 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember to be Curious: Episodic Context and Persistent Worlds for 3D Exploration
May 21, 2026Exploration is a prerequisite for learning useful behaviors in sparse-reward, long-horizon tasks, particularly within 3D environments. Curiosity-driven reinforcement learning addresses this via intrinsic rewards derived from the mismatch between the agent's predictive model of the world and reality. However, translating this intrinsic motivation to complex, photorealistic environments remains difficult, as agents can become trapped in local loops and receive fresh rewards for revisiting forgotten states. In this work, we demonstrate that this failure stems from a lack of spatial persistence and episodic context. We show that effective curiosity requires a model of the world that is persistent and continuously updated, paired with an agent that maintains an episodic trajectory history to navigate toward novel regions. We achieve this using an online 3D reconstruction as a persistent model of the world, while the agent policy is parameterized as a sequence model over RGB observations to maintain episodic context. This design enables effective exploration during training while allowing the agent to navigate using solely RGB frames at deployment. Trained purely via curiosity on HM3D, our agent outperforms RL-based active mapping baselines and generalizes zero-shot to Gibson and AI-generated worlds. Our end-to-end policy enables efficient adaptation to downstream tasks, such as apple picking and image-goal navigation, outperforming from-scratch baselines. Please see video results at https://recuriosity.github.io/.
Diffusion-based Planning with Learned Viability Filters
Feb 26, 2025Diffusion models can be used as a motion planner by sampling from a distribution of possible futures. However, the samples may not satisfy hard constraints that exist only implicitly in the training data, e.g., avoiding falls or not colliding with a wall. We propose learned viability filters that efficiently predict the future success of any given plan, i.e., diffusion sample, and thereby enforce an implicit future-success constraint. Multiple viability filters can also be composed together. We demonstrate the approach on detailed footstep planning for challenging 3D human locomotion tasks, showing the effectiveness of viability filters in performing online planning and control for box-climbing, step-over walls, and obstacle avoidance. We further show that using viability filters is significantly faster than guidance-based diffusion prediction.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
Oct 04, 2024



Motion diffusion models and Reinforcement Learning (RL) based control for physics-based simulations have complementary strengths for human motion generation. The former is capable of generating a wide variety of motions, adhering to intuitive control such as text, while the latter offers physically plausible motion and direct interaction with the environment. In this work, we present a method that combines their respective strengths. CLoSD is a text-driven RL physics-based controller, guided by diffusion generation for various tasks. Our key insight is that motion diffusion can serve as an on-the-fly universal planner for a robust RL controller. To this end, CLoSD maintains a closed-loop interaction between two modules -- a Diffusion Planner (DiP), and a tracking controller. DiP is a fast-responding autoregressive diffusion model, controlled by textual prompts and target locations, and the controller is a simple and robust motion imitator that continuously receives motion plans from DiP and provides feedback from the environment. CLoSD is capable of seamlessly performing a sequence of different tasks, including navigation to a goal location, striking an object with a hand or foot as specified in a text prompt, sitting down, and getting up. https://guytevet.github.io/CLoSD-page/
Flexible Motion In-betweening with Diffusion Models
May 17, 2024Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.
Physics-based Motion Retargeting from Sparse Inputs
Jul 04, 2023



Avatars are important to create interactive and immersive experiences in virtual worlds. One challenge in animating these characters to mimic a user's motion is that commercial AR/VR products consist only of a headset and controllers, providing very limited sensor data of the user's pose. Another challenge is that an avatar might have a different skeleton structure than a human and the mapping between them is unclear. In this work we address both of these challenges. We introduce a method to retarget motions in real-time from sparse human sensor data to characters of various morphologies. Our method uses reinforcement learning to train a policy to control characters in a physics simulator. We only require human motion capture data for training, without relying on artist-generated animations for each avatar. This allows us to use large motion capture datasets to train general policies that can track unseen users from real and sparse data in real-time. We demonstrate the feasibility of our approach on three characters with different skeleton structure: a dinosaur, a mouse-like creature and a human. We show that the avatar poses often match the user surprisingly well, despite having no sensor information of the lower body available. We discuss and ablate the important components in our framework, specifically the kinematic retargeting step, the imitation, contact and action reward as well as our asymmetric actor-critic observations. We further explore the robustness of our method in a variety of settings including unbalancing, dancing and sports motions.
