapters to learn probabilistic mapping from diverse guidance signals to high-quality dance motion sequences via progressive generative masking training. To further enhance the motion generation quality, we propose multimodal classifier-free guidance and inference-time optimization mechanism that further enforce the alignment between the generated motions and the multimodal guidance. Extensive experiments demonstrate that our method establishes a new state-of-the-art performance in dance generation, significantly advancing the quality and editability achieved by existing approaches.
PeR-ViS: Person Retrieval in Video Surveillance using Semantic Description
Dec 04, 2020
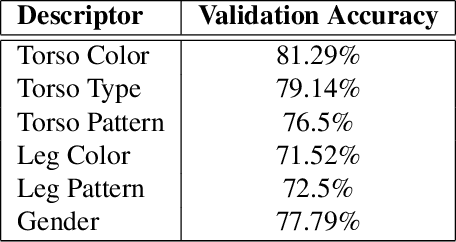
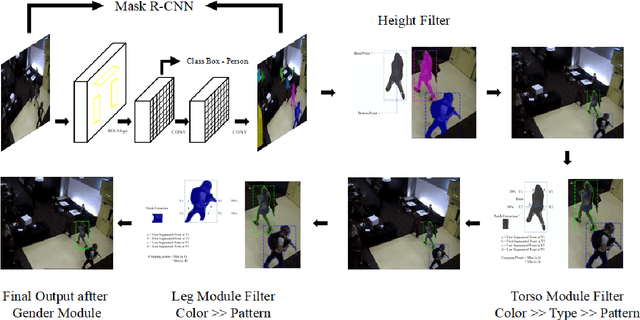
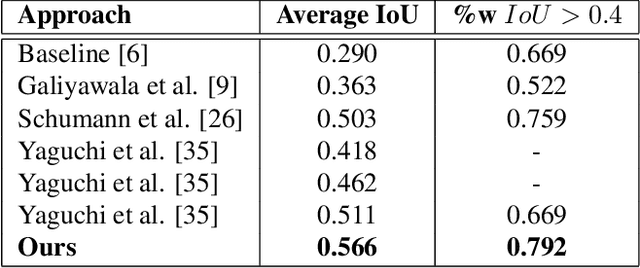
A person is usually characterized by descriptors like age, gender, height, cloth type, pattern, color, etc. Such descriptors are known as attributes and/or soft-biometrics. They link the semantic gap between a person's description and retrieval in video surveillance. Retrieving a specific person with the query of semantic description has an important application in video surveillance. Using computer vision to fully automate the person retrieval task has been gathering interest within the research community. However, the Current, trend mainly focuses on retrieving persons with image-based queries, which have major limitations for practical usage. Instead of using an image query, in this paper, we study the problem of person retrieval in video surveillance with a semantic description. To solve this problem, we develop a deep learning-based cascade filtering approach (PeR-ViS), which uses Mask R-CNN [14] (person detection and instance segmentation) and DenseNet-161 [16] (soft-biometric classification). On the standard person retrieval dataset of SoftBioSearch [6], we achieve 0.566 Average IoU and 0.792 %w $IoU > 0.4$, surpassing the current state-of-the-art by a large margin. We hope our simple, reproducible, and effective approach will help ease future research in the domain of person retrieval in video surveillance. The source code and pretrained weights available at https://parshwa1999.github.io/PeR-ViS/.