 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Monitoring of User Stress, Heart Rate and Heart Rate Variability on Mobile Devices
Oct 04, 2022
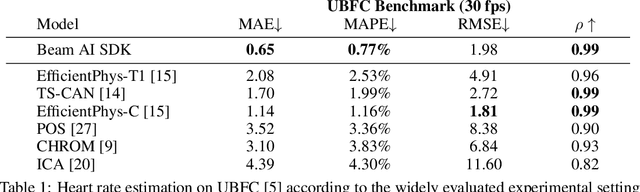
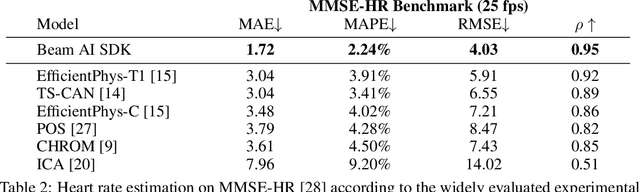
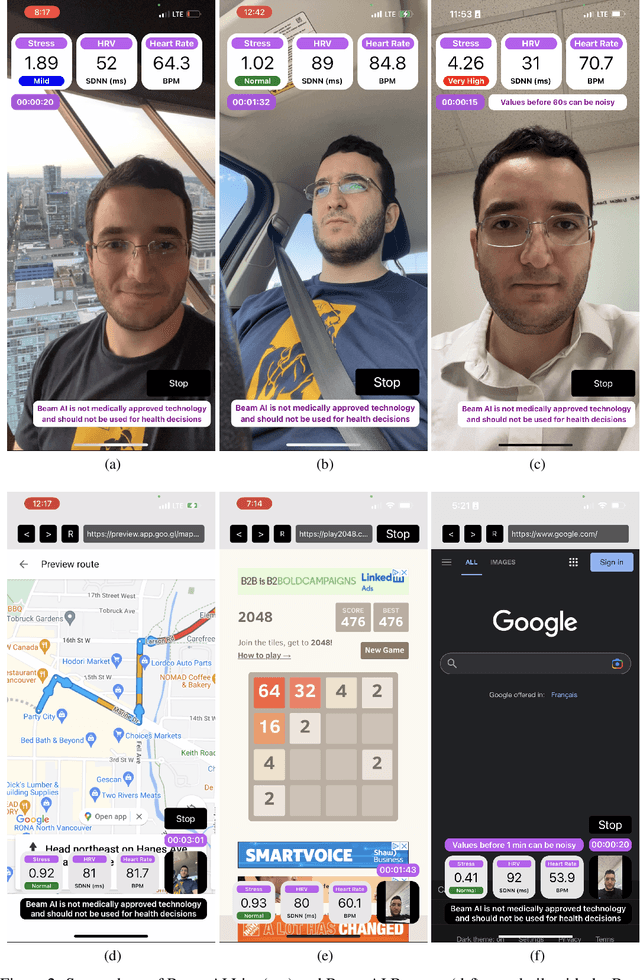
Stress is considered to be the epidemic of the 21st-century. Yet, mobile apps cannot directly evaluate the impact of their content and services on user stress. We introduce the Beam AI SDK to address this issue. Using our SDK, apps can monitor user stress through the selfie camera in real-time. Our technology extracts the user's pulse wave by analyzing subtle color variations across the skin regions of the user's face. The user's pulse wave is then used to determine stress (according to the Baevsky Stress Index), heart rate, and heart rate variability. We evaluate our technology on the UBFC dataset, the MMSE-HR dataset, and Beam AI's internal data. Our technology achieves 99.2%, 97.8% and 98.5% accuracy for heart rate estimation on each benchmark respectively, a nearly twice lower error rate than competing methods. We further demonstrate an average Pearson correlation of 0.801 in determining stress and heart rate variability, thus producing commercially useful readings to derive content decisions in apps. Our SDK is available for use at www.beamhealth.ai.
Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning
Jan 13, 2022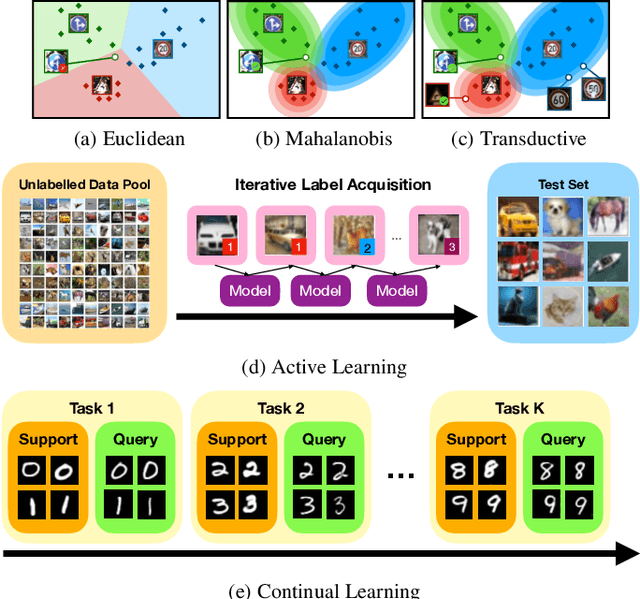
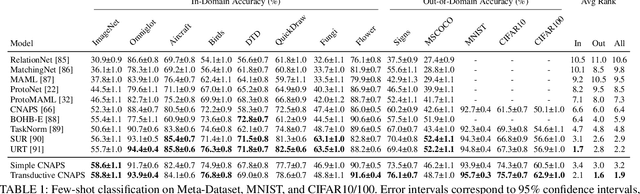
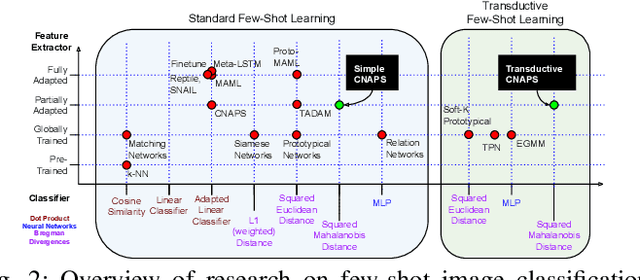
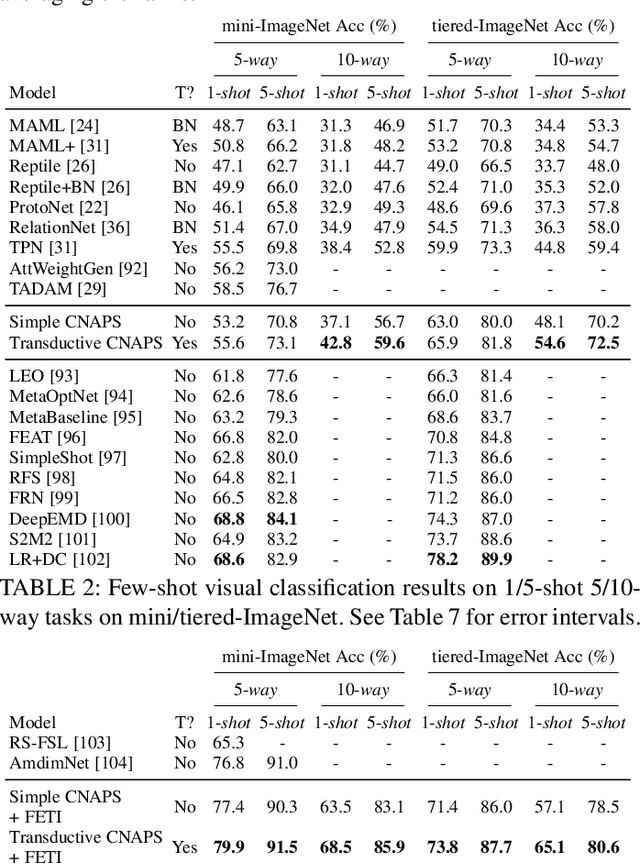
Modern deep learning requires large-scale extensively labelled datasets for training. Few-shot learning aims to alleviate this issue by learning effectively from few labelled examples. In previously proposed few-shot visual classifiers, it is assumed that the feature manifold, where classifier decisions are made, has uncorrelated feature dimensions and uniform feature variance. In this work, we focus on addressing the limitations arising from this assumption by proposing a variance-sensitive class of models that operates in a low-label regime. The first method, Simple CNAPS, employs a hierarchically regularized Mahalanobis-distance based classifier combined with a state of the art neural adaptive feature extractor to achieve strong performance on Meta-Dataset, mini-ImageNet and tiered-ImageNet benchmarks. We further extend this approach to a transductive learning setting, proposing Transductive CNAPS. This transductive method combines a soft k-means parameter refinement procedure with a two-step task encoder to achieve improved test-time classification accuracy using unlabelled data. Transductive CNAPS achieves state of the art performance on Meta-Dataset. Finally, we explore the use of our methods (Simple and Transductive) for "out of the box" continual and active learning. Extensive experiments on large scale benchmarks illustrate robustness and versatility of this, relatively speaking, simple class of models. All trained model checkpoints and corresponding source codes have been made publicly available.
