 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUSIDE-T: Chunking, Simulating Future and Decoding for Transducer based Streaming ASR
Paper and Code
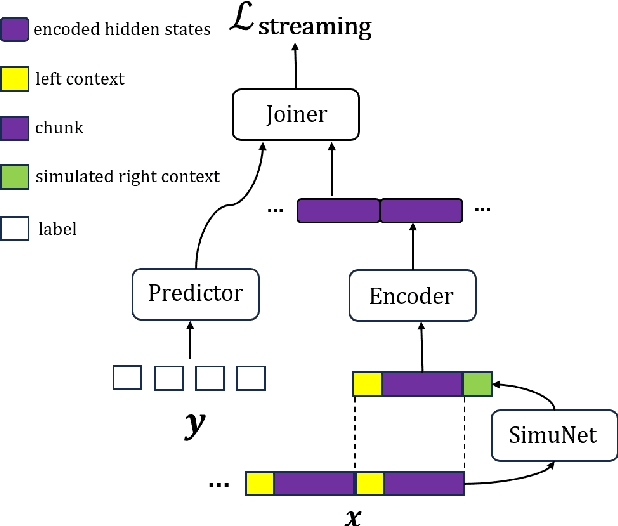
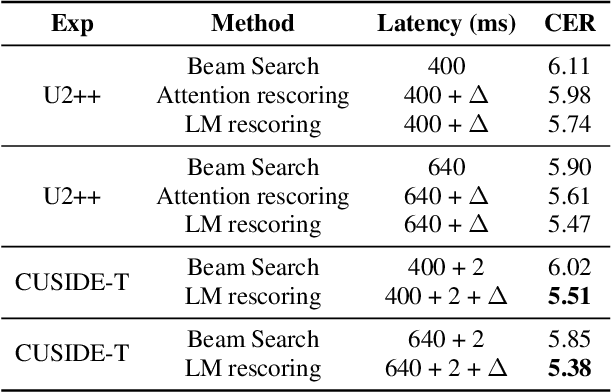
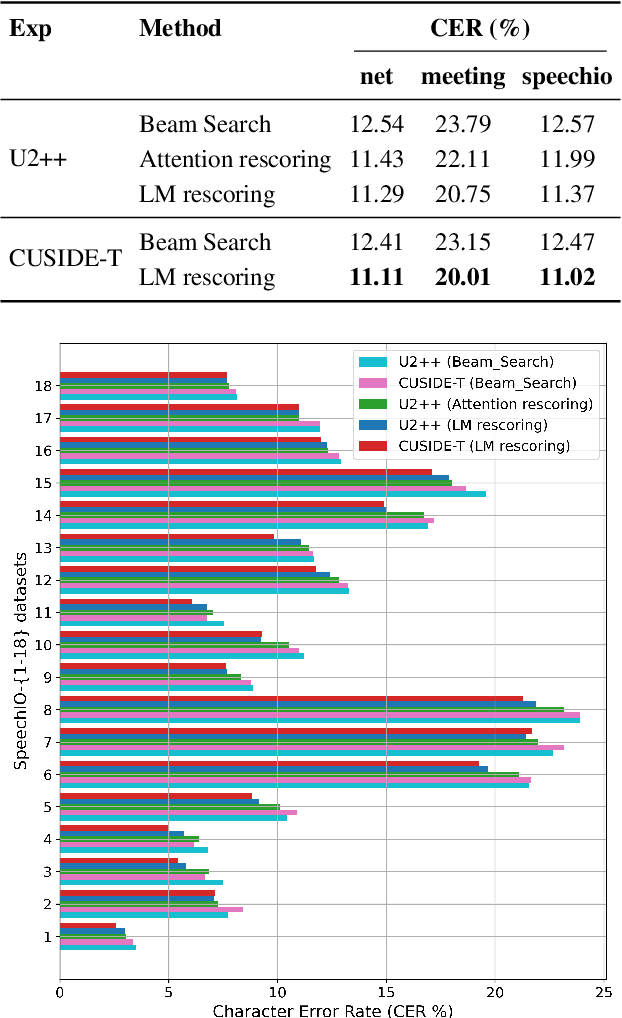
Streaming automatic speech recognition (ASR) is very important for many real-world ASR applications. However, a notable challenge for streaming ASR systems lies in balancing operational performance against latency constraint. Recently, a method of chunking, simulating future context and decoding, called CUSIDE, has been proposed for connectionist temporal classification (CTC) based streaming ASR, which obtains a good balance between reduced latency and high recognition accuracy. In this paper, we present CUSIDE-T, which successfully adapts the CUSIDE method over the recurrent neural network transducer (RNN-T) ASR architecture, instead of being based on the CTC architecture. We also incorporate language model rescoring in CUSIDE-T to further enhance accuracy, while only bringing a small additional latency. Extensive experiments are conducted over the AISHELL-1, WenetSpeech and SpeechIO datasets, comparing CUSIDE-T and U2++ (both based on RNN-T). U2++ is an existing counterpart of chunk based streaming ASR method. It is shown that CUSIDE-T achieves superior accuracy performance for streaming ASR, with equal settings of latency.