 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Sequences in the Latent Embedding Space: $K$-Token Merging for Large Language Models
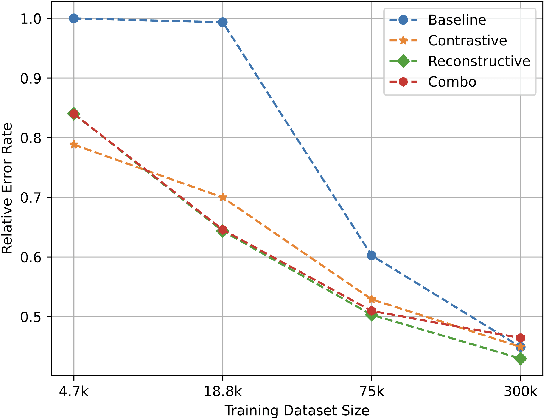
Apr 16, 2026Large Language Models (LLMs) incur significant computational and memory costs when processing long prompts, as full self-attention scales quadratically with input length. Token compression aims to address this challenge by reducing the number of tokens representing inputs. However, existing prompt-compression approaches primarily operate in token space and overlook inefficiencies in the latent embedding space. In this paper, we propose K-Token Merging, a latent-space compression framework that merges each contiguous block of K token embeddings into a single embedding via a lightweight encoder. The compressed sequence is processed by a LoRA-adapted LLM, while generation remains in the original vocabulary. Experiments on structural reasoning (Textualized Tree), sentiment classification (Amazon Reviews), and code editing (CommitPackFT) show that K-Token Merging lies on the Pareto frontier of performance vs. compression, achieving up to 75% input length reduction with minimal performance degradation.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
LI-TTA: Language Informed Test-Time Adaptation for Automatic Speech Recognition
Aug 11, 2024
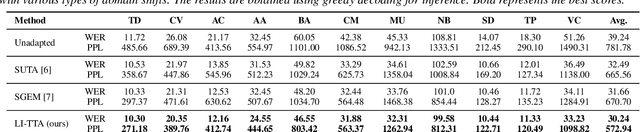
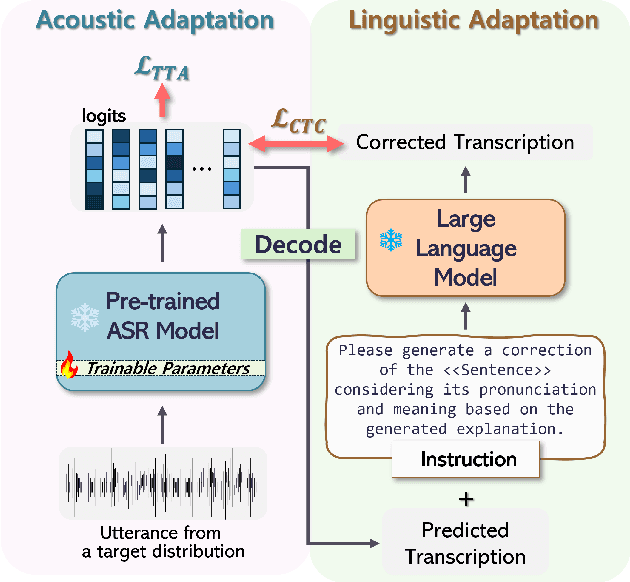
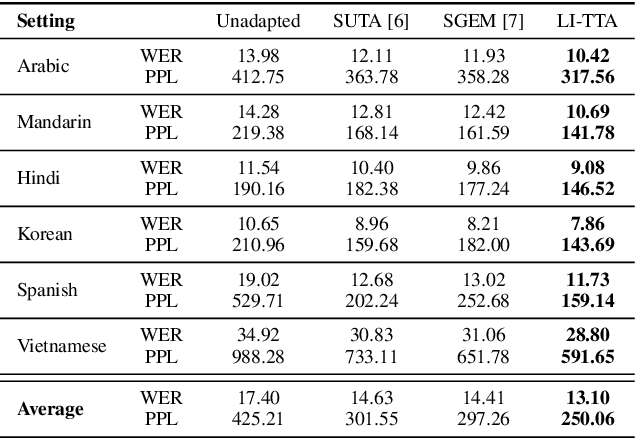
Test-Time Adaptation (TTA) has emerged as a crucial solution to the domain shift challenge, wherein the target environment diverges from the original training environment. A prime exemplification is TTA for Automatic Speech Recognition (ASR), which enhances model performance by leveraging output prediction entropy minimization as a self-supervision signal. However, a key limitation of this self-supervision lies in its primary focus on acoustic features, with minimal attention to the linguistic properties of the input. To address this gap, we propose Language Informed Test-Time Adaptation (LI-TTA), which incorporates linguistic insights during TTA for ASR. LI-TTA integrates corrections from an external language model to merge linguistic with acoustic information by minimizing the CTC loss from the correction alongside the standard TTA loss. With extensive experiments, we show that LI-TTA effectively improves the performance of TTA for ASR in various distribution shift situations.
Mitigating the Exposure Bias in Sentence-Level Grapheme-to-Phoneme (G2P) Transduction
Aug 16, 2023