Imagining The Road Ahead: Multi-Agent Trajectory Prediction via Differentiable Simulation
Apr 22, 2021
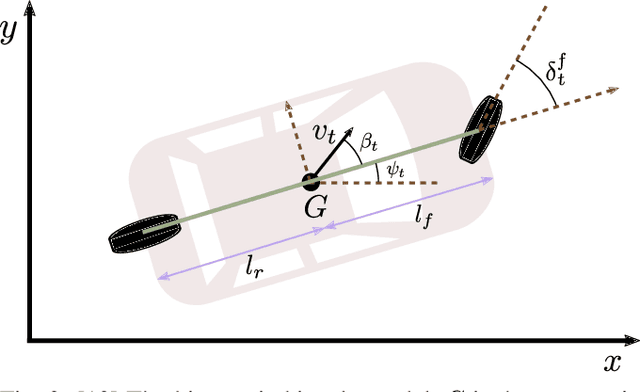
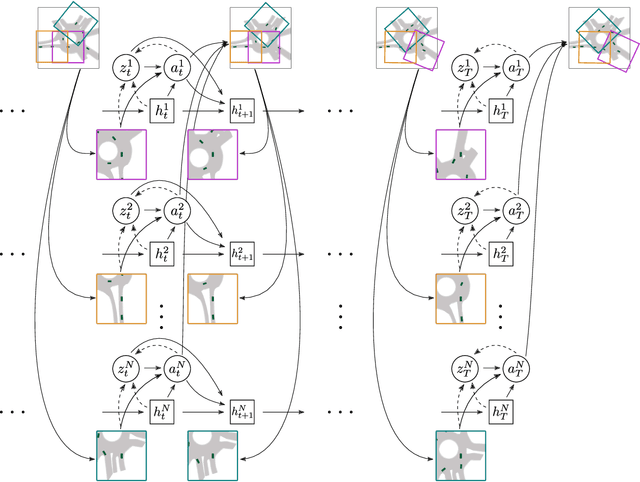
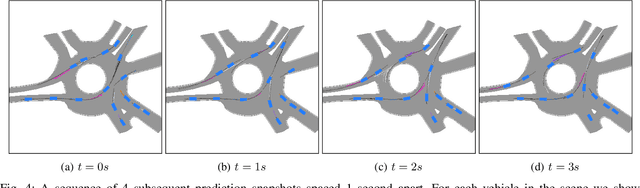
We develop a deep generative model built on a fully differentiable simulator for multi-agent trajectory prediction. Agents are modeled with conditional recurrent variational neural networks (CVRNNs), which take as input an ego-centric birdview image representing the current state of the world and output an action, consisting of steering and acceleration, which is used to derive the subsequent agent state using a kinematic bicycle model. The full simulation state is then differentiably rendered for each agent, initiating the next time step. We achieve state-of-the-art results on the INTERACTION dataset, using standard neural architectures and a standard variational training objective, producing realistic multi-modal predictions without any ad-hoc diversity-inducing losses. We conduct ablation studies to examine individual components of the simulator, finding that both the kinematic bicycle model and the continuous feedback from the birdview image are crucial for achieving this level of performance. We name our model ITRA, for "Imagining the Road Ahead".
