 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spiking Point Mamba for Point Cloud Analysis
Apr 19, 2025Bio-inspired Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. However, existing 3D SNNs have struggled with long-range dependencies until the recent emergence of Mamba, which offers superior computational efficiency and sequence modeling capability. In this work, we propose Spiking Point Mamba (SPM), the first Mamba-based SNN in the 3D domain. Due to the poor performance of simply transferring Mamba to 3D SNNs, SPM is designed to utilize both the sequence modeling capabilities of Mamba and the temporal feature extraction of SNNs. Specifically, we first introduce Hierarchical Dynamic Encoding (HDE), an improved direct encoding method that effectively introduces dynamic temporal mechanism, thereby facilitating temporal interactions. Then, we propose a Spiking Mamba Block (SMB), which builds upon Mamba while learning inter-time-step features and minimizing information loss caused by spikes. Finally, to further enhance model performance, we adopt an asymmetric SNN-ANN architecture for spike-based pre-training and finetune. Compared with the previous state-of-the-art SNN models, SPM improves OA by +6.2%, +6.1%, and +7.4% on three variants of ScanObjectNN, and boosts instance mIOU by +1.9% on ShapeNetPart. Meanwhile, its energy consumption is at least 3.5x lower than that of its ANN counterpart. The code will be made publicly available.
Spiking Point Transformer for Point Cloud Classification
Feb 19, 2025Spiking Neural Networks (SNNs) offer an attractive and energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their sparse binary activation. When SNN meets Transformer, it shows great potential in 2D image processing. However, their application for 3D point cloud remains underexplored. To this end, we present Spiking Point Transformer (SPT), the first transformer-based SNN framework for point cloud classification. Specifically, we first design Queue-Driven Sampling Direct Encoding for point cloud to reduce computational costs while retaining the most effective support points at each time step. We introduce the Hybrid Dynamics Integrate-and-Fire Neuron (HD-IF), designed to simulate selective neuron activation and reduce over-reliance on specific artificial neurons. SPT attains state-of-the-art results on three benchmark datasets that span both real-world and synthetic datasets in the SNN domain. Meanwhile, the theoretical energy consumption of SPT is at least 6.4$\times$ less than its ANN counterpart.
Heterogeneous window transformer for image denoising
Jul 08, 2024Deep networks can usually depend on extracting more structural information to improve denoising results. However, they may ignore correlation between pixels from an image to pursue better denoising performance. Window transformer can use long- and short-distance modeling to interact pixels to address mentioned problem. To make a tradeoff between distance modeling and denoising time, we propose a heterogeneous window transformer (HWformer) for image denoising. HWformer first designs heterogeneous global windows to capture global context information for improving denoising effects. To build a bridge between long and short-distance modeling, global windows are horizontally and vertically shifted to facilitate diversified information without increasing denoising time. To prevent the information loss phenomenon of independent patches, sparse idea is guided a feed-forward network to extract local information of neighboring patches. The proposed HWformer only takes 30% of popular Restormer in terms of denoising time.
A self-supervised CNN for image watermark removal
Mar 09, 2024



