 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Autoregressive Models for Lossless Image Compression via Hierarchical Parallelism and Progressive Adaptation
Nov 14, 2025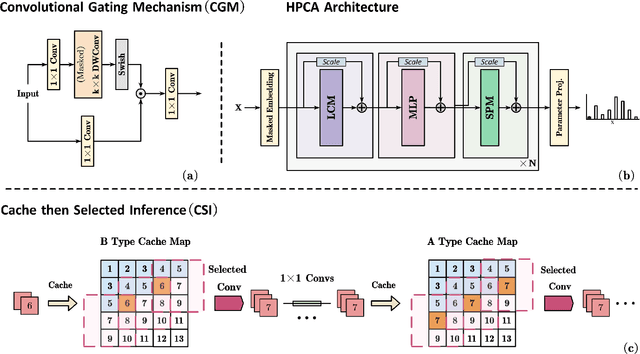
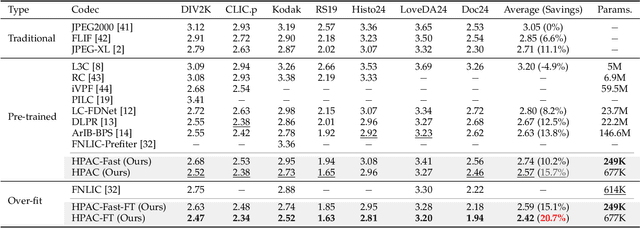
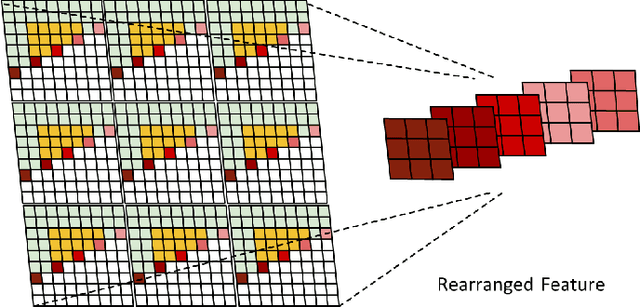
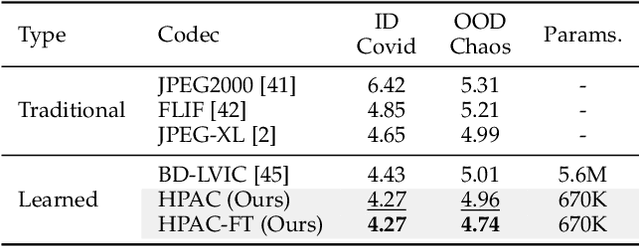
Autoregressive (AR) models, the theoretical performance benchmark for learned lossless image compression, are often dismissed as impractical due to prohibitive computational cost. This work re-thinks this paradigm, introducing a framework built on hierarchical parallelism and progressive adaptation that re-establishes pure autoregression as a top-performing and practical solution. Our approach is embodied in the Hierarchical Parallel Autoregressive ConvNet (HPAC), an ultra-lightweight pre-trained model using a hierarchical factorized structure and content-aware convolutional gating to efficiently capture spatial dependencies. We introduce two key optimizations for practicality: Cache-then-Select Inference (CSI), which accelerates coding by eliminating redundant computations, and Adaptive Focus Coding (AFC), which efficiently extends the framework to high bit-depth images. Building on this efficient foundation, our progressive adaptation strategy is realized by Spatially-Aware Rate-Guided Progressive Fine-tuning (SARP-FT). This instance-level strategy fine-tunes the model for each test image by optimizing low-rank adapters on progressively larger, spatially-continuous regions selected via estimated information density. Experiments on diverse datasets (natural, satellite, medical) validate that our method achieves new state-of-the-art compression. Notably, our approach sets a new benchmark in learned lossless compression, showing a carefully designed AR framework can offer significant gains over existing methods with a small parameter count and competitive coding speeds.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
FUSE: Label-Free Image-Event Joint Monocular Depth Estimation via Frequency-Decoupled Alignment and Degradation-Robust Fusion
Mar 26, 2025Image-event joint depth estimation methods leverage complementary modalities for robust perception, yet face challenges in generalizability stemming from two factors: 1) limited annotated image-event-depth datasets causing insufficient cross-modal supervision, and 2) inherent frequency mismatches between static images and dynamic event streams with distinct spatiotemporal patterns, leading to ineffective feature fusion. To address this dual challenge, we propose Frequency-decoupled Unified Self-supervised Encoder (FUSE) with two synergistic components: The Parameter-efficient Self-supervised Transfer (PST) establishes cross-modal knowledge transfer through latent space alignment with image foundation models, effectively mitigating data scarcity by enabling joint encoding without depth ground truth. Complementing this, we propose the Frequency-Decoupled Fusion module (FreDFuse) to explicitly decouple high-frequency edge features from low-frequency structural components, resolving modality-specific frequency mismatches through physics-aware fusion. This combined approach enables FUSE to construct a universal image-event