Learning to Brachiate via Simplified Model Imitation
May 08, 2022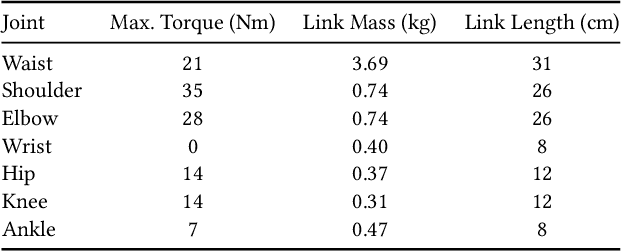
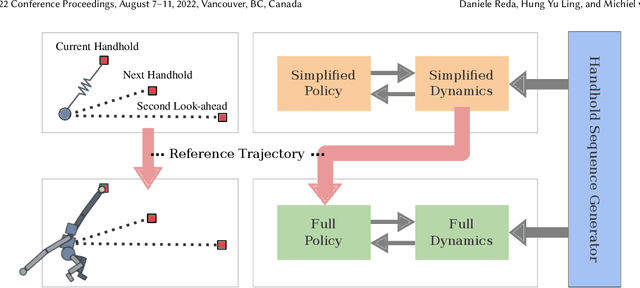

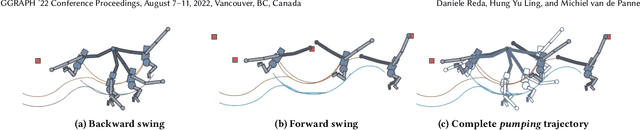
Brachiation is the primary form of locomotion for gibbons and siamangs, in which these primates swing from tree limb to tree limb using only their arms. It is challenging to control because of the limited control authority, the required advance planning, and the precision of the required grasps. We present a novel approach to this problem using reinforcement learning, and as demonstrated on a finger-less 14-link planar model that learns to brachiate across challenging handhold sequences. Key to our method is the use of a simplified model, a point mass with a virtual arm, for which we first learn a policy that can brachiate across handhold sequences with a prescribed order. This facilitates the learning of the policy for the full model, for which it provides guidance by providing an overall center-of-mass trajectory to imitate, as well as for the timing of the holds. Lastly, the simplified model can also readily be used for planning suitable sequences of handholds in a given environment. Our results demonstrate brachiation motions with a variety of durations for the flight and hold phases, as well as emergent extra back-and-forth swings when this proves useful. The system is evaluated with a variety of ablations. The method enables future work towards more general 3D brachiation, as well as using simplified model imitation in other settings.
Evaluating Vision Transformer Methods for Deep Reinforcement Learning from Pixels
Apr 11, 2022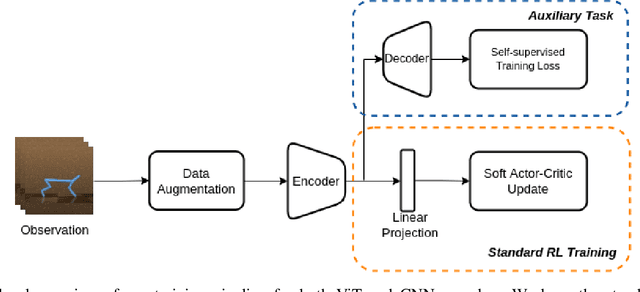
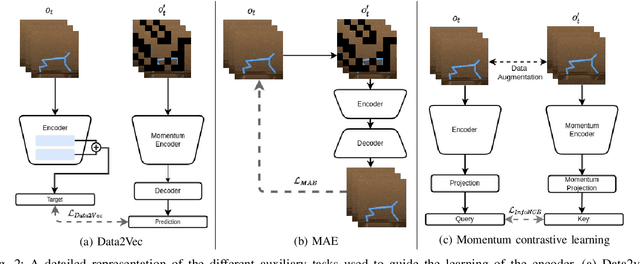
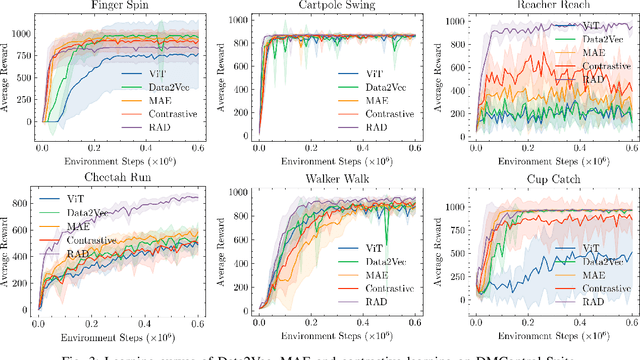
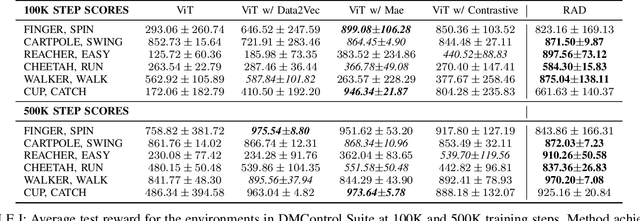
Vision Transformers (ViT) have recently demonstrated the significant potential of transformer architectures for computer vision. To what extent can image-based deep reinforcement learning also benefit from ViT architectures, as compared to standard convolutional neural network (CNN) architectures? To answer this question, we evaluate ViT training methods for image-based reinforcement learning (RL) control tasks and compare these results to a leading convolutional-network architecture method, RAD. For training the ViT encoder, we consider several recently-proposed self-supervised losses that are treated as auxiliary tasks, as well as a baseline with no additional loss terms. We find that the CNN architectures trained using RAD still generally provide superior performance. For the ViT methods, all three types of auxiliary tasks that we consider provide a benefit over plain ViT training. Furthermore, ViT masking-based tasks are found to significantly outperform ViT contrastive-learning.
Imagining The Road Ahead: Multi-Agent Trajectory Prediction via Differentiable Simulation
Apr 22, 2021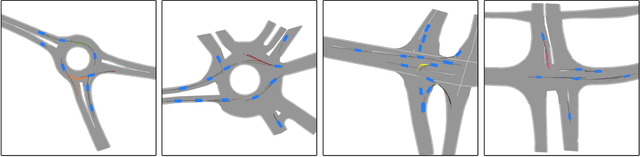
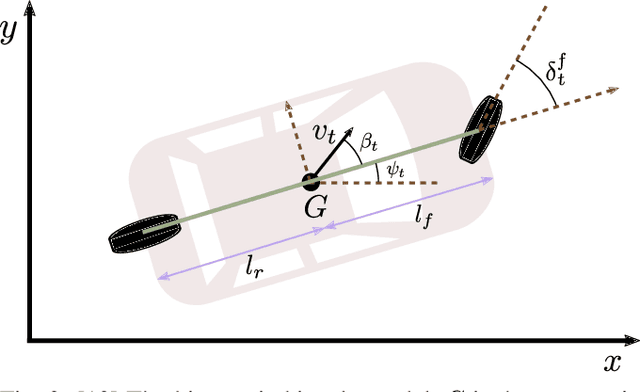
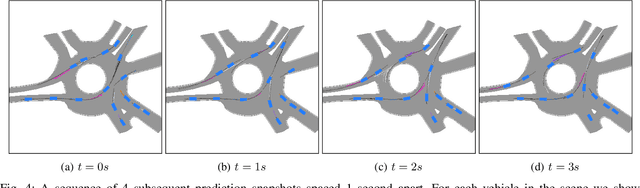
We develop a deep generative model built on a fully differentiable simulator for multi-agent trajectory prediction. Agents are modeled with conditional recurrent variational neural networks (CVRNNs), which take as input an ego-centric birdview image representing the current state of the world and output an action, consisting of steering and acceleration, which is used to derive the subsequent agent state using a kinematic bicycle model. The full simulation state is then differentiably rendered for each agent, initiating the next time step. We achieve state-of-the-art results on the INTERACTION dataset, using standard neural architectures and a standard variational training objective, producing realistic multi-modal predictions without any ad-hoc diversity-inducing losses. We conduct ablation studies to examine individual components of the simulator, finding that both the kinematic bicycle model and the continuous feedback from the birdview image are crucial for achieving this level of performance. We name our model ITRA, for "Imagining the Road Ahead".
Learning to Locomote: Understanding How Environment Design Matters for Deep Reinforcement Learning
Oct 09, 2020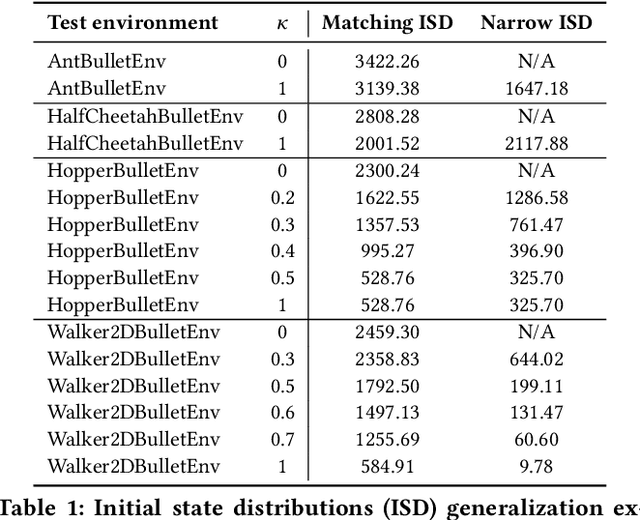
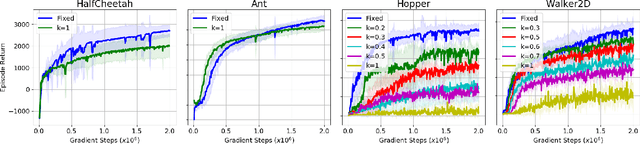


Learning to locomote is one of the most common tasks in physics-based animation and deep reinforcement learning (RL). A learned policy is the product of the problem to be solved, as embodied by the RL environment, and the RL algorithm. While enormous attention has been devoted to RL algorithms, much less is known about the impact of design choices for the RL environment. In this paper, we show that environment design matters in significant ways and document how it can contribute to the brittle nature of many RL results. Specifically, we examine choices related to state representations, initial state distributions, reward structure, control frequency, episode termination procedures, curriculum usage, the action space, and the torque limits. We aim to stimulate discussion around such choices, which in practice strongly impact the success of RL when applied to continuous-action control problems of interest to animation, such as learning to locomote.
Urban Driving with Conditional Imitation Learning
Dec 05, 2019



Hand-crafting generalised decision-making rules for real-world urban autonomous driving is hard. Alternatively, learning behaviour from easy-to-collect human driving demonstrations is appealing. Prior work has studied imitation learning (IL) for autonomous driving with a number of limitations. Examples include only performing lane-following rather than following a user-defined route, only using a single camera view or heavily cropped frames lacking state observability, only lateral (steering) control, but not longitudinal (speed) control and a lack of interaction with traffic. Importantly, the majority of such systems have been primarily evaluated in simulation - a simple domain, which lacks real-world complexities. Motivated by these challenges, we focus on learning representations of semantics, geometry and motion with computer vision for IL from human driving demonstrations. As our main contribution, we present an end-to-end conditional imitation learning approach, combining both lateral and longitudinal control on a real vehicle for following urban routes with simple traffic. We address inherent dataset bias by data balancing, training our final policy on approximately 30 hours of demonstrations gathered over six months. We evaluate our method on an autonomous vehicle by driving 35km of novel routes in European urban streets.