Text-to-Text Transfer Transformer (T5) has recently been considered for the Grapheme-to-Phoneme (G2P) transduction. As a follow-up, a tokenizer-free byte-level model based on T5 referred to as ByT5, recently gave promising results on word-level G2P conversion by representing each input character with its corresponding UTF-8 encoding. Although it is generally understood that sentence-level or paragraph-level G2P can improve usability in real-world applications as it is better suited to perform on heteronyms and linking sounds between words, we find that using ByT5 for these scenarios is nontrivial. Since ByT5 operates on the character level, it requires longer decoding steps, which deteriorates the performance due to the exposure bias commonly observed in auto-regressive generation models. This paper shows that the performance of sentence-level and paragraph-level G2P can be improved by mitigating such exposure bias using our proposed loss-based sampling method.
INTapt: Information-Theoretic Adversarial Prompt Tuning for Enhanced Non-Native Speech Recognition
May 25, 2023



Automatic Speech Recognition (ASR) systems have attained unprecedented performance with large speech models pre-trained based on self-supervised speech representation learning. However, these pre-trained speech models suffer from representational bias as they tend to better represent those prominent accents (i.e., native (L1) English accent) in the pre-training speech corpus than less represented accents, resulting in a deteriorated performance for non-native (L2) English accents. Although there have been some approaches to mitigate this issue, all of these methods require updating the pre-trained model weights. In this paper, we propose Information Theoretic Adversarial Prompt Tuning (INTapt), which introduces prompts concatenated to the original input that can re-modulate the attention of the pre-trained model such that the corresponding input resembles a native (L1) English speech without updating the backbone weights. INTapt is trained simultaneously in the following two manners: (1) adversarial training to reduce accent feature dependence between the original input and the prompt-concatenated input and (2) training to minimize CTC loss for improving ASR performance to a prompt-concatenated input. Experimental results show that INTapt improves the performance of L2 English and increases feature similarity between L2 and L1 accents.
SPADE: Self-supervised Pretraining for Acoustic DisEntanglement
Feb 03, 2023
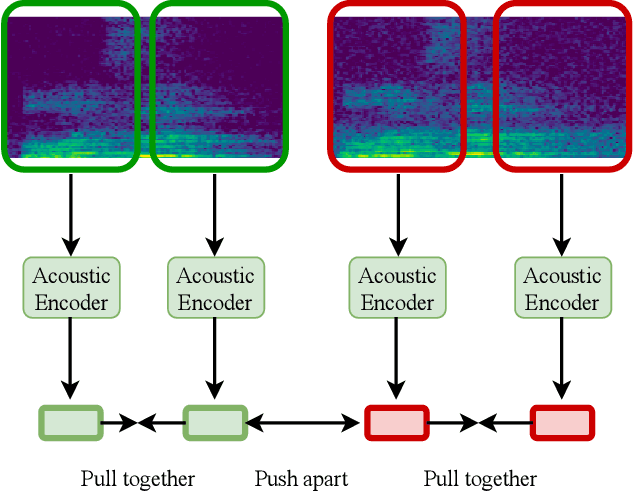

Self-supervised representation learning approaches have grown in popularity due to the ability to train models on large amounts of unlabeled data and have demonstrated success in diverse fields such as natural language processing, computer vision, and speech. Previous self-supervised work in the speech domain has disentangled multiple attributes of speech such as linguistic content, speaker identity, and rhythm. In this work, we introduce a self-supervised approach to disentangle room acoustics from speech and use the acoustic representation on the downstream task of device arbitration. Our results demonstrate that our proposed approach significantly improves performance over a baseline when labeled training data is scarce, indicating that our pretraining scheme learns to encode room acoustic information while remaining invariant to other attributes of the speech signal.
SMSMix: Sense-Maintained Sentence Mixup for Word Sense Disambiguation
Dec 21, 2022



Word Sense Disambiguation (WSD) is an NLP task aimed at determining the correct sense of a word in a sentence from discrete sense choices. Although current systems have attained unprecedented performances for such tasks, the nonuniform distribution of word senses during training generally results in systems performing poorly on rare senses. To this end, we consider data augmentation to increase the frequency of these least frequent senses (LFS) to reduce the distributional bias of senses during training. We propose Sense-Maintained Sentence Mixup (SMSMix), a novel word-level mixup method that maintains the sense of a target word. SMSMix smoothly blends two sentences using mask prediction while preserving the relevant span determined by saliency scores to maintain a specific word's sense. To the best of our knowledge, this is the first attempt to apply mixup in NLP while preserving the meaning of a specific word. With extensive experiments, we validate that our augmentation method can effectively give more information about rare senses during training with maintained target sense label.