 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPADE: Self-supervised Pretraining for Acoustic DisEntanglement
Feb 03, 2023
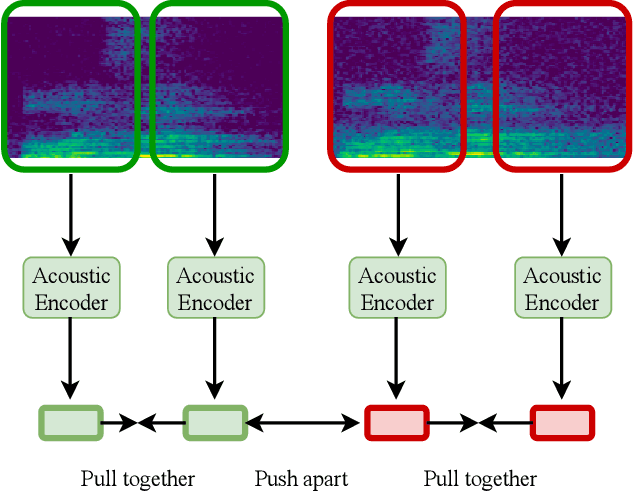

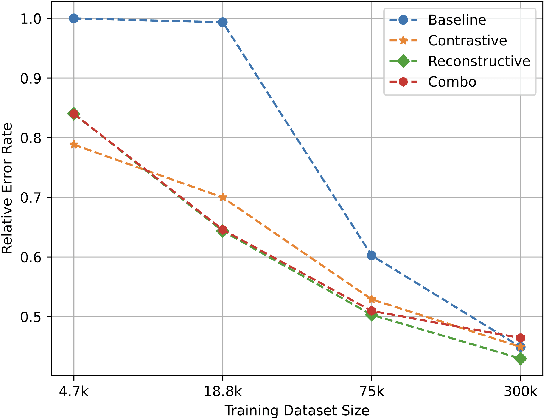
Self-supervised representation learning approaches have grown in popularity due to the ability to train models on large amounts of unlabeled data and have demonstrated success in diverse fields such as natural language processing, computer vision, and speech. Previous self-supervised work in the speech domain has disentangled multiple attributes of speech such as linguistic content, speaker identity, and rhythm. In this work, we introduce a self-supervised approach to disentangle room acoustics from speech and use the acoustic representation on the downstream task of device arbitration. Our results demonstrate that our proposed approach significantly improves performance over a baseline when labeled training data is scarce, indicating that our pretraining scheme learns to encode room acoustic information while remaining invariant to other attributes of the speech signal.