 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Multi-Granularity Representation via Group Contrastive Learning for Unsupervised Vehicle Re-identification
Oct 29, 2024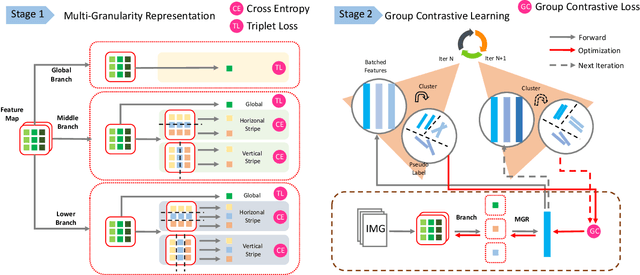



Vehicle re-identification (Vehicle ReID) aims at retrieving vehicle images across disjoint surveillance camera views. The majority of vehicle ReID research is heavily reliant upon supervisory labels from specific human-collected datasets for training. When applied to the large-scale real-world scenario, these models will experience dreadful performance declines due to the notable domain discrepancy between the source dataset and the target. To address this challenge, in this paper, we propose an unsupervised vehicle ReID framework (MGR-GCL). It integrates a multi-granularity CNN representation for learning discriminative transferable features and a contrastive learning module responsible for efficient domain adaptation in the unlabeled target domain. Specifically, after training the proposed Multi-Granularity Representation (MGR) on the labeled source dataset, we propose a group contrastive learning module (GCL) to generate pseudo labels for the target dataset, facilitating the domain adaptation process. We conducted extensive experiments and the results demonstrated our superiority against existing state-of-the-art methods.
Multi-Style Facial Sketch Synthesis through Masked Generative Modeling
Aug 22, 2024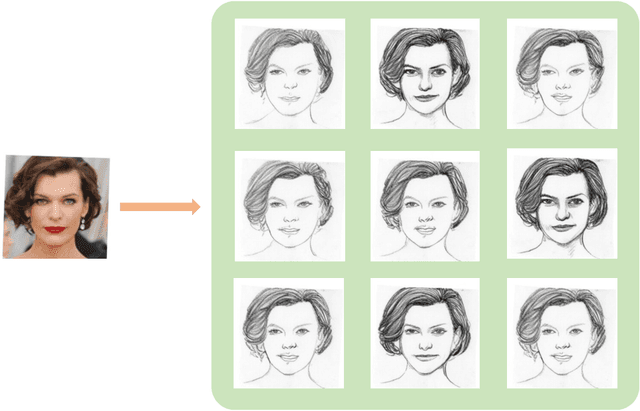
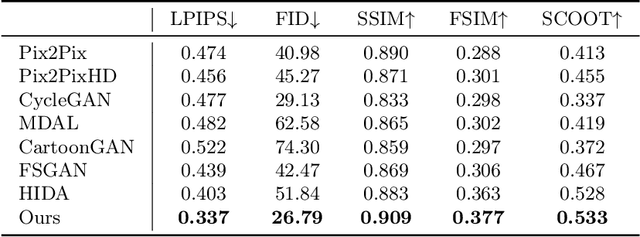
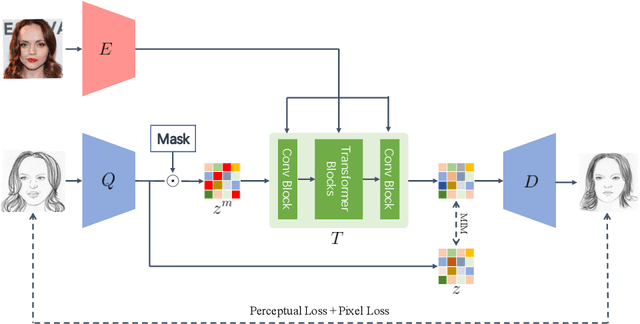

The facial sketch synthesis (FSS) model, capable of generating sketch portraits from given facial photographs, holds profound implications across multiple domains, encompassing cross-modal face recognition, entertainment, art, media, among others. However, the production of high-quality sketches remains a formidable task, primarily due to the challenges and flaws associated with three key factors: (1) the scarcity of artist-drawn data, (2) the constraints imposed by limited style types, and (3) the deficiencies of processing input information in existing models. To address these difficulties, we propose a lightweight end-to-end synthesis model that efficiently converts images to corresponding multi-stylized sketches, obviating the necessity for any supplementary inputs (\eg, 3D geometry). In this study, we overcome the issue of data insufficiency by incorporating semi-supervised learning into the training process. Additionally, we employ a feature extraction module and style embeddings to proficiently steer the generative transformer during the iterative prediction of masked image tokens, thus achieving a continuous stylized output that retains facial features accurately in sketches. The extensive experiments demonstrate that our method consistently outperforms previous algorithms across multiple benchmarks, exhibiting a discernible disparity.
