 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransHash: Transformer-based Hamming Hashing for Efficient Image Retrieval
Paper and Code
May 05, 2021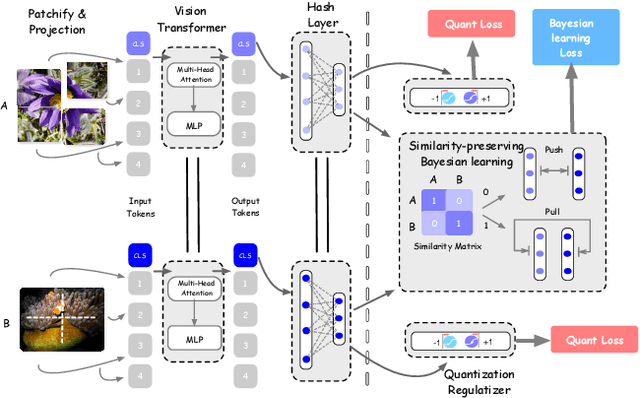
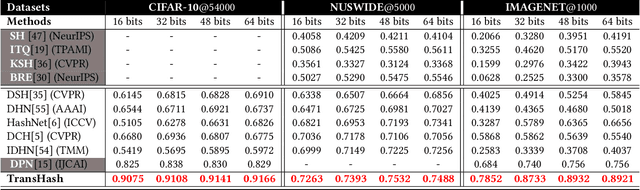
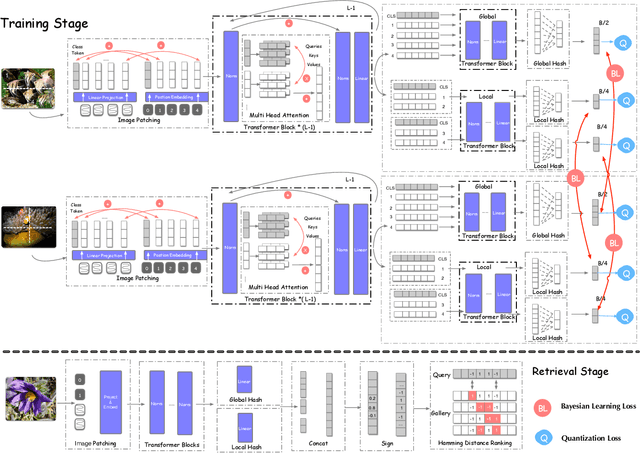

Deep hamming hashing has gained growing popularity in approximate nearest neighbour search for large-scale image retrieval. Until now, the deep hashing for the image retrieval community has been dominated by convolutional neural network architectures, e.g. \texttt{Resnet}\cite{he2016deep}. In this paper, inspired by the recent advancements of vision transformers, we present \textbf{Transhash}, a pure transformer-based framework for deep hashing learning. Concretely, our framework is composed of two major modules: (1) Based on \textit{Vision Transformer} (ViT), we design a siamese vision transformer backbone for image feature extraction. To learn fine-grained features, we innovate a dual-stream feature learning on top of the transformer to learn discriminative global and local features. (2) Besides, we adopt a Bayesian learning scheme with a dynamically constructed similarity matrix to learn compact binary hash codes. The entire framework is jointly trained in an end-to-end manner.~To the best of our knowledge, this is the first work to tackle deep hashing learning problems without convolutional neural networks (\textit{CNNs}). We perform comprehensive experiments on three widely-studied datasets: \textbf{CIFAR-10}, \textbf{NUSWIDE} and \textbf{IMAGENET}. The experiments have evidenced our superiority against the existing state-of-the-art deep hashing methods. Specifically, we achieve 8.2\%, 2.6\%, 12.7\% performance gains in terms of average \textit{mAP} for different hash bit lengths on three public datasets, respectively.