 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReimagining an autonomous vehicle
Aug 12, 2021
The self driving challenge in 2021 is this century's technological equivalent of the space race, and is now entering the second major decade of development. Solving the technology will create social change which parallels the invention of the automobile itself. Today's autonomous driving technology is laudable, though rooted in decisions made a decade ago. We argue that a rethink is required, reconsidering the autonomous vehicle (AV) problem in the light of the body of knowledge that has been gained since the DARPA challenges which seeded the industry. What does AV2.0 look like? We present an alternative vision: a recipe for driving with machine learning, and grand challenges for research in driving.
Urban Driving with Conditional Imitation Learning
Dec 05, 2019



Hand-crafting generalised decision-making rules for real-world urban autonomous driving is hard. Alternatively, learning behaviour from easy-to-collect human driving demonstrations is appealing. Prior work has studied imitation learning (IL) for autonomous driving with a number of limitations. Examples include only performing lane-following rather than following a user-defined route, only using a single camera view or heavily cropped frames lacking state observability, only lateral (steering) control, but not longitudinal (speed) control and a lack of interaction with traffic. Importantly, the majority of such systems have been primarily evaluated in simulation - a simple domain, which lacks real-world complexities. Motivated by these challenges, we focus on learning representations of semantics, geometry and motion with computer vision for IL from human driving demonstrations. As our main contribution, we present an end-to-end conditional imitation learning approach, combining both lateral and longitudinal control on a real vehicle for following urban routes with simple traffic. We address inherent dataset bias by data balancing, training our final policy on approximately 30 hours of demonstrations gathered over six months. We evaluate our method on an autonomous vehicle by driving 35km of novel routes in European urban streets.
Learning to Drive from Simulation without Real World Labels
Dec 13, 2018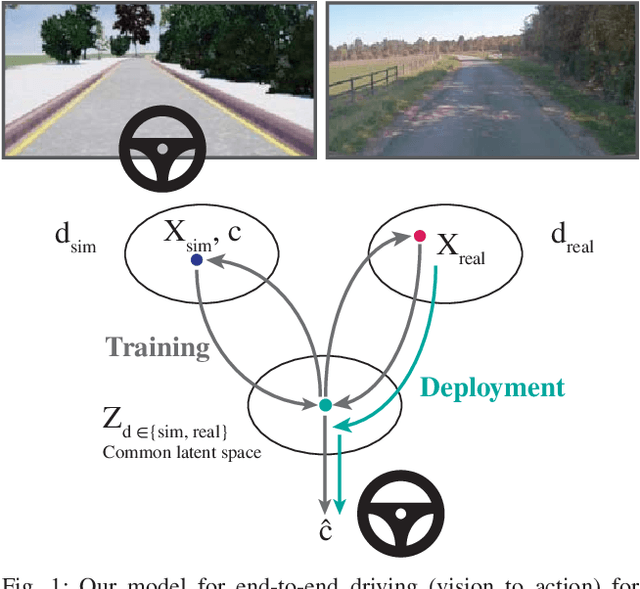
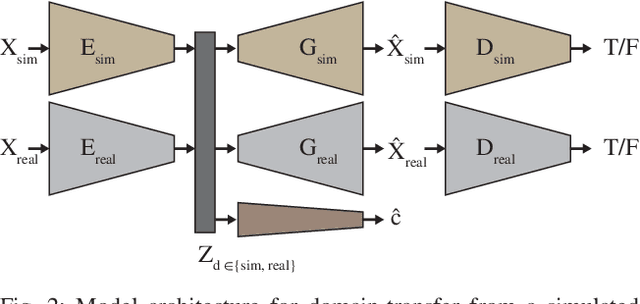
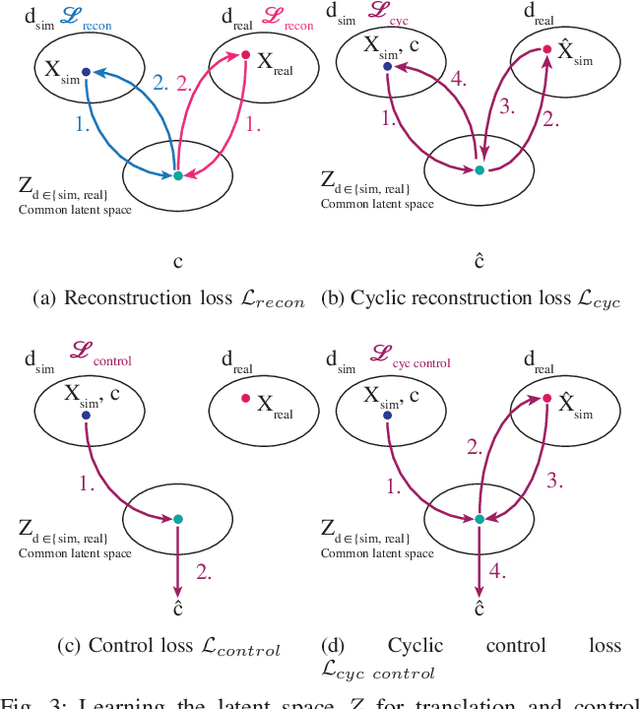

