 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Tracking Representations via Dual-Branch Fully Transformer Networks
Paper and Code
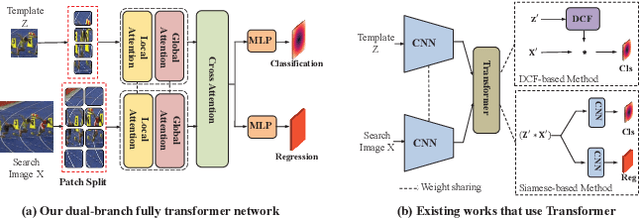

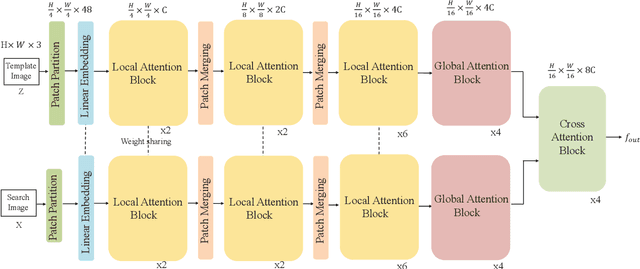
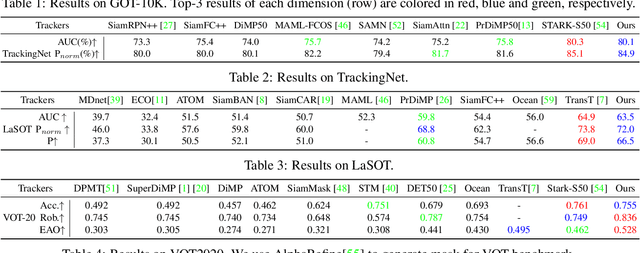
We present a Siamese-like Dual-branch network based on solely Transformers for tracking. Given a template and a search image, we divide them into non-overlapping patches and extract a feature vector for each patch based on its matching results with others within an attention window. For each token, we estimate whether it contains the target object and the corresponding size. The advantage of the approach is that the features are learned from matching, and ultimately, for matching. So the features are aligned with the object tracking task. The method achieves better or comparable results as the best-performing methods which first use CNN to extract features and then use Transformer to fuse them. It outperforms the state-of-the-art methods on the GOT-10k and VOT2020 benchmarks. In addition, the method achieves real-time inference speed (about $40$ fps) on one GPU. The code and models will be released.