 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Adaptive Sparse Transformer for Event-based Object Detection
Paper and Code
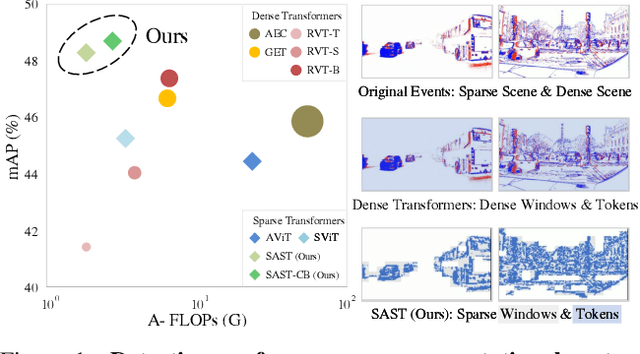
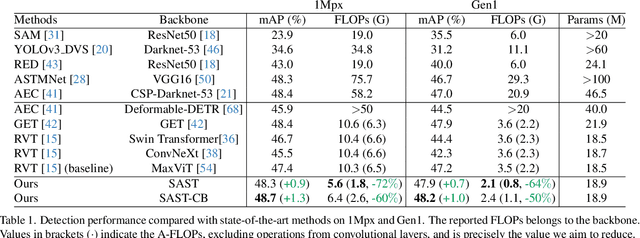
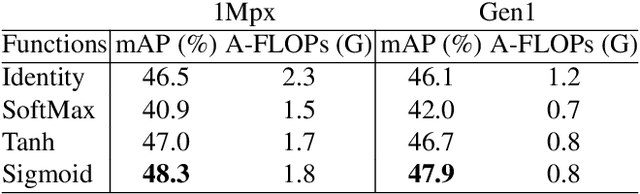
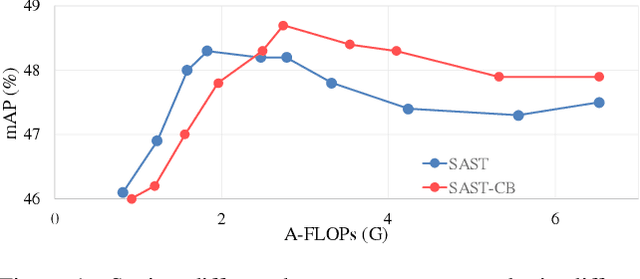
While recent Transformer-based approaches have shown impressive performances on event-based object detection tasks, their high computational costs still diminish the low power consumption advantage of event cameras. Image-based works attempt to reduce these costs by introducing sparse Transformers. However, they display inadequate sparsity and adaptability when applied to event-based object detection, since these approaches cannot balance the fine granularity of token-level sparsification and the efficiency of window-based Transformers, leading to reduced performance and efficiency. Furthermore, they lack scene-specific sparsity optimization, resulting in information loss and a lower recall rate. To overcome these limitations, we propose the Scene Adaptive Sparse Transformer (SAST). SAST enables window-token co-sparsification, significantly enhancing fault tolerance and reducing computational overhead. Leveraging the innovative scoring and selection modules, along with the Masked Sparse Window Self-Attention, SAST showcases remarkable scene-aware adaptability: It focuses only on important objects and dynamically optimizes sparsity level according to scene complexity, maintaining a remarkable balance between performance and computational cost. The evaluation results show that SAST outperforms all other dense and sparse networks in both performance and efficiency on two large-scale event-based object detection datasets (1Mpx and Gen1). Code: https://github.com/Peterande/SAST