 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
Paper and Code

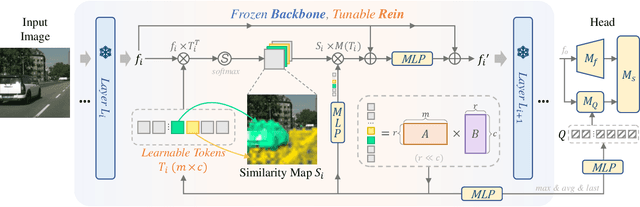
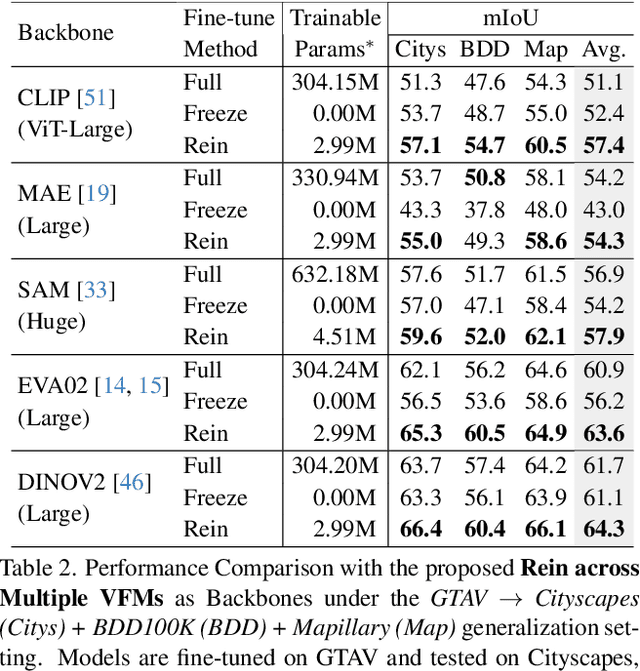
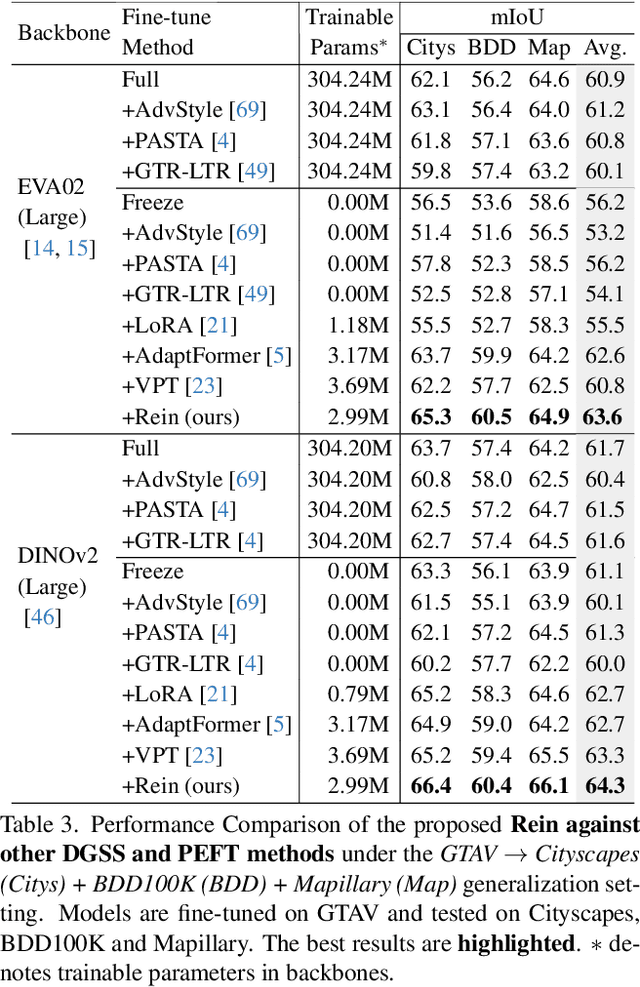
In this paper, we first assess and harness various Vision Foundation Models (VFMs) in the context of Domain Generalized Semantic Segmentation (DGSS). Driven by the motivation that Leveraging Stronger pre-trained models and Fewer trainable parameters for Superior generalizability, we introduce a robust fine-tuning approach, namely Rein, to parameter-efficiently harness VFMs for DGSS. Built upon a set of trainable tokens, each linked to distinct instances, Rein precisely refines and forwards the feature maps from each layer to the next layer within the backbone. This process produces diverse refinements for different categories within a single image. With fewer trainable parameters, Rein efficiently fine-tunes VFMs for DGSS tasks, surprisingly surpassing full parameter fine-tuning. Extensive experiments across various settings demonstrate that Rein significantly outperforms state-of-the-art methods. Remarkably, with just an extra 1% of trainable parameