 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCA: Dividing and Conquering Amnesia in Incremental Object Detection
Mar 19, 2025Incremental object detection (IOD) aims to cultivate an object detector that can continuously localize and recognize novel classes while preserving its performance on previous classes. Existing methods achieve certain success by improving knowledge distillation and exemplar replay for transformer-based detection frameworks, but the intrinsic forgetting mechanisms remain underexplored. In this paper, we dive into the cause of forgetting and discover forgetting imbalance between localization and recognition in transformer-based IOD, which means that localization is less-forgetting and can generalize to future classes, whereas catastrophic forgetting occurs primarily on recognition. Based on these insights, we propose a Divide-and-Conquer Amnesia (DCA) strategy, which redesigns the transformer-based IOD into a localization-then-recognition process. DCA can well maintain and transfer the localization ability, leaving decoupled fragile recognition to be specially conquered. To reduce feature drift in recognition, we leverage semantic knowledge encoded in pre-trained language models to anchor class representations within a unified feature space across incremental tasks. This involves designing a duplex classifier fusion and embedding class semantic features into the recognition decoding process in the form of queries. Extensive experiments validate that our approach achieves state-of-the-art performance, especially for long-term incremental scenarios. For example, under the four-step setting on MS-COCO, our DCA strategy significantly improves the final AP by 6.9%.
Dense Semantic Contrast for Self-Supervised Visual Representation Learning
Sep 16, 2021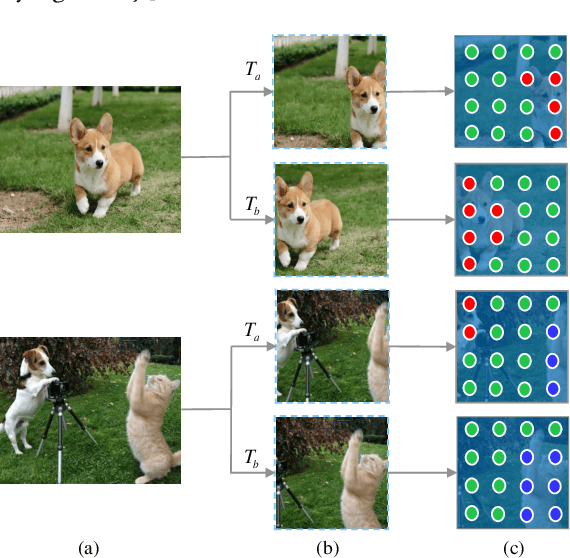
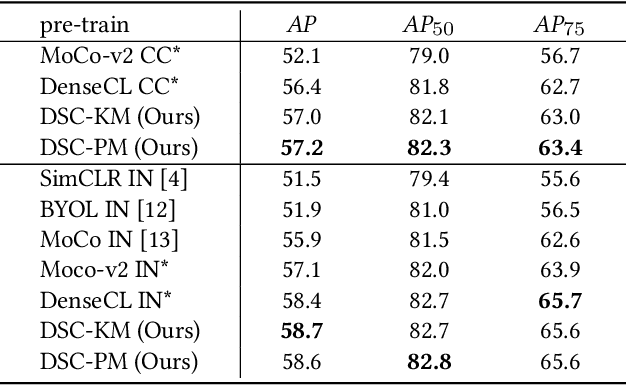
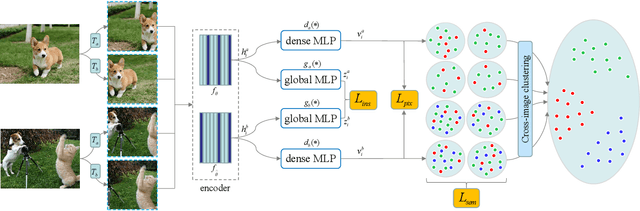
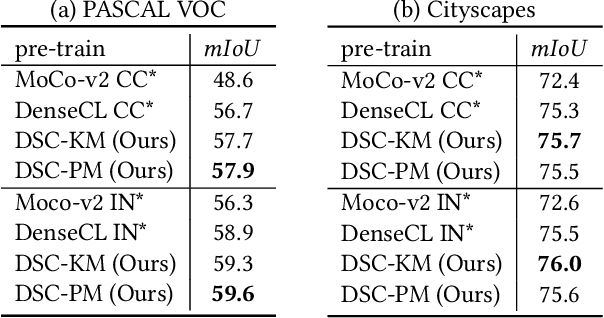
Self-supervised representation learning for visual pre-training has achieved remarkable success with sample (instance or pixel) discrimination and semantics discovery of instance, whereas there still exists a non-negligible gap between pre-trained model and downstream dense prediction tasks. Concretely, these downstream tasks require more accurate representation, in other words, the pixels from the same object must belong to a shared semantic category, which is lacking in the previous methods. In this work, we present Dense Semantic Contrast (DSC) for modeling semantic category decision boundaries at a dense level to meet the requirement of these tasks. Furthermore, we propose a dense cross-image semantic contrastive learning framework for multi-granularity representation learning. Specially, we explicitly explore the semantic structure of the dataset by mining relations among pixels from different perspectives. For intra-image relation modeling, we discover pixel neighbors from multiple views. And for inter-image relations, we enforce pixel representation from the same semantic class to be more similar than the representation from different classes in one mini-batch. Experimental results show that our DSC model outperforms state-of-the-art methods when transferring to downstream dense prediction tasks, including object detection, semantic segmentation, and instance segmentation. Code will be made available.