Simulation can be a powerful tool for understanding machine learning systems and designing methods to solve real-world problems. Training and evaluating methods purely in simulation is often "doomed to succeed" at the desired task in a simulated environment, but the resulting models are incapable of operation in the real world. Here we present and evaluate a method for transferring a vision-based lane following driving policy from simulation to operation on a rural road without any real-world labels. Our approach leverages recent advances in image-to-image translation to achieve domain transfer while jointly learning a single-camera control policy from simulation control labels. We assess the driving performance of this method using both open-loop regression metrics, and closed-loop performance operating an autonomous vehicle on rural and urban roads.
Learning to Drive in a Day
Sep 11, 2018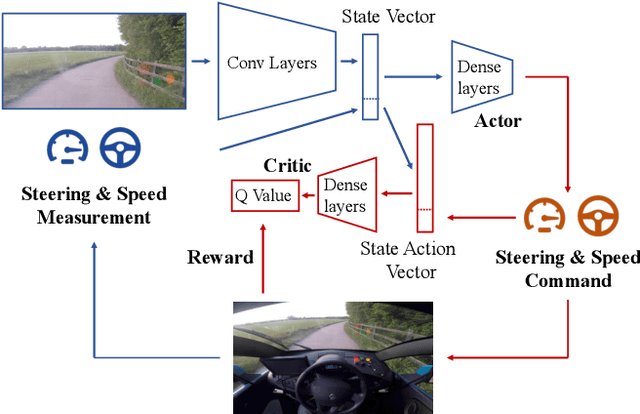

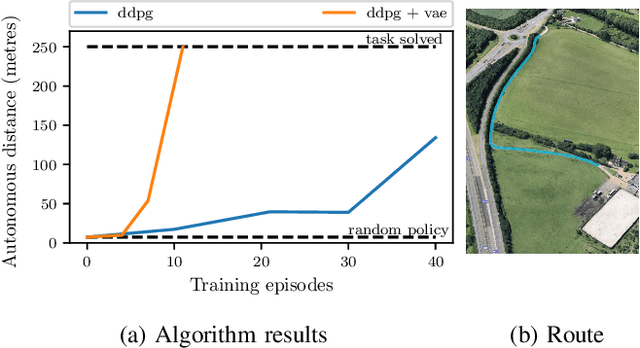
We demonstrate the first application of deep reinforcement learning to autonomous driving. From randomly initialised parameters, our model is able to learn a policy for lane following in a handful of training episodes using a single monocular image as input. We provide a general and easy to obtain reward: the distance travelled by the vehicle without the safety driver taking control. We use a continuous, model-free deep reinforcement learning algorithm, with all exploration and optimisation performed on-vehicle. This demonstrates a new framework for autonomous driving which moves away from reliance on defined logical rules, mapping, and direct supervision. We discuss the challenges and opportunities to scale this approach to a broader range of autonomous driving tasks.
What Makes a Place? Building Bespoke Place Dependent Object Detectors for Robotics
Aug 07, 2017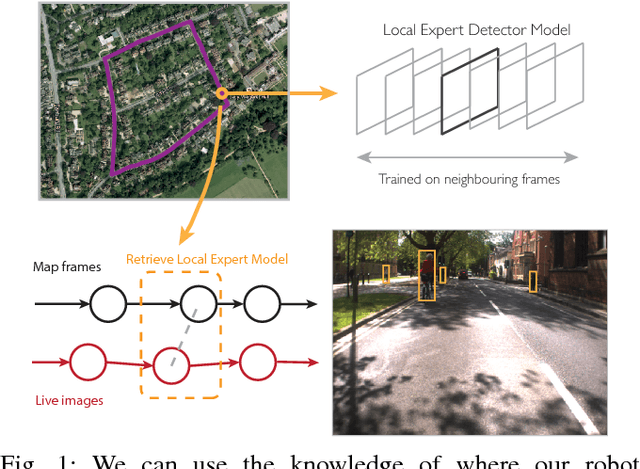

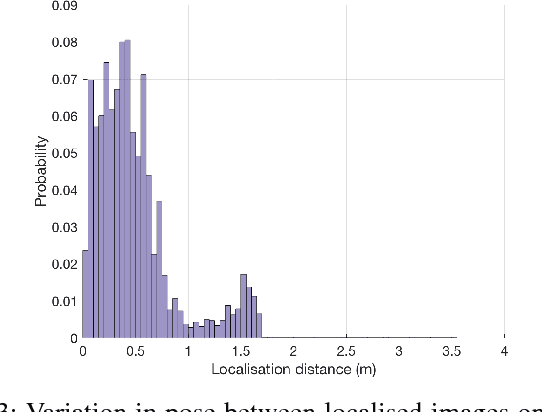
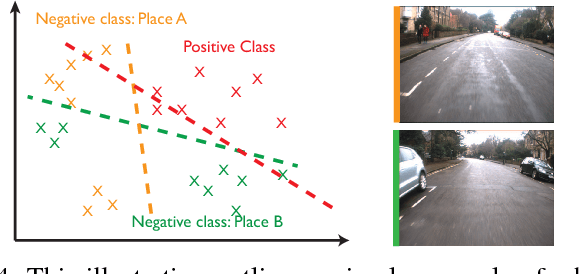
This paper is about enabling robots to improve their perceptual performance through repeated use in their operating environment, creating local expert detectors fitted to the places through which a robot moves. We leverage the concept of 'experiences' in visual perception for robotics, accounting for bias in the data a robot sees by fitting object detector models to a particular place. The key question we seek to answer in this paper is simply: how do we define a place? We build bespoke pedestrian detector models for autonomous driving, highlighting the necessary trade off between generalisation and model capacity as we vary the extent of the place we fit to. We demonstrate a sizeable performance gain over a current state-of-the-art detector when using computationally lightweight bespoke place-fitted detector models.