 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Style Facial Sketch Synthesis through Masked Generative Modeling
Paper and Code
Aug 22, 2024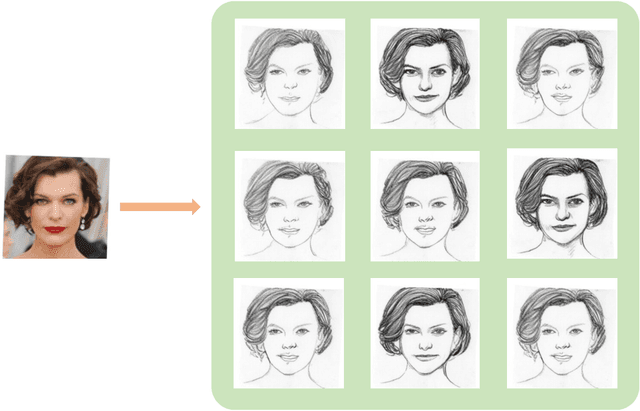
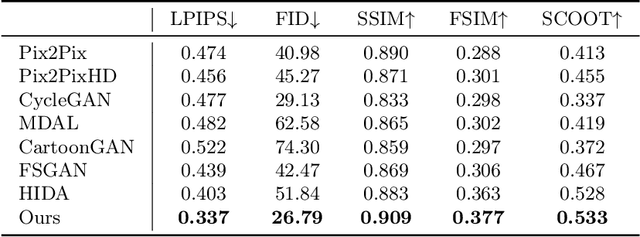
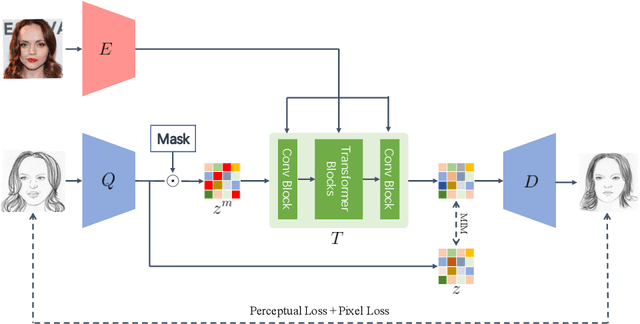

The facial sketch synthesis (FSS) model, capable of generating sketch portraits from given facial photographs, holds profound implications across multiple domains, encompassing cross-modal face recognition, entertainment, art, media, among others. However, the production of high-quality sketches remains a formidable task, primarily due to the challenges and flaws associated with three key factors: (1) the scarcity of artist-drawn data, (2) the constraints imposed by limited style types, and (3) the deficiencies of processing input information in existing models. To address these difficulties, we propose a lightweight end-to-end synthesis model that efficiently converts images to corresponding multi-stylized sketches, obviating the necessity for any supplementary inputs (\eg, 3D geometry). In this study, we overcome the issue of data insufficiency by incorporating semi-supervised learning into the training process. Additionally, we employ a feature extraction module and style embeddings to proficiently steer the generative transformer during the iterative prediction of masked image tokens, thus achieving a continuous stylized output that retains facial features accurately in sketches. The extensive experiments demonstrate that our method consistently outperforms previous algorithms across multiple benchmarks, exhibiting a discernible disparity.