encoder that only requires lightweight decoder adaptation for target datasets. Extensive experiments demonstrate state-of-the-art performance with 14% and 24.9% improvements in Abs.Rel on MVSEC and DENSE datasets. The framework exhibits remarkable zero-shot adaptability to challenging scenarios including extreme lighting and motion blur, significantly advancing real-world deployment capabilities. The source code for our method is publicly available at: https://github.com/sunpihai-up/FUSE
Adaptive Stereo Depth Estimation with Multi-Spectral Images Across All Lighting Conditions
Nov 06, 2024



Depth estimation under adverse conditions remains a significant challenge. Recently, multi-spectral depth estimation, which integrates both visible light and thermal images, has shown promise in addressing this issue. However, existing algorithms struggle with precise pixel-level feature matching, limiting their ability to fully exploit geometric constraints across different spectra. To address this, we propose a novel framework incorporating stereo depth estimation to enforce accurate geometric constraints. In particular, we treat the visible light and thermal images as a stereo pair and utilize a Cross-modal Feature Matching (CFM) Module to construct a cost volume for pixel-level matching. To mitigate the effects of poor lighting on stereo matching, we introduce Degradation Masking, which leverages robust monocular thermal depth estimation in degraded regions. Our method achieves state-of-the-art (SOTA) performance on the Multi-Spectral Stereo (MS2) dataset, with qualitative evaluations demonstrating high-quality depth maps under varying lighting conditions.
MCGS: Multiview Consistency Enhancement for Sparse-View 3D Gaussian Radiance Fields
Oct 15, 2024



Radiance fields represented by 3D Gaussians excel at synthesizing novel views, offering both high training efficiency and fast rendering. However, with sparse input views, the lack of multi-view consistency constraints results in poorly initialized point clouds and unreliable heuristics for optimization and densification, leading to suboptimal performance. Existing methods often incorporate depth priors from dense estimation networks but overlook the inherent multi-view consistency in input images. Additionally, they rely on multi-view stereo (MVS)-based initialization, which limits the efficiency of scene representation. To overcome these challenges, we propose a view synthesis framework based on 3D Gaussian Splatting, named MCGS, enabling photorealistic scene reconstruction from sparse input views. The key innovations of MCGS in enhancing multi-view consistency are as follows: i) We introduce an initialization method by leveraging a sparse matcher combined with a random filling strategy, yielding a compact yet sufficient set of initial points. This approach enhances the initial geometry prior, promoting efficient scene representation. ii) We develop a multi-view consistency-guided progressive pruning strategy to refine the Gaussian field by strengthening consistency and eliminating low-contribution Gaussians. These modular, plug-and-play strategies enhance robustness to sparse input views, accelerate rendering, and reduce memory consumption, making MCGS a practical and efficient framework for 3D Gaussian Splatting.
