 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Semantic Perceptual Listener Head Video Generation: A High-performance Pipeline
Jul 19, 2023



In dyadic speaker-listener interactions, the listener's head reactions along with the speaker's head movements, constitute an important non-verbal semantic expression together. The listener Head generation task aims to synthesize responsive listener's head videos based on audios of the speaker and reference images of the listener. Compared to the Talking-head generation, it is more challenging to capture the correlation clues from the speaker's audio and visual information. Following the ViCo baseline scheme, we propose a high-performance solution by enhancing the hierarchical semantic extraction capability of the audio encoder module and improving the decoder part, renderer and post-processing modules. Our solution gets the first place on the official leaderboard for the track of listening head generation. This paper is a technical report of ViCo@2023 Conversational Head Generation Challenge in ACM Multimedia 2023 conference.
Improve Ranking Correlation of Super-net through Training Scheme from One-shot NAS to Few-shot NAS
Jun 14, 2022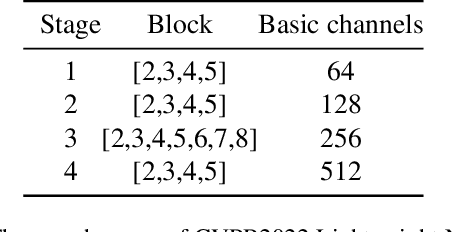
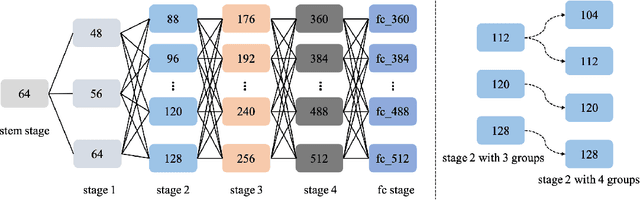

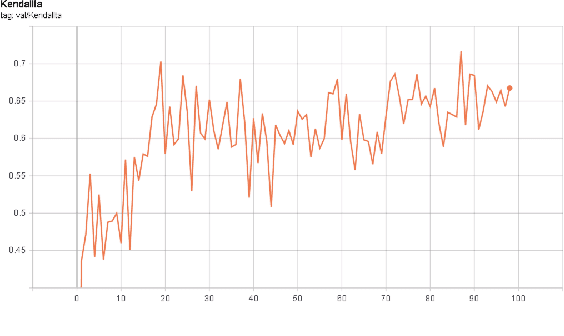
The algorithms of one-shot neural architecture search(NAS) have been widely used to reduce computation consumption. However, because of the interference among the subnets in which weights are shared, the subnets inherited from these super-net trained by those algorithms have poor consistency in precision ranking. To address this problem, we propose a step-by-step training super-net scheme from one-shot NAS to few-shot NAS. In the training scheme, we firstly train super-net in a one-shot way, and then we disentangle the weights of super-net by splitting them into multi-subnets and training them gradually. Finally, our method ranks 4th place in the CVPR2022 3rd Lightweight NAS Challenge Track1. Our code is available at https://github.com/liujiawei2333/CVPR2022-NAS-competition-Track-1-4th-solution.