 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq-Masks: Bridging the gap between appearance and gait modeling for video-based person re-identification
Dec 10, 2021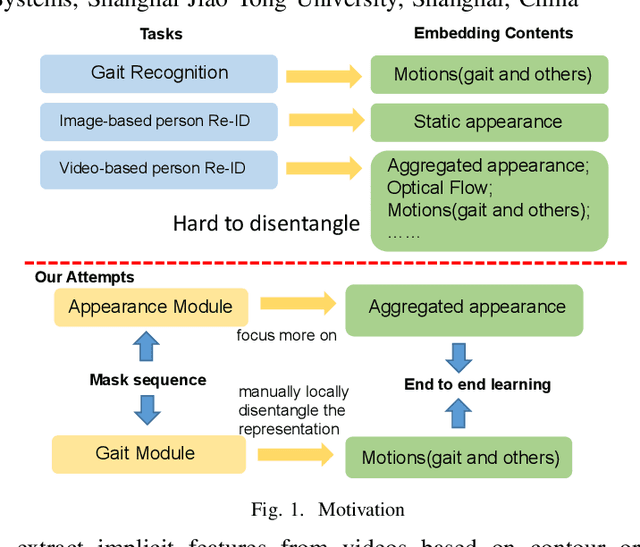
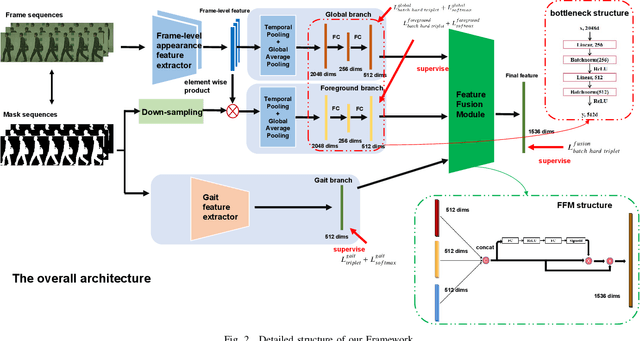
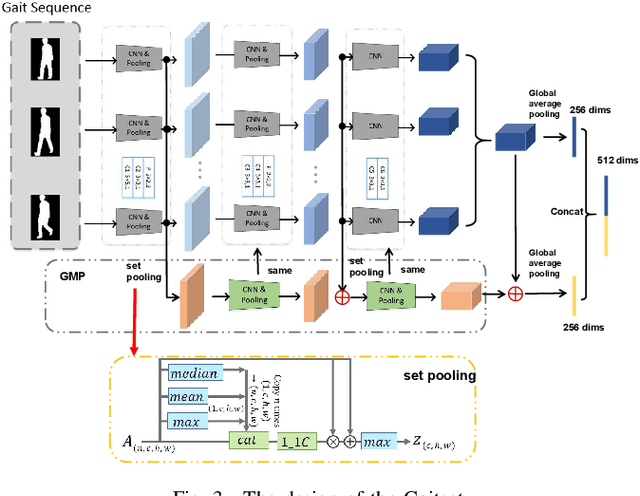

ideo-based person re-identification (Re-ID) aims to match person images in video sequences captured by disjoint surveillance cameras. Traditional video-based person Re-ID methods focus on exploring appearance information, thus, vulnerable against illumination changes, scene noises, camera parameters, and especially clothes/carrying variations. Gait recognition provides an implicit biometric solution to alleviate the above headache. Nonetheless, it experiences severe performance degeneration as camera view varies. In an attempt to address these problems, in this paper, we propose a framework that utilizes the sequence masks (SeqMasks) in the video to integrate appearance information and gait modeling in a close fashion. Specifically, to sufficiently validate the effectiveness of our method, we build a novel dataset named MaskMARS based on MARS. Comprehensive experiments on our proposed large wild video Re-ID dataset MaskMARS evidenced our extraordinary performance and generalization capability. Validations on the gait recognition metric CASIA-B dataset further demonstrated the capability of our hybrid model.
