 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiFace: Cross-Modal Face Recognition through Controlled Diffusion
Paper and Code
Dec 03, 2023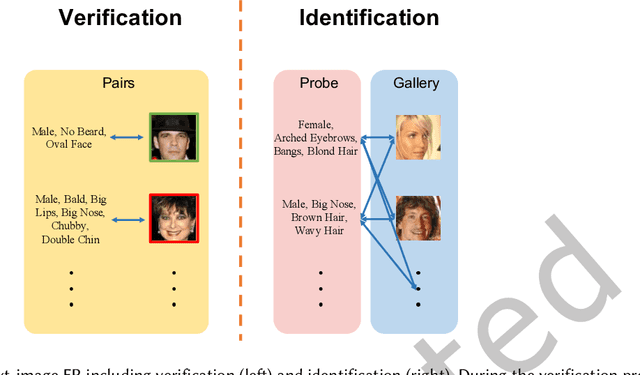
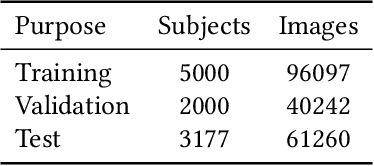
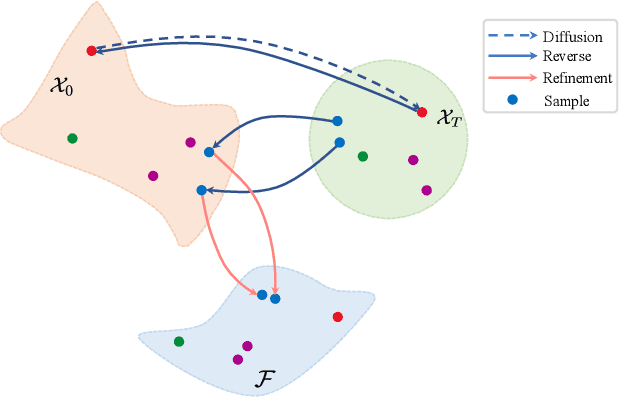
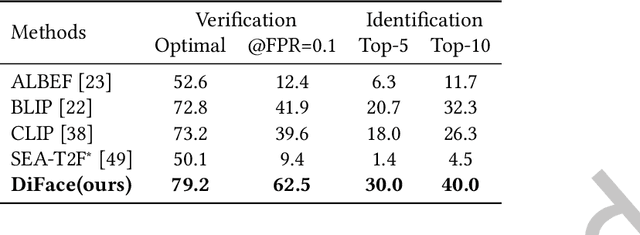
Diffusion probabilistic models (DPMs) have exhibited exceptional proficiency in generating visual media of outstanding quality and realism. Nonetheless, their potential in non-generative domains, such as face recognition, has yet to be thoroughly investigated. Meanwhile, despite the extensive development of multi-modal face recognition methods, their emphasis has predominantly centered on visual modalities. In this context, face recognition through textual description presents a unique and promising solution that not only transcends the limitations from application scenarios but also expands the potential for research in the field of cross-modal face recognition. It is regrettable that this avenue remains unexplored and underutilized, a consequence from the challenges mainly associated with three aspects: 1) the intrinsic imprecision of verbal descriptions; 2) the significant gaps between texts and images; and 3) the immense hurdle posed by insufficient databases.To tackle this problem, we present DiFace, a solution that effectively achieves face recognition via text through a controllable diffusion process, by establishing its theoretical connection with probability transport. Our approach not only unleashes the potential of DPMs across a broader spectrum of tasks but also achieves, to the best of our knowledge, a significant accuracy in text-to-image face recognition for the first time, as demonstrated by our experiments on verification and identification.