 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Speculative Decoding: Frequency-Guided Candidate Selection for Efficient Inference
Apr 15, 2026Speculative decoding accelerates autoregressive generation by letting draft tokens bypass full verification, but conventional frameworks suffer from frequent false rejections, particularly when draft models produce semantically correct but lexically divergent outputs. In this paper, we present Calibrated Speculative Decoding (CSD), a training-free framework that recovers valid tokens discarded by standard verification. Guided by the principle of "Frequency-Guided Candidate Selection and Probability-Guarded Acceptance," CSD incorporates two lightweight modules: Online Correction Memory, which aggregates historical rejections to propose recurring divergence patterns as rescue candidates, and Semantic Consistency Gating, which verifies candidate admissibility using probability ratios instead of exact token matching. Our evaluation across diverse large language models demonstrates that CSD outperforms existing methods, achieving a peak throughput speedup of 2.33x. CSD preserves model accuracy across all tasks while further boosting performance on complex reasoning datasets. These results establish CSD as a highly effective, lightweight solution for practical LLM deployments.
HyperOffload: Graph-Driven Hierarchical Memory Management for Large Language Models on SuperNode Architectures
Feb 03, 2026The rapid evolution of Large Language Models (LLMs) towards long-context reasoning and sparse architectures has pushed memory requirements far beyond the capacity of individual device HBM. While emerging supernode architectures offer terabyte-scale shared memory pools via high-bandwidth interconnects, existing software stacks fail to exploit this hardware effectively. Current runtime-based offloading and swapping techniques operate with a local view, leading to reactive scheduling and exposed communication latency that stall the computation pipeline. In this paper, we propose the SuperNode Memory Management Framework (\textbf{HyperOffload}). It employs a compiler-assisted approach that leverages graph-driven memory management to treat remote memory access as explicit operations in the computation graph, specifically designed for hierarchical SuperNode architectures. Unlike reactive runtime systems, SuperNode represents data movement using cache operators within the compiler's Intermediate Representation (IR). This design enables a global, compile-time analysis of tensor lifetimes and execution dependencies. Leveraging this visibility, we develop a global execution-order refinement algorithm that statically schedules data transfers to hide remote memory latency behind compute-intensive regions. We implement SuperNode within the production deep learning framework MindSpore, adding a remote memory backend and specialized compiler passes. Evaluation on representative LLM workloads shows that SuperNode reduces peak device memory usage by up to 26\% for inference while maintaining end-to-end performance. Our work demonstrates that integrating memory-augmented hardware into the compiler's optimization framework is essential for scaling next-generation AI workloads.