DVHN: A Deep Hashing Framework for Large-scale Vehicle Re-identification
Dec 09, 2021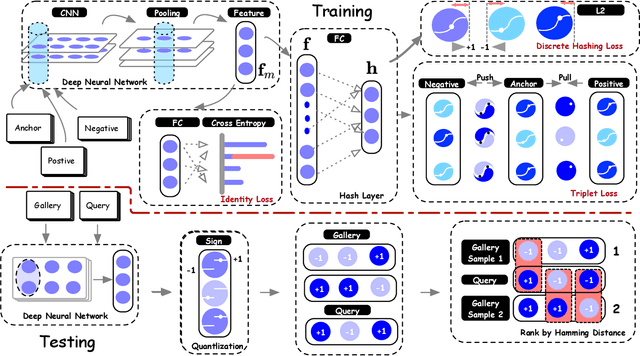
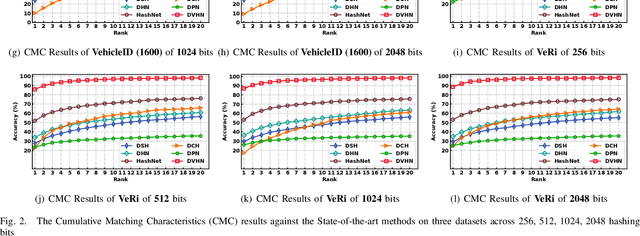
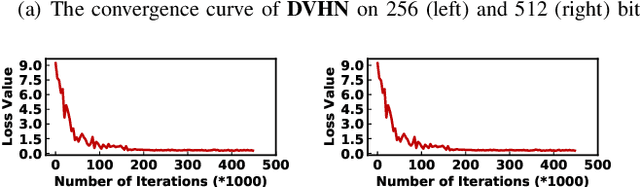
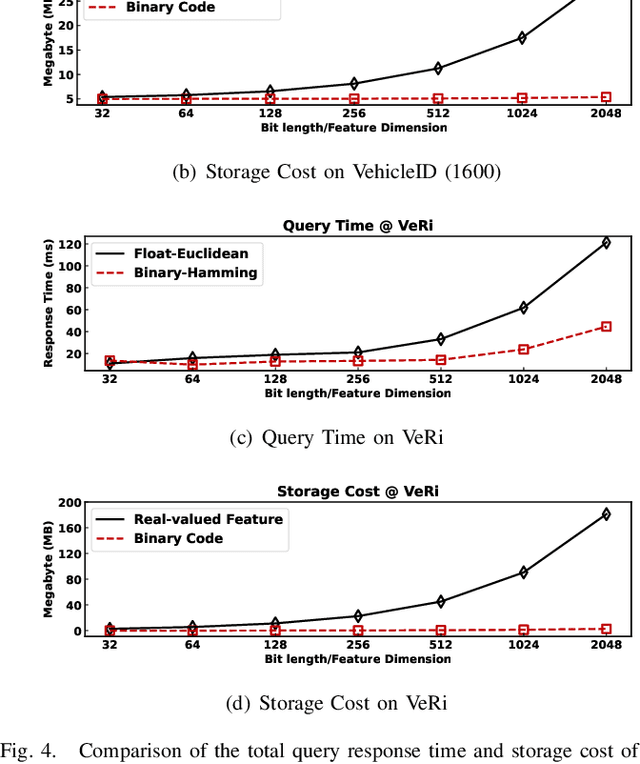
In this paper, we make the very first attempt to investigate the integration of deep hash learning with vehicle re-identification. We propose a deep hash-based vehicle re-identification framework, dubbed DVHN, which substantially reduces memory usage and promotes retrieval efficiency while reserving nearest neighbor search accuracy. Concretely,~DVHN directly learns discrete compact binary hash codes for each image by jointly optimizing the feature learning network and the hash code generating module. Specifically, we directly constrain the output from the convolutional neural network to be discrete binary codes and ensure the learned binary codes are optimal for classification. To optimize the deep discrete hashing framework, we further propose an alternating minimization method for learning binary similarity-preserved hashing codes. Extensive experiments on two widely-studied vehicle re-identification datasets- \textbf{VehicleID} and \textbf{VeRi}-~have demonstrated the superiority of our method against the state-of-the-art deep hash methods. \textbf{DVHN} of $2048$ bits can achieve 13.94\% and 10.21\% accuracy improvement in terms of \textbf{mAP} and \textbf{Rank@1} for \textbf{VehicleID (800)} dataset. For \textbf{VeRi}, we achieve 35.45\% and 32.72\% performance gains for \textbf{Rank@1} and \textbf{mAP}, respectively.