CUSIDE-T: Chunking, Simulating Future and Decoding for Transducer based Streaming ASR
Jul 14, 2024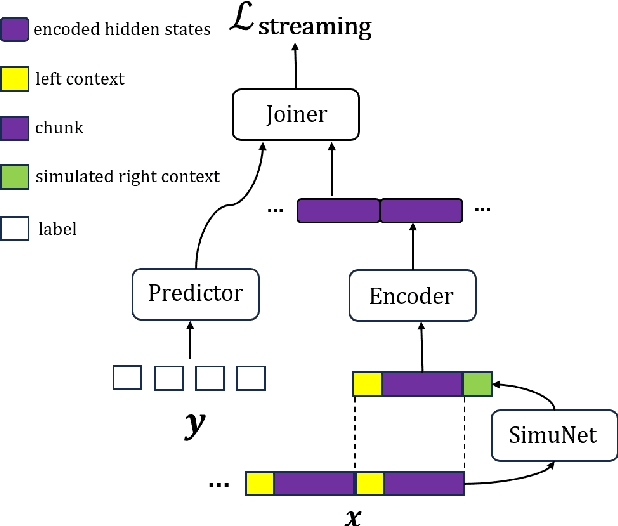
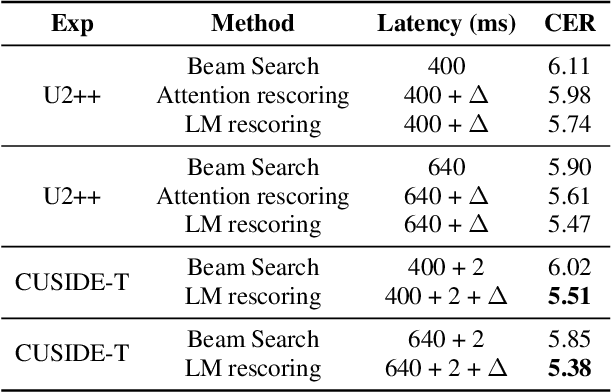
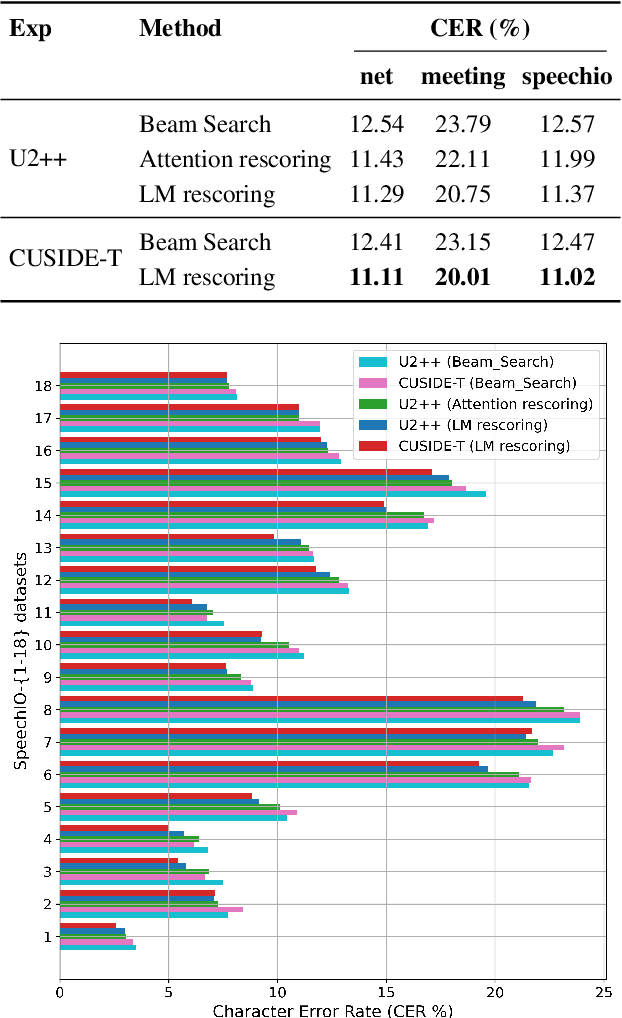
Streaming automatic speech recognition (ASR) is very important for many real-world ASR applications. However, a notable challenge for streaming ASR systems lies in balancing operational performance against latency constraint. Recently, a method of chunking, simulating future context and decoding, called CUSIDE, has been proposed for connectionist temporal classification (CTC) based streaming ASR, which obtains a good balance between reduced latency and high recognition accuracy. In this paper, we present CUSIDE-T, which successfully adapts the CUSIDE method over the recurrent neural network transducer (RNN-T) ASR architecture, instead of being based on the CTC architecture. We also incorporate language model rescoring in CUSIDE-T to further enhance accuracy, while only bringing a small additional latency. Extensive experiments are conducted over the AISHELL-1, WenetSpeech and SpeechIO datasets, comparing CUSIDE-T and U2++ (both based on RNN-T). U2++ is an existing counterpart of chunk based streaming ASR method. It is shown that CUSIDE-T achieves superior accuracy performance for streaming ASR, with equal settings of latency.
Whistle: Data-Efficient Multilingual and Crosslingual Speech Recognition via Weakly Phonetic Supervision
Jun 04, 2024



There exist three approaches for multilingual and crosslingual automatic speech recognition (MCL-ASR) - supervised pre-training with phonetic or graphemic transcription, and self-supervised pre-training. We find that pre-training with phonetic supervision has been underappreciated so far for MCL-ASR, while conceptually it is more advantageous for information sharing between different languages. This paper explores the approach of pre-training with weakly phonetic supervision towards data-efficient MCL-ASR, which is called Whistle. We relax the requirement of gold-standard human-validated phonetic transcripts, and obtain International Phonetic Alphabet (IPA) based transcription by leveraging the LanguageNet grapheme-to-phoneme (G2P) models. We construct a common experimental setup based on the CommonVoice dataset, called CV-Lang10, with 10 seen languages and 2 unseen languages. A set of experiments are conducted on CV-Lang10 to compare, as fair as possible, the three approaches under the common setup for MCL-ASR. Experiments demonstrate the advantages of phoneme-based models (Whistle) for MCL-ASR, in terms of speech recognition for seen languages, crosslingual performance for unseen languages with different amounts of few-shot data, overcoming catastrophic forgetting, and training efficiency.It is found that when training data is more limited, phoneme supervision can achieve better results compared to subword supervision and self-supervision, thereby providing higher data-efficiency. To support reproducibility and promote future research along this direction, we will release the code, models and data for the whole pipeline of Whistle at https://github.com/thu-spmi/CAT upon publication.