SpecQuant: Spectral Decomposition and Adaptive Truncation for Ultra-Low-Bit LLMs Quantization
Nov 11, 2025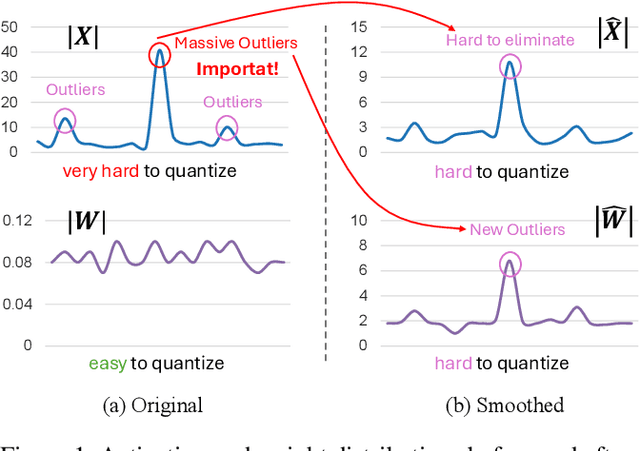
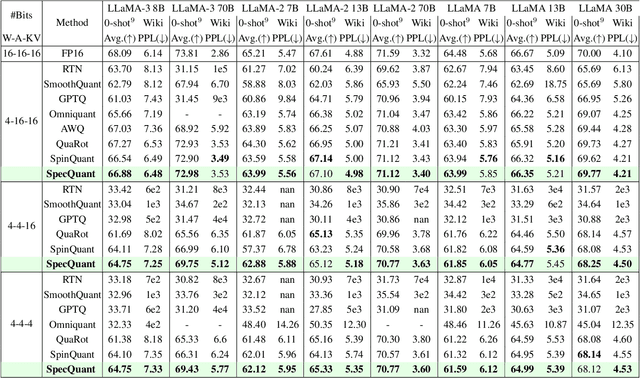
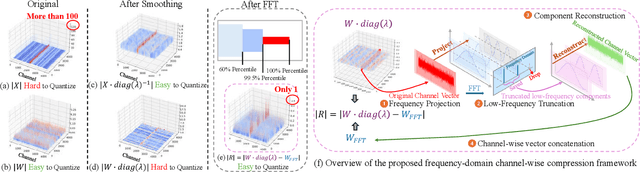
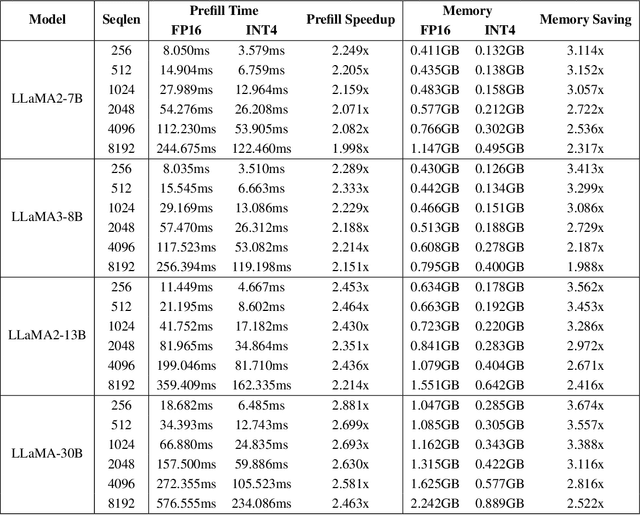
The emergence of accurate open large language models (LLMs) has sparked a push for advanced quantization techniques to enable efficient deployment on end-user devices. In this paper, we revisit the challenge of extreme LLM compression -- targeting ultra-low-bit quantization for both activations and weights -- from a Fourier frequency domain perspective. We propose SpecQuant, a two-stage framework that tackles activation outliers and cross-channel variance. In the first stage, activation outliers are smoothed and transferred into the weight matrix to simplify downstream quantization. In the second stage, we apply channel-wise low-frequency Fourier truncation to suppress high-frequency components while preserving essential signal energy, improving quantization robustness. Our method builds on the principle that most of the weight energy is concentrated in low-frequency components, which can be retained with minimal impact on model accuracy. To enable runtime adaptability, we introduce a lightweight truncation module during inference that adjusts truncation thresholds based on channel characteristics. On LLaMA-3 8B, SpecQuant achieves 4-bit quantization for both weights and activations, narrowing the zero-shot accuracy gap to only 1.5% compared to full precision, while delivering 2 times faster inference and 3times lower memory usage.
QUARK: Quantization-Enabled Circuit Sharing for Transformer Acceleration by Exploiting Common Patterns in Nonlinear Operations
Nov 10, 2025Transformer-based models have revolutionized computer vision (CV) and natural language processing (NLP) by achieving state-of-the-art performance across a range of benchmarks. However, nonlinear operations in models significantly contribute to inference latency, presenting unique challenges for efficient hardware acceleration. To this end, we propose QUARK, a quantization-enabled FPGA acceleration framework that leverages common patterns in nonlinear operations to enable efficient circuit sharing, thereby reducing hardware resource requirements. QUARK targets all nonlinear operations within Transformer-based models, achieving high-performance approximation through a novel circuit-sharing design tailored to accelerate these operations. Our evaluation demonstrates that QUARK significantly reduces the computational overhead of nonlinear operators in mainstream Transformer architectures, achieving up to a 1.96 times end-to-end speedup over GPU implementations. Moreover, QUARK lowers the hardware overhead of nonlinear modules by more than 50% compared to prior approaches, all while maintaining high model accuracy -- and even substantially boosting accuracy under ultra-low-bit quantization.