TransHash: Transformer-based Hamming Hashing for Efficient Image Retrieval
May 05, 2021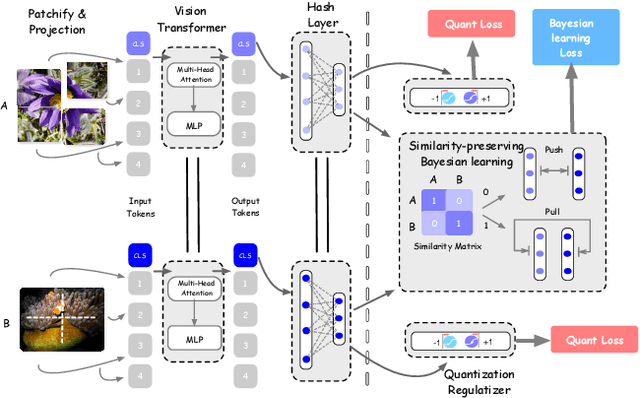
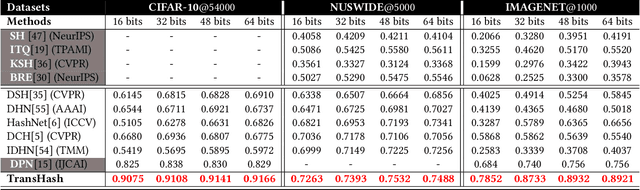
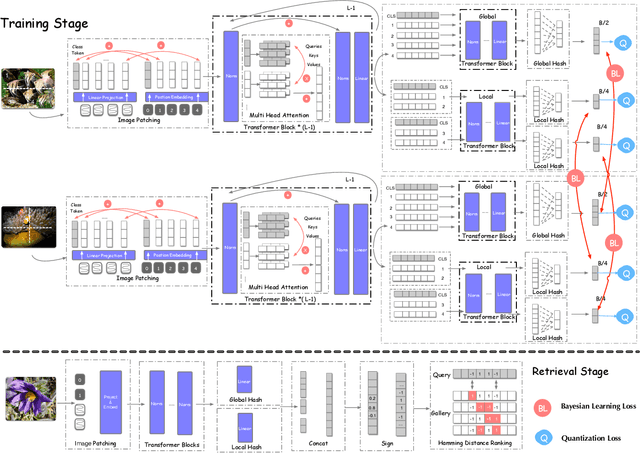

Deep hamming hashing has gained growing popularity in approximate nearest neighbour search for large-scale image retrieval. Until now, the deep hashing for the image retrieval community has been dominated by convolutional neural network architectures, e.g. \texttt{Resnet}\cite{he2016deep}. In this paper, inspired by the recent advancements of vision transformers, we present \textbf{Transhash}, a pure transformer-based framework for deep hashing learning. Concretely, our framework is composed of two major modules: (1) Based on \textit{Vision Transformer} (ViT), we design a siamese vision transformer backbone for image feature extraction. To learn fine-grained features, we innovate a dual-stream feature learning on top of the transformer to learn discriminative global and local features. (2) Besides, we adopt a Bayesian learning scheme with a dynamically constructed similarity matrix to learn compact binary hash codes. The entire framework is jointly trained in an end-to-end manner.~To the best of our knowledge, this is the first work to tackle deep hashing learning problems without convolutional neural networks (\textit{CNNs}). We perform comprehensive experiments on three widely-studied datasets: \textbf{CIFAR-10}, \textbf{NUSWIDE} and \textbf{IMAGENET}. The experiments have evidenced our superiority against the existing state-of-the-art deep hashing methods. Specifically, we achieve 8.2\%, 2.6\%, 12.7\% performance gains in terms of average \textit{mAP} for different hash bit lengths on three public datasets, respectively.