 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagining The Road Ahead: Multi-Agent Trajectory Prediction via Differentiable Simulation
Paper and Code
Apr 22, 2021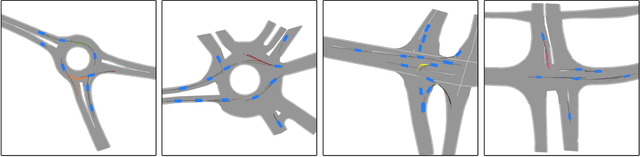
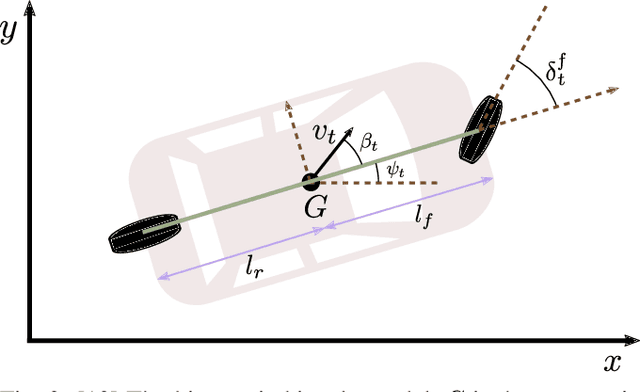
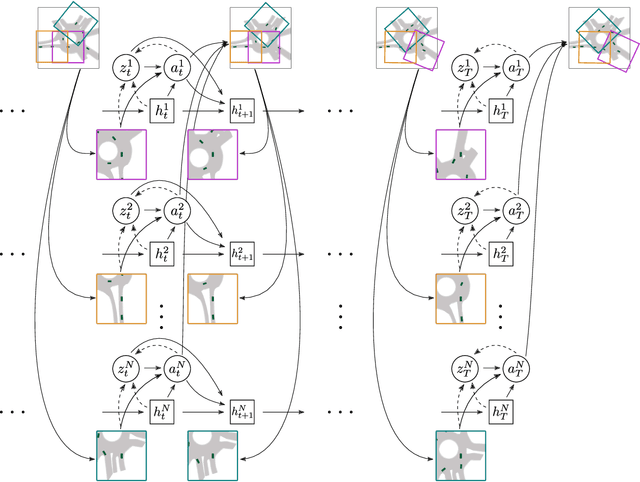
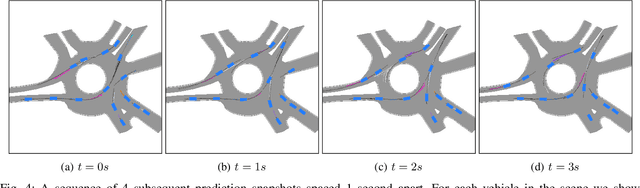
We develop a deep generative model built on a fully differentiable simulator for multi-agent trajectory prediction. Agents are modeled with conditional recurrent variational neural networks (CVRNNs), which take as input an ego-centric birdview image representing the current state of the world and output an action, consisting of steering and acceleration, which is used to derive the subsequent agent state using a kinematic bicycle model. The full simulation state is then differentiably rendered for each agent, initiating the next time step. We achieve state-of-the-art results on the INTERACTION dataset, using standard neural architectures and a standard variational training objective, producing realistic multi-modal predictions without any ad-hoc diversity-inducing losses. We conduct ablation studies to examine individual components of the simulator, finding that both the kinematic bicycle model and the continuous feedback from the birdview image are crucial for achieving this level of performance. We name our model ITRA, for "Imagining the Road Ahead".