Flexible Operator Fusion for Fast Sparse Transformer with Diverse Masking on GPU
Jun 06, 2025Large language models are popular around the world due to their powerful understanding capabilities. As the core component of LLMs, accelerating Transformer through parallelization has gradually become a hot research topic. Mask layers introduce sparsity into Transformer to reduce calculations. However, previous works rarely focus on the performance optimization of sparse Transformer. Moreover, rule-based mechanisms ignore the fusion opportunities of mixed-type operators and fail to adapt to various sequence lengths. To address the above problems, we propose STOF, a framework that incorporates optimizations for Sparse Transformer via flexible masking and operator fusion on GPU. We firstly unify the storage format and kernel implementation for the multi-head attention. Then, we map fusion schemes to compilation templates and determine the optimal parameter setting through a two-stage search engine. The experimental results show that compared to the state-of-the-art work, STOF achieves maximum speedups of 1.7x in MHA computation and 1.5x in end-to-end inference.
DASH: Input-Aware Dynamic Layer Skipping for Efficient LLM Inference with Markov Decision Policies
May 23, 2025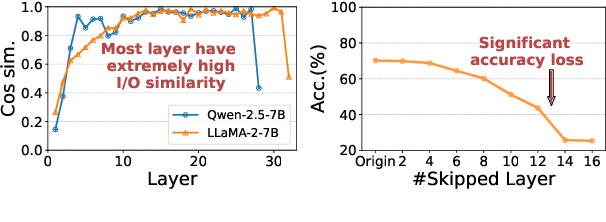
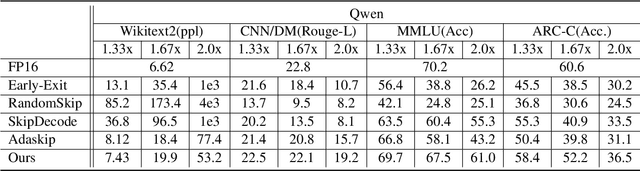
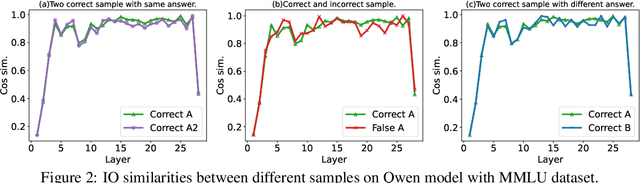
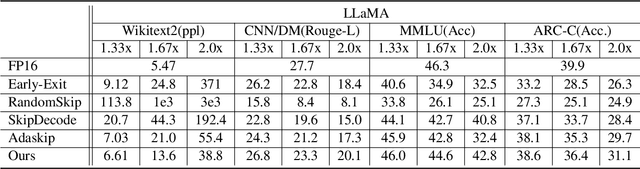
Large language models (LLMs) have achieved remarkable performance across a wide range of NLP tasks. However, their substantial inference cost poses a major barrier to real-world deployment, especially in latency-sensitive scenarios. To address this challenge, we propose \textbf{DASH}, an adaptive layer-skipping framework that dynamically selects computation paths conditioned on input characteristics. We model the skipping process as a Markov Decision Process (MDP), enabling fine-grained token-level decisions based on intermediate representations. To mitigate potential performance degradation caused by skipping, we introduce a lightweight compensation mechanism that injects differential rewards into the decision process. Furthermore, we design an asynchronous execution strategy that overlaps layer computation with policy evaluation to minimize runtime overhead. Experiments on multiple LLM architectures and NLP benchmarks show that our method achieves significant inference acceleration while maintaining competitive task performance, outperforming existing methods.
Phantom: Constraining Generative Artificial Intelligence Models for Practical Domain Specific Peripherals Trace Synthesizing
Nov 10, 2024

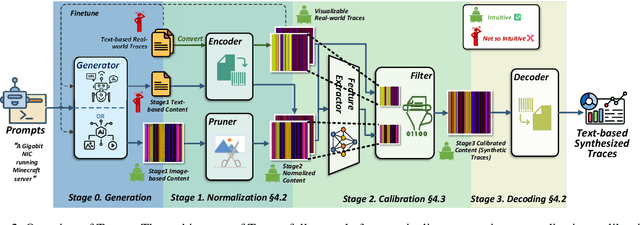

Peripheral Component Interconnect Express (PCIe) is the de facto interconnect standard for high-speed peripherals and CPUs. Prototyping and optimizing PCIe devices for emerging scenarios is an ongoing challenge. Since Transaction Layer Packets (TLPs) capture device-CPU interactions, it is crucial to analyze and generate realistic TLP traces for effective device design and optimization. Generative AI offers a promising approach for creating intricate, custom TLP traces necessary for PCIe hardware and software development. However, existing models often generate impractical traces due to the absence of PCIe-specific constraints, such as TLP ordering and causality. This paper presents Phantom, the first framework that treats TLP trace generation as a generative AI problem while incorporating PCIe-specific constraints. We validate Phantom's effectiveness by generating TLP traces for an actual PCIe network interface card. Experimental results show that Phantom produces practical, large-scale TLP traces, significantly outperforming existing models, with improvements of up to 1000$\times$ in task-specific metrics and up to 2.19$\times$ in Frechet Inception Distance (FID) compared to backbone-only methods.