Popular convolutional neural networks mainly use paired images in a supervised way for image watermark removal. However, watermarked images do not have reference images in the real world, which results in poor robustness of image watermark removal techniques. In this paper, we propose a self-supervised convolutional neural network (CNN) in image watermark removal (SWCNN). SWCNN uses a self-supervised way to construct reference watermarked images rather than given paired training samples, according to watermark distribution. A heterogeneous U-Net architecture is used to extract more complementary structural information via simple components for image watermark removal. Taking into account texture information, a mixed loss is exploited to improve visual effects of image watermark removal. Besides, a watermark dataset is conducted. Experimental results show that the proposed SWCNN is superior to popular CNNs in image watermark removal.
Perceptive self-supervised learning network for noisy image watermark removal
Mar 04, 2024Popular methods usually use a degradation model in a supervised way to learn a watermark removal model. However, it is true that reference images are difficult to obtain in the real world, as well as collected images by cameras suffer from noise. To overcome these drawbacks, we propose a perceptive self-supervised learning network for noisy image watermark removal (PSLNet) in this paper. PSLNet depends on a parallel network to remove noise and watermarks. The upper network uses task decomposition ideas to remove noise and watermarks in sequence. The lower network utilizes the degradation model idea to simultaneously remove noise and watermarks. Specifically, mentioned paired watermark images are obtained in a self supervised way, and paired noisy images (i.e., noisy and reference images) are obtained in a supervised way. To enhance the clarity of obtained images, interacting two sub-networks and fusing obtained clean images are used to improve the effects of image watermark removal in terms of structural information and pixel enhancement. Taking into texture information account, a mixed loss uses obtained images and features to achieve a robust model of noisy image watermark removal. Comprehensive experiments show that our proposed method is very effective in comparison with popular convolutional neural networks (CNNs) for noisy image watermark removal. Codes can be obtained at https://github.com/hellloxiaotian/PSLNet.
A cross Transformer for image denoising
Oct 16, 2023
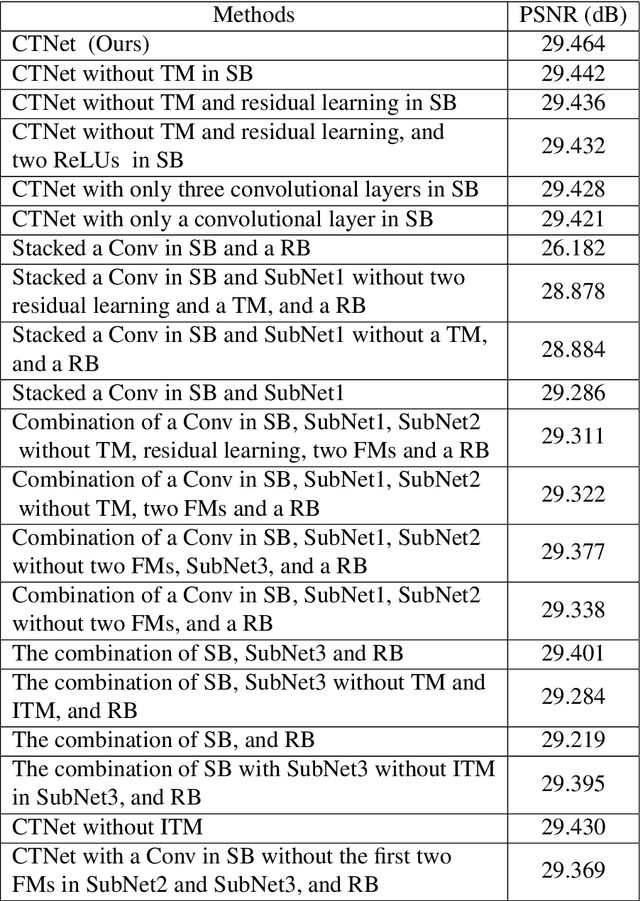
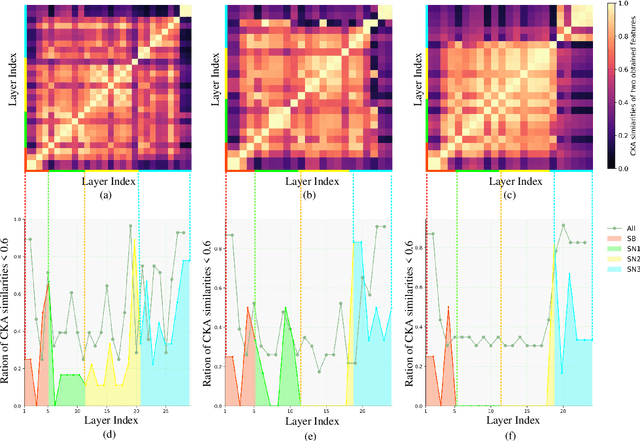

Deep convolutional neural networks (CNNs) depend on feedforward and feedback ways to obtain good performance in image denoising. However, how to obtain effective structural information via CNNs to efficiently represent given noisy images is key for complex scenes. In this paper, we propose a cross Transformer denoising CNN (CTNet) with a serial block (SB), a parallel block (PB), and a residual block (RB) to obtain clean images for complex scenes. A SB uses an enhanced residual architecture to deeply search structural information for image denoising. To avoid loss of key information, PB uses three heterogeneous networks to implement multiple interactions of multi-level features to broadly search for extra information for improving the adaptability of an obtained denoiser for complex scenes. Also, to improve denoising performance, Transformer mechanisms are embedded into the SB and PB to extract complementary salient features for effectively removing noise in terms of pixel relations. Finally, a RB is applied to acquire clean images. Experiments illustrate that our CTNet is superior to some popular denoising methods in terms of real and synthetic image denoising. It is suitable to mobile digital devices, i.e., phones. Codes can be obtained at https://github.com/hellloxiaotian/CTNet.
Multi-stage image denoising with the wavelet transform
Oct 03, 2022



Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and a residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.