Neural RST-based Evaluation of Discourse Coherence
Sep 30, 2020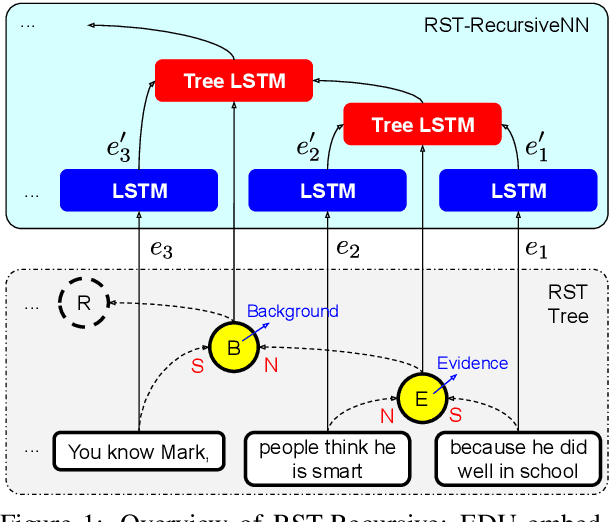
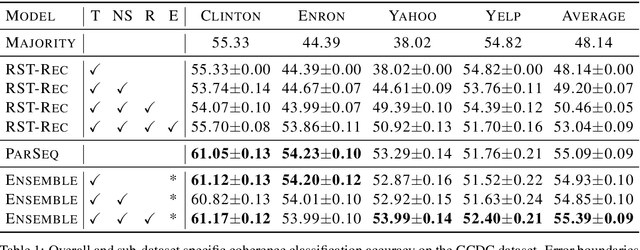
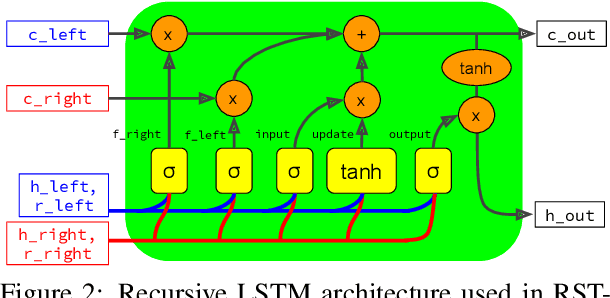
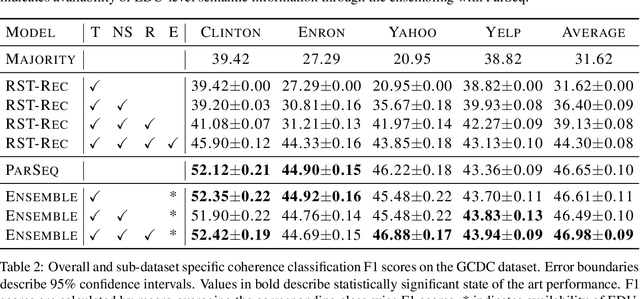
This paper evaluates the utility of Rhetorical Structure Theory (RST) trees and relations in discourse coherence evaluation. We show that incorporating silver-standard RST features can increase accuracy when classifying coherence. We demonstrate this through our tree-recursive neural model, namely RST-Recursive, which takes advantage of the text's RST features produced by a state of the art RST parser. We evaluate our approach on the Grammarly Corpus for Discourse Coherence (GCDC) and show that when ensembled with the current state of the art, we can achieve the new state of the art accuracy on this benchmark. Furthermore, when deployed alone, RST-Recursive achieves competitive accuracy while having 62% fewer parameters.