DINO-SD: Champion Solution for ICRA 2024 RoboDepth Challenge
May 27, 2024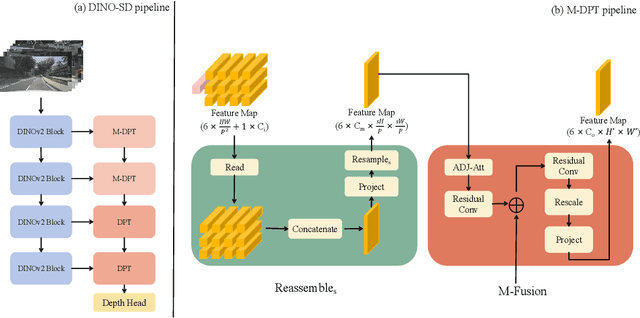

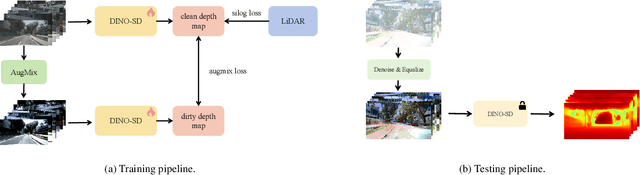
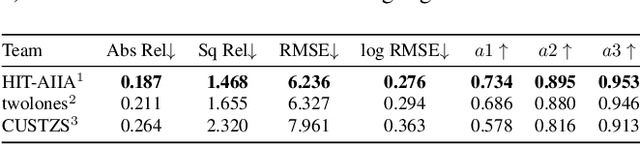
Surround-view depth estimation is a crucial task aims to acquire the depth maps of the surrounding views. It has many applications in real world scenarios such as autonomous driving, AR/VR and 3D reconstruction, etc. However, given that most of the data in the autonomous driving dataset is collected in daytime scenarios, this leads to poor depth model performance in the face of out-of-distribution(OoD) data. While some works try to improve the robustness of depth model under OoD data, these methods either require additional training data or lake generalizability. In this report, we introduce the DINO-SD, a novel surround-view depth estimation model. Our DINO-SD does not need additional data and has strong robustness. Our DINO-SD get the best performance in the track4 of ICRA 2024 RoboDepth Challenge.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024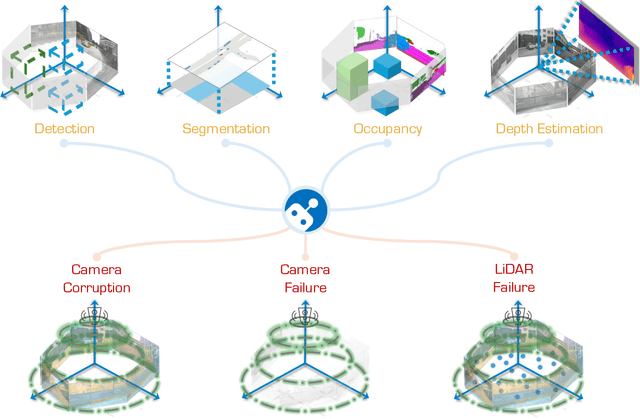


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Mesh Denoising Transformer
May 10, 2024Mesh denoising, aimed at removing noise from input meshes while preserving their feature structures, is a practical yet challenging task. Despite the remarkable progress in learning-based mesh denoising methodologies in recent years, their network designs often encounter two principal drawbacks: a dependence on single-modal geometric representations, which fall short in capturing the multifaceted attributes of meshes, and a lack of effective global feature aggregation, hindering their ability to fully understand the mesh's comprehensive structure. To tackle these issues, we propose SurfaceFormer, a pioneering Transformer-based mesh denoising framework. Our first contribution is the development of a new representation known as Local Surface Descriptor, which is crafted by establishing polar systems on each mesh face, followed by sampling points from adjacent surfaces using geodesics. The normals of these points are organized into 2D patches, mimicking images to capture local geometric intricacies, whereas the poles and vertex coordinates are consolidated into a point cloud to embody spatial information. This advancement surmounts the hurdles posed by the irregular and non-Euclidean characteristics of mesh data, facilitating a smooth integration with Transformer architecture. Next, we propose a dual-stream structure consisting of a Geometric Encoder branch and a Spatial Encoder branch, which jointly encode local geometry details and spatial information to fully explore multimodal information for mesh denoising. A subsequent Denoising Transformer module receives the multimodal information and achieves efficient global feature aggregation through self-attention operators. Our experimental evaluations demonstrate that this novel approach outperforms existing state-of-the-art methods in both objective and subjective assessments, marking a significant leap forward in mesh denoising.