 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Crowd Counting via Modal Emulation
Jul 28, 2024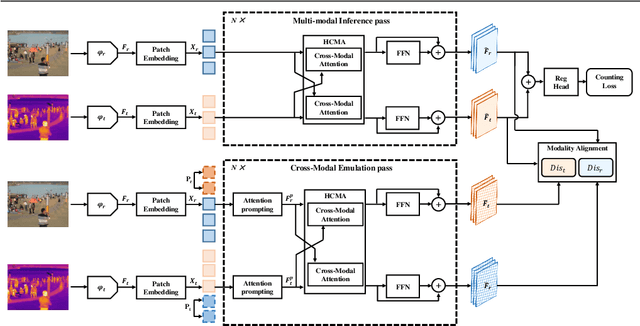
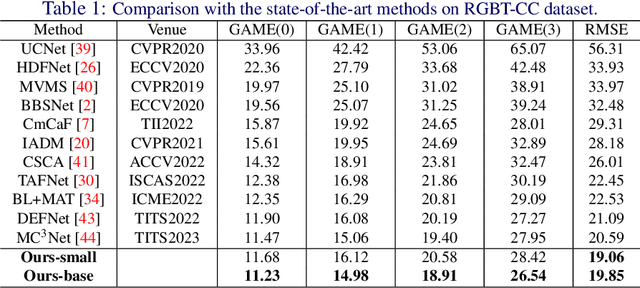
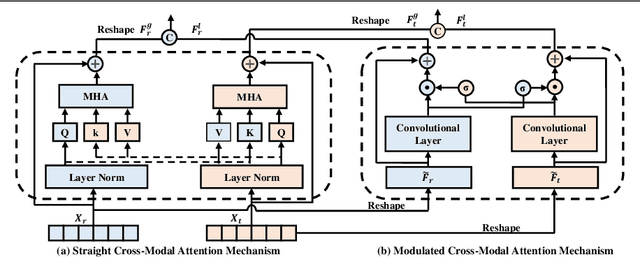
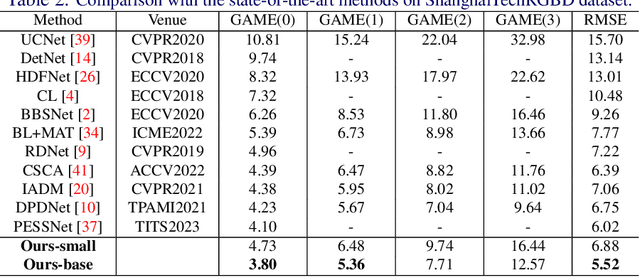
Multi-modal crowd counting is a crucial task that uses multi-modal cues to estimate the number of people in crowded scenes. To overcome the gap between different modalities, we propose a modal emulation-based two-pass multi-modal crowd-counting framework that enables efficient modal emulation, alignment, and fusion. The framework consists of two key components: a \emph{multi-modal inference} pass and a \emph{cross-modal emulation} pass. The former utilizes a hybrid cross-modal attention module to extract global and local information and achieve efficient multi-modal fusion. The latter uses attention prompting to coordinate different modalities and enhance multi-modal alignment. We also introduce a modality alignment module that uses an efficient modal consistency loss to align the outputs of the two passes and bridge the semantic gap between modalities. Extensive experiments on both RGB-Thermal and RGB-Depth counting datasets demonstrate its superior performance compared to previous methods. Code available at https://github.com/Mr-Monday/Multi-modal-Crowd-Counting-via-Modal-Emulation.