Improving Few-Shot Visual Classification with Unlabelled Examples
Jun 17, 2020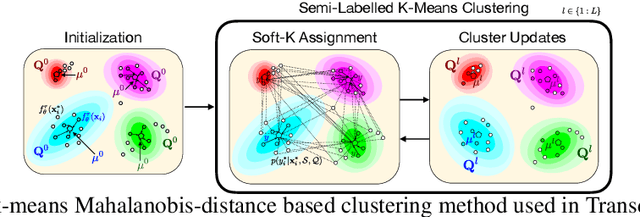
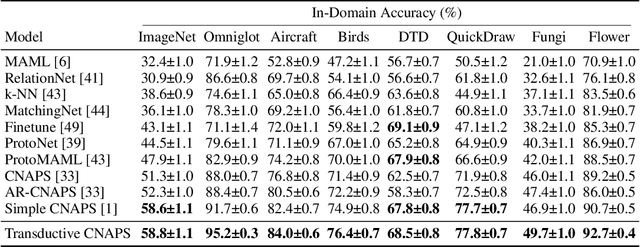
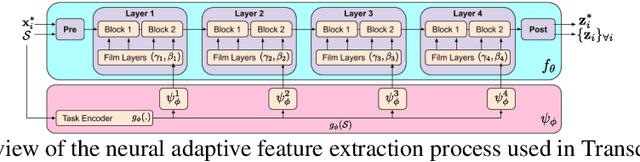
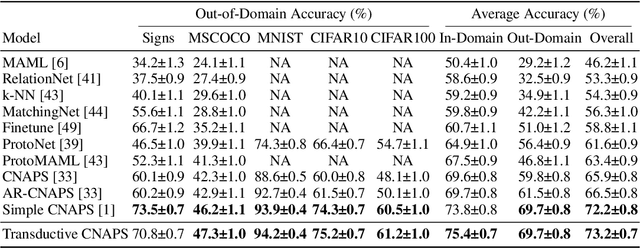
We propose a transductive meta-learning method that uses unlabelled instances to improve few-shot image classification performance. Our approach combines a regularized Mahalanobis-distance-based soft k-means clustering procedure with a state of the art neural adaptive feature extractor to achieve improved test-time classification accuracy using unlabelled data. We evaluate our method on transductive few-shot learning tasks, in which the goal is to jointly predict labels for query (test) examples given a set of support (training) examples. We achieve new state of the art in-domain performance on Meta-Dataset, and improve accuracy on mini- and tiered-ImageNet as compared to other conditional neural adaptive methods that use the same pre-trained feature extractor.
Improved Few-Shot Visual Classification
Dec 12, 2019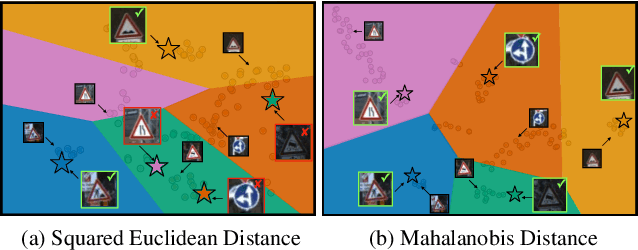

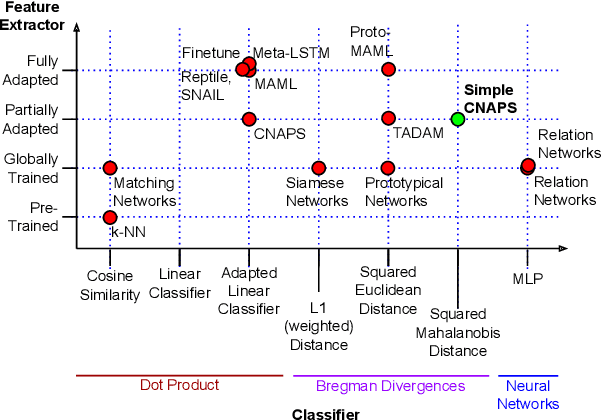

Few-shot learning is a fundamental task in computer vision that carries the promise of alleviating the need for exhaustively labeled data. Most few-shot learning approaches to date have focused on progressively more complex neural feature extractors and classifier adaptation strategies, as well as the refinement of the task definition itself. In this paper, we explore the hypothesis that a simple class-covariance-based distance metric, namely the Mahalanobis distance, adopted into a state of the art few-shot learning approach (CNAPS) can, in and of itself, lead to a significant performance improvement. We also discover that it is possible to learn adaptive feature extractors that allow useful estimation of the high dimensional feature covariances required by this metric from surprisingly few samples. The result of our work is a new "Simple CNAPS" architecture which has up to 9.2% fewer trainable parameters than CNAPS and performs up to 6.1% better than state of the art on the standard few-shot image classification benchmark dataset.