FreeFlow: A Comprehensive Understanding on Diffusion Probabilistic Models via Optimal Transport
Dec 09, 2023


The blooming diffusion probabilistic models (DPMs) have garnered significant interest due to their impressive performance and the elegant inspiration they draw from physics. While earlier DPMs relied upon the Markovian assumption, recent methods based on differential equations have been rapidly applied to enhance the efficiency and capabilities of these models. However, a theoretical interpretation encapsulating these diverse algorithms is insufficient yet pressingly required to guide further development of DPMs. In response to this need, we present FreeFlow, a framework that provides a thorough explanation of the diffusion formula as time-dependent optimal transport, where the evolutionary pattern of probability density is given by the gradient flows of a functional defined in Wasserstein space. Crucially, our framework necessitates a unified description that not only clarifies the subtle mechanism of DPMs but also indicates the roots of some defects through creative involvement of Lagrangian and Eulerian views to understand the evolution of probability flow. We particularly demonstrate that the core equation of FreeFlow condenses all stochastic and deterministic DPMs into a single case, showcasing the expansibility of our method. Furthermore, the Riemannian geometry employed in our work has the potential to bridge broader subjects in mathematics, which enable the involvement of more profound tools for the establishment of more outstanding and generalized models in the future.
Machine Vision Therapy: Multimodal Large Language Models Can Enhance Visual Robustness via Denoising In-Context Learning
Dec 05, 2023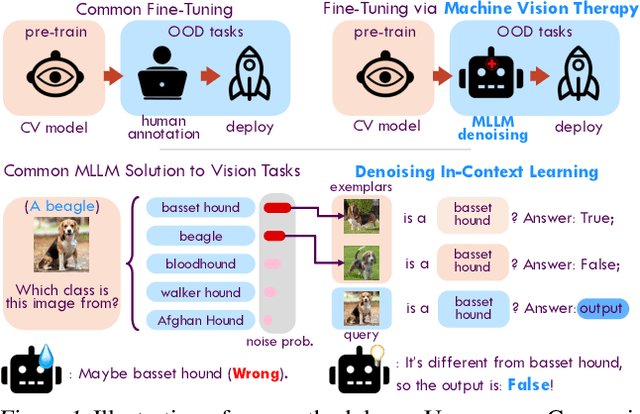
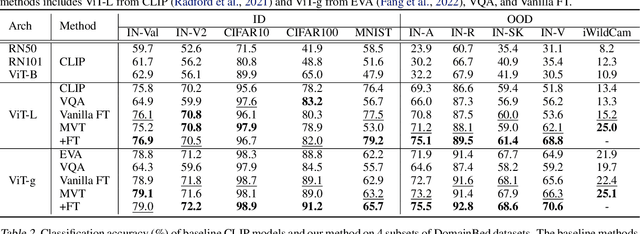
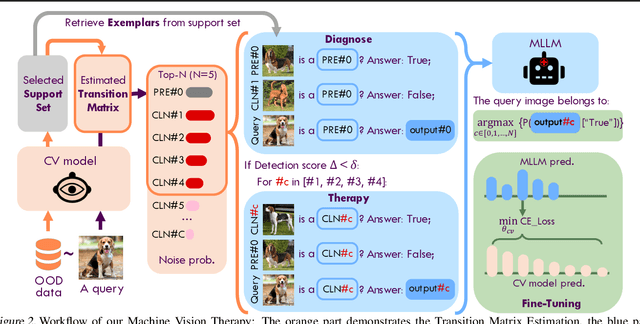
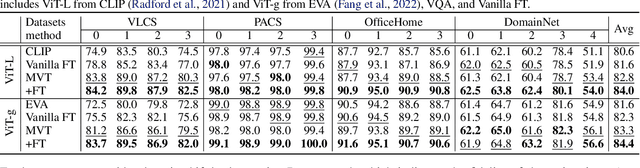
Although vision models such as Contrastive Language-Image Pre-Training (CLIP) show impressive generalization performance, their zero-shot robustness is still limited under Out-of-Distribution (OOD) scenarios without fine-tuning. Instead of undesirably providing human supervision as commonly done, it is possible to take advantage of Multi-modal Large Language Models (MLLMs) that hold powerful visual understanding abilities. However, MLLMs are shown to struggle with vision problems due to the incompatibility of tasks, thus hindering their utilization. In this paper, we propose to effectively leverage MLLMs to conduct Machine Vision Therapy which aims to rectify the noisy predictions