DVHN: A Deep Hashing Framework for Large-scale Vehicle Re-identification
Dec 09, 2021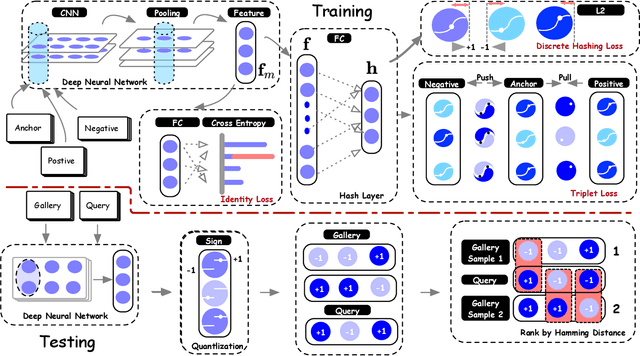
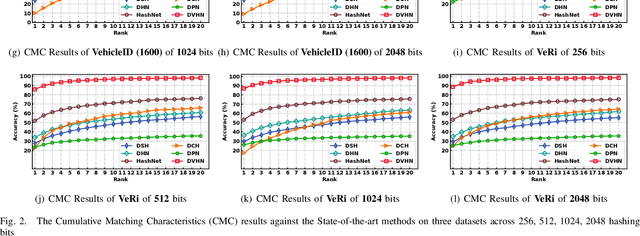
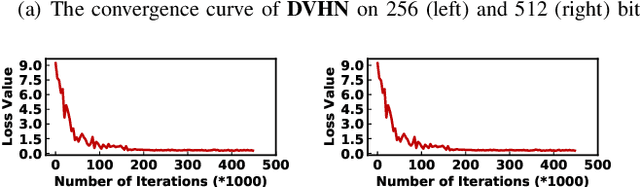
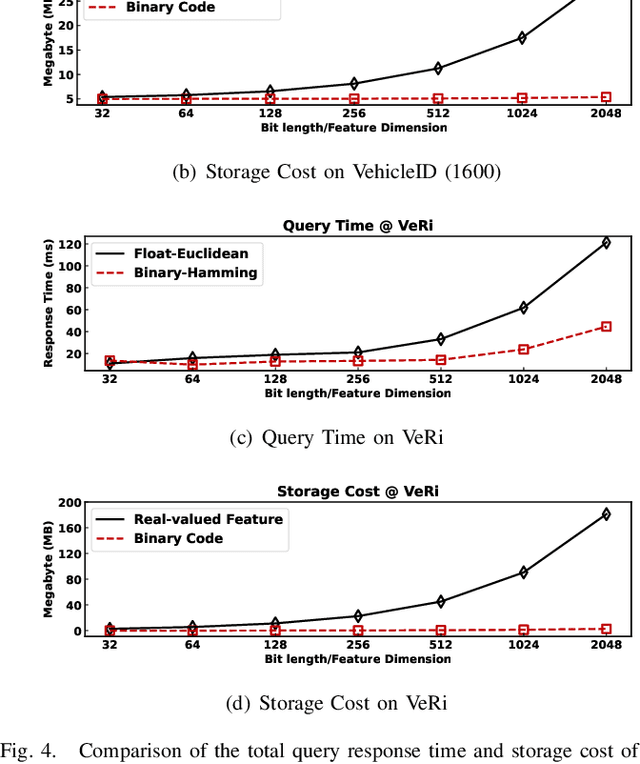
In this paper, we make the very first attempt to investigate the integration of deep hash learning with vehicle re-identification. We propose a deep hash-based vehicle re-identification framework, dubbed DVHN, which substantially reduces memory usage and promotes retrieval efficiency while reserving nearest neighbor search accuracy. Concretely,~DVHN directly learns discrete compact binary hash codes for each image by jointly optimizing the feature learning network and the hash code generating module. Specifically, we directly constrain the output from the convolutional neural network to be discrete binary codes and ensure the learned binary codes are optimal for classification. To optimize the deep discrete hashing framework, we further propose an alternating minimization method for learning binary similarity-preserved hashing codes. Extensive experiments on two widely-studied vehicle re-identification datasets- \textbf{VehicleID} and \textbf{VeRi}-~have demonstrated the superiority of our method against the state-of-the-art deep hash methods. \textbf{DVHN} of $2048$ bits can achieve 13.94\% and 10.21\% accuracy improvement in terms of \textbf{mAP} and \textbf{Rank@1} for \textbf{VehicleID (800)} dataset. For \textbf{VeRi}, we achieve 35.45\% and 32.72\% performance gains for \textbf{Rank@1} and \textbf{mAP}, respectively.
TransHash: Transformer-based Hamming Hashing for Efficient Image Retrieval
May 05, 2021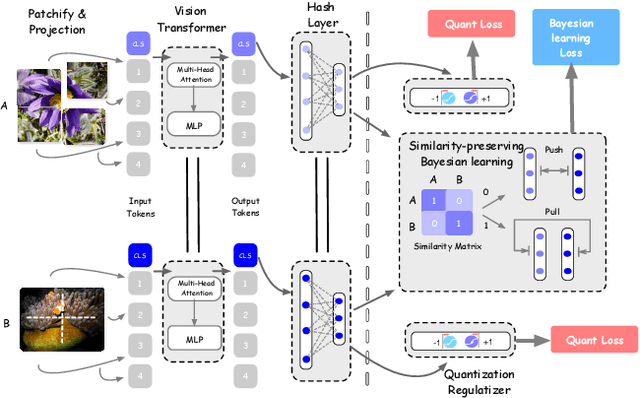
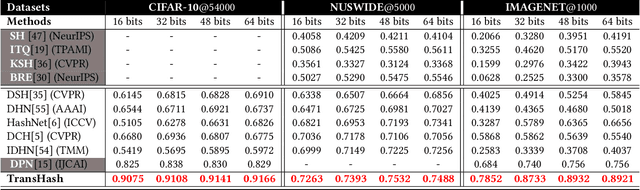
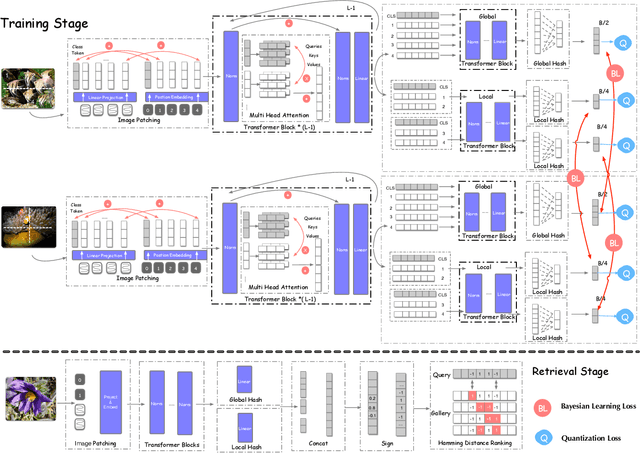

Deep hamming hashing has gained growing popularity in approximate nearest neighbour search for large-scale image retrieval. Until now, the deep hashing for the image retrieval community has been dominated by convolutional neural network architectures, e.g. \texttt{Resnet}\cite{he2016deep}. In this paper, inspired by the recent advancements of vision transformers, we present \textbf{Transhash}, a pure transformer-based framework for deep hashing learning. Concretely, our framework is composed of two major modules: (1) Based on \textit{Vision Transformer} (ViT), we design a siamese vision transformer backbone for image feature extraction. To learn fine-grained features, we innovate a dual-stream feature learning on top of the transformer to learn discriminative global and local features. (2) Besides, we adopt a Bayesian learning scheme with a dynamically constructed similarity matrix to learn compact binary hash codes. The entire framework is jointly trained in an end-to-end manner.~To the best of our knowledge, this is the first work to tackle deep hashing learning problems without convolutional neural networks (\textit{CNNs}). We perform comprehensive experiments on three widely-studied datasets: \textbf{CIFAR-10}, \textbf{NUSWIDE} and \textbf{IMAGENET}. The experiments have evidenced our superiority against the existing state-of-the-art deep hashing methods. Specifically, we achieve 8.2\%, 2.6\%, 12.7\% performance gains in terms of average \textit{mAP} for different hash bit lengths on three public datasets, respectively.
SME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network
Mar 02, 2021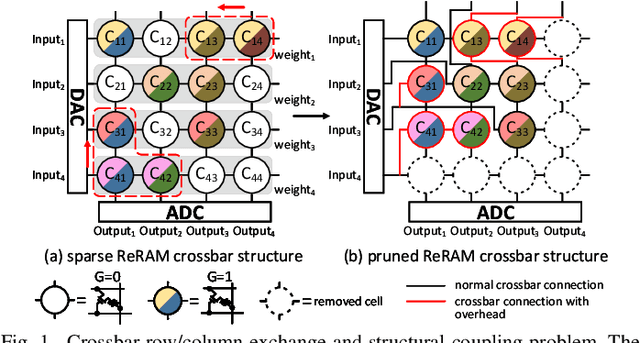
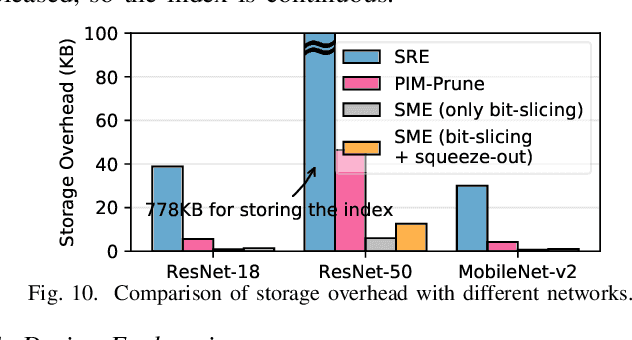
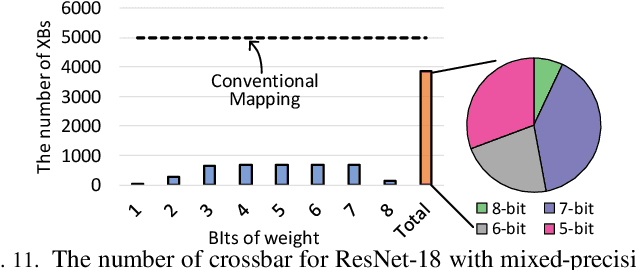
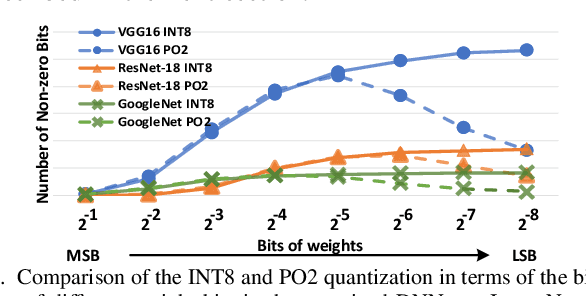
Resistive Random-Access-Memory (ReRAM) crossbar is a promising technique for deep neural network (DNN) accelerators, thanks to its in-memory and in-situ analog computing abilities for Vector-Matrix Multiplication-and-Accumulations (VMMs). However, it is challenging for crossbar architecture to exploit the sparsity in the DNN. It inevitably causes complex and costly control to exploit fine-grained sparsity due to the limitation of tightly-coupled crossbar structure. As the countermeasure, we developed a novel ReRAM-based DNN accelerator, named Sparse-Multiplication-Engine (SME), based on a hardware and software co-design framework. First, we orchestrate the bit-sparse pattern to increase the density of bit-sparsity based on existing quantization methods. Second, we propose a novel weigh mapping mechanism to slice the bits of a weight across the crossbars and splice the activation results in peripheral circuits. This mechanism can decouple the tightly-coupled crossbar structure and cumulate the sparsity in the crossbar. Finally, a superior squeeze-out scheme empties the crossbars mapped with highly-sparse non-zeros from the previous two steps. We design the SME architecture and discuss its use for other quantization methods and different ReRAM cell technologies. Compared with prior state-of-the-art designs, the SME shrinks the use of crossbars up to 8.7x and 2.1x using Resent-50 and MobileNet-v2, respectively, with less than 0.3% accuracy drop on ImageNet.