from vision models. By fine-tuning with the denoised labels, the learning model performance can be boosted in an unsupervised manner. To solve the incompatibility issue, we propose a novel Denoising In-Context Learning (DICL) strategy to align vision tasks with MLLMs. Concretely, by estimating a transition matrix that captures the probability of one class being confused with another, an instruction containing a correct exemplar and an erroneous one from the most probable noisy class can be constructed. Such an instruction can help any MLLMs with ICL ability to detect and rectify incorrect predictions of vision models. Through extensive experiments on ImageNet, WILDS, DomainBed, and other OOD datasets, we carefully validate the quantitative and qualitative effectiveness of our method. Our code is available at https://github.com/tmllab/Machine_Vision_Therapy.
DiFace: Cross-Modal Face Recognition through Controlled Diffusion
Dec 03, 2023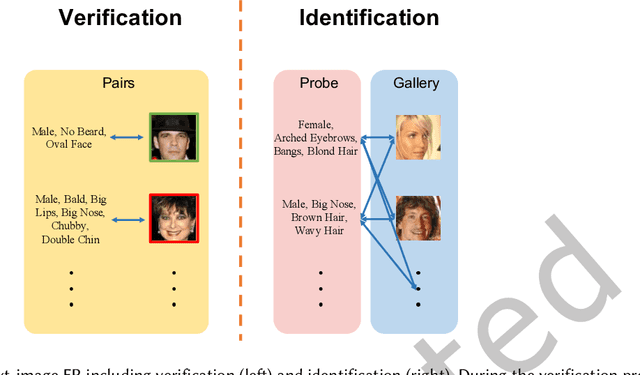
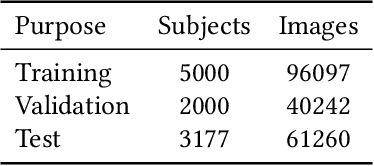
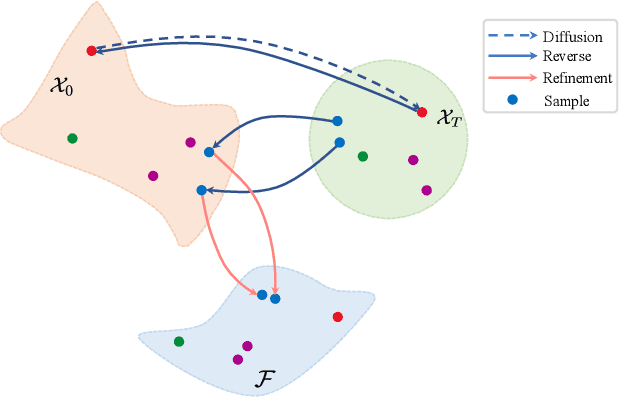
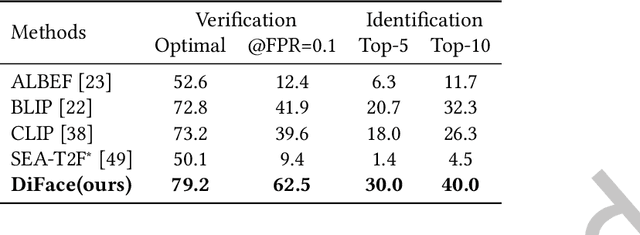
Diffusion probabilistic models (DPMs) have exhibited exceptional proficiency in generating visual media of outstanding quality and realism. Nonetheless, their potential in non-generative domains, such as face recognition, has yet to be thoroughly investigated. Meanwhile, despite the extensive development of multi-modal face recognition methods, their emphasis has predominantly centered on visual modalities. In this context, face recognition through textual description presents a unique and promising solution that not only transcends the limitations from application scenarios but also expands the potential for research in the field of cross-modal face recognition. It is regrettable that this avenue remains unexplored and underutilized, a consequence from the challenges mainly associated with three aspects: 1) the intrinsic imprecision of verbal descriptions; 2) the significant gaps between texts and images; and 3) the immense hurdle posed by insufficient databases.To tackle this problem, we present DiFace, a solution that effectively achieves face recognition via text through a controllable diffusion process, by establishing its theoretical connection with probability transport. Our approach not only unleashes the potential of DPMs across a broader spectrum of tasks but also achieves, to the best of our knowledge, a significant accuracy in text-to-image face recognition for the first time, as demonstrated by our experiments on verification and identification.
Hierarchical Semantic Perceptual Listener Head Video Generation: A High-performance Pipeline
Jul 19, 2023



In dyadic speaker-listener interactions, the listener's head reactions along with the speaker's head movements, constitute an important non-verbal semantic expression together. The listener Head generation task aims to synthesize responsive listener's head videos based on audios of the speaker and reference images of the listener. Compared to the Talking-head generation, it is more challenging to capture the correlation clues from the speaker's audio and visual information. Following the ViCo baseline scheme, we propose a high-performance solution by enhancing the hierarchical semantic extraction capability of the audio encoder module and improving the decoder part, renderer and post-processing modules. Our solution gets the first place on the official leaderboard for the track of listening head generation. This paper is a technical report of ViCo@2023 Conversational Head Generation Challenge in ACM Multimedia 2023 conference.
Understanding the Robustness of 3D Object Detection with Bird's-Eye-View Representations in Autonomous Driving
Mar 30, 20233D object detection is an essential perception task in autonomous driving to understand the environments. The Bird's-Eye-View (BEV) representations have significantly improved the performance of 3D detectors with camera inputs on popular benchmarks. However, there still lacks a systematic understanding of the robustness of these vision-dependent BEV models, which is closely related to the safety of autonomous driving systems. In this paper, we evaluate the natural and adversarial robustness of various representative models under extensive settings, to fully understand their behaviors influenced by explicit BEV features compared with those without BEV. In addition to the classic settings, we propose a 3D consistent patch attack by applying adversarial patches in the 3D space to guarantee the spatiotemporal consistency, which is more realistic for the scenario of autonomous driving. With substantial experiments, we draw several findings: 1) BEV models tend to be more stable than previous methods under different natural conditions and common corruptions due to the expressive spatial representations; 2) BEV models are more vulnerable to adversarial noises, mainly caused by the redundant BEV features; 3) Camera-LiDAR fusion models have superior performance under different settings with multi-modal inputs, but BEV fusion model is still vulnerable to adversarial noises of both point cloud and image. These findings alert the safety issue in the applications of BEV detectors and could facilitate the development of more robust models.
To Make Yourself Invisible with Adversarial Semantic Contours
Mar 01, 2023



Modern object detectors are vulnerable to adversarial examples, which may bring risks to real-world applications. The sparse attack is an important task which, compared with the popular adversarial perturbation on the whole image, needs to select the potential pixels that is generally regularized by an $\ell_0$-norm constraint, and simultaneously optimize the corresponding texture. The non-differentiability of $\ell_0$ norm brings challenges and many works on attacking object detection adopted manually-designed patterns to address them, which are meaningless and independent of objects, and therefore lead to relatively poor attack performance. In this paper, we propose Adversarial Semantic Contour (ASC), an MAP estimate of a Bayesian formulation of sparse attack with a deceived prior of object contour. The object contour prior effectively reduces the search space of pixel selection and improves the attack by introducing more semantic bias. Extensive experiments demonstrate that ASC can corrupt the prediction of 9 modern detectors with different architectures (\e.g., one-stage, two-stage and Transformer) by modifying fewer than 5\% of the pixels of the object area in COCO in white-box scenario and around 10\% of those in black-box scenario. We further extend the attack to datasets for autonomous driving systems to verify the effectiveness. We conclude with cautions about contour being the common weakness of object detectors with various architecture and the care needed in applying them in safety-sensitive scenarios.
* 11 pages, 7 figures, published in Computer Vision and Image Understanding in 2023
Improving Model Generalization by On-manifold Adversarial Augmentation in the Frequency Domain
Feb 28, 2023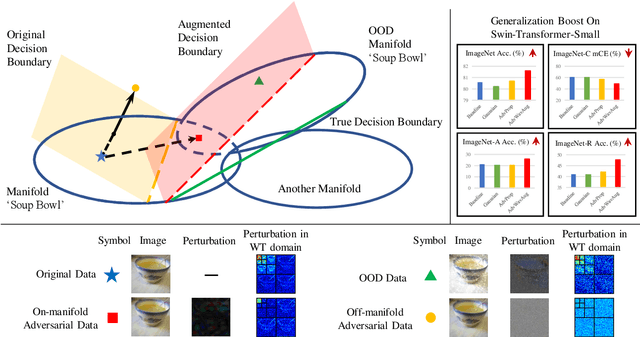

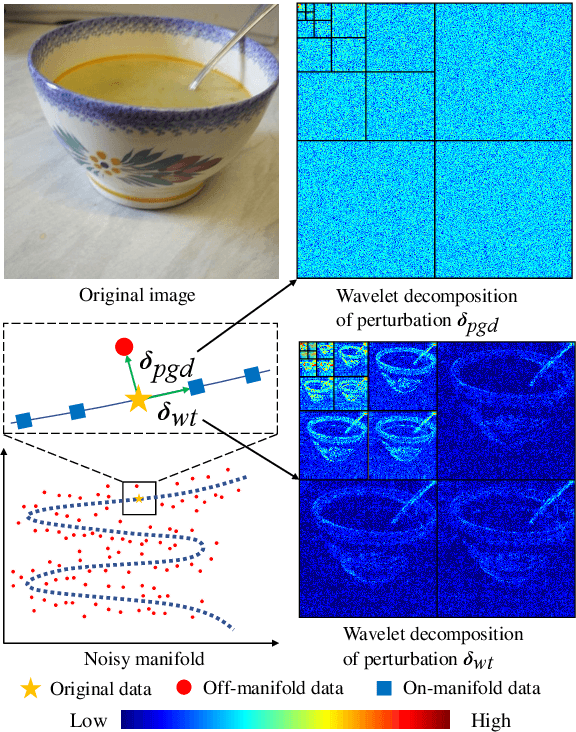
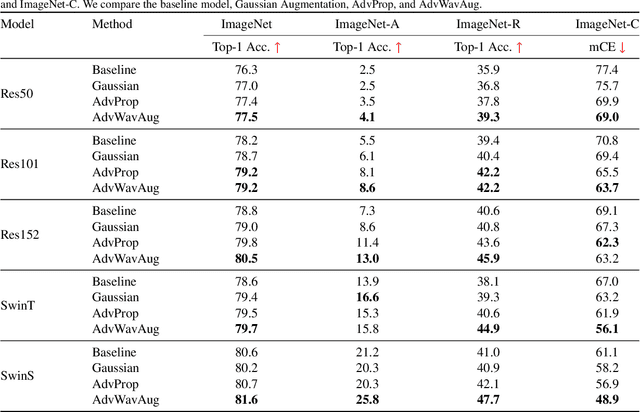
Deep neural networks (DNNs) may suffer from significantly degenerated performance when the training and test data are of different underlying distributions. Despite the importance of model generalization to out-of-distribution (OOD) data, the accuracy of state-of-the-art (SOTA) models on OOD data can plummet. Recent work has demonstrated that regular or off-manifold adversarial examples, as a special case of data augmentation, can be used to improve OOD generalization. Inspired by this, we theoretically prove that on-manifold adversarial examples can better benefit OOD generalization. Nevertheless, it is nontrivial to generate on-manifold adversarial examples because the real manifold is generally complex. To address this issue, we proposed a novel method of Augmenting data with Adversarial examples via a Wavelet module (AdvWavAug), an on-manifold adversarial data augmentation technique that is simple to implement. In particular, we project a benign image into a wavelet domain. With the assistance of the sparsity characteristic of wavelet transformation, we can modify an image on the estimated data manifold. We conduct adversarial augmentation based on AdvProp training framework. Extensive experiments on different models and different datasets, including ImageNet and its distorted versions, demonstrate that our method can improve model generalization, especially on OOD data. By integrating AdvWavAug into the training process, we have achieved SOTA results on some recent transformer-based models.
A Comprehensive Study on Robustness of Image Classification Models: Benchmarking and Rethinking
Feb 28, 2023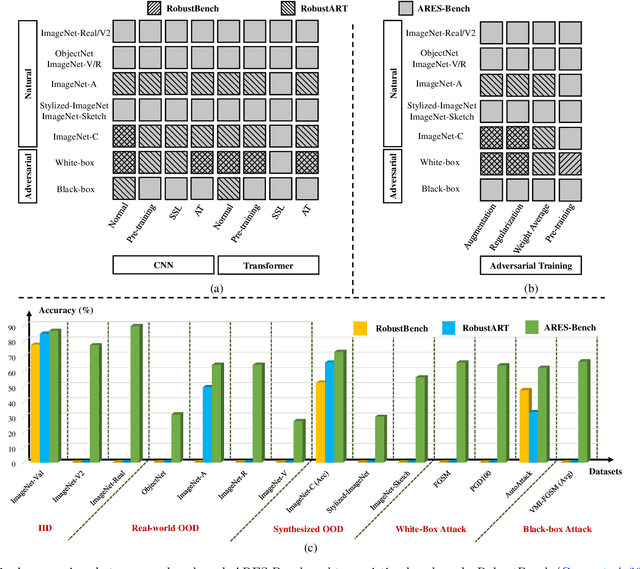

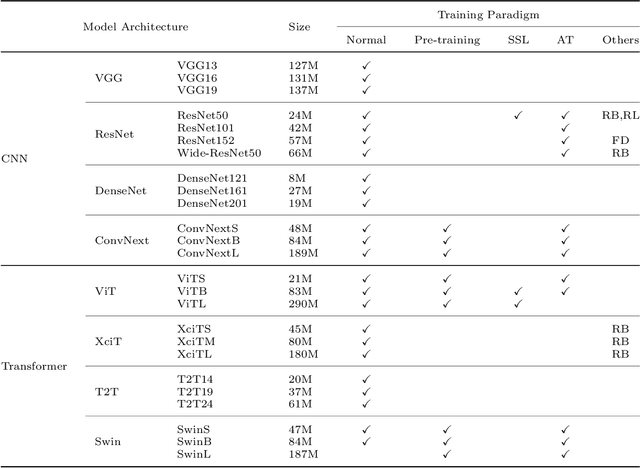
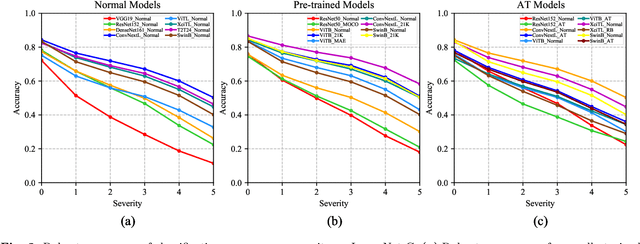
The robustness of deep neural networks is usually lacking under adversarial examples, common corruptions, and distribution shifts, which becomes an important research problem in the development of deep learning. Although new deep learning methods and robustness improvement techniques have been constantly proposed, the robustness evaluations of existing methods are often inadequate due to their rapid development, diverse noise patterns, and simple evaluation metrics. Without thorough robustness evaluations, it is hard to understand the advances in the field and identify the effective methods. In this paper, we establish a comprehensive robustness benchmark called \textbf{ARES-Bench} on the image classification task. In our benchmark, we evaluate the robustness of 55 typical deep learning models on ImageNet with diverse architectures (e.g., CNNs, Transformers) and learning algorithms (e.g., normal supervised training, pre-training, adversarial training) under numerous adversarial attacks and out-of-distribution (OOD) datasets. Using robustness curves as the major evaluation criteria, we conduct large-scale experiments and draw several important findings, including: 1) there is an inherent trade-off between adversarial and natural robustness for the same model architecture; 2) adversarial training effectively improves adversarial robustness, especially when performed on Transformer architectures; 3) pre-training significantly improves natural robustness based on more training data or self-supervised learning. Based on ARES-Bench, we further analyze the training tricks in large-scale adversarial training on ImageNet. By designing the training settings accordingly, we achieve the new state-of-the-art adversarial robustness. We have made the benchmarking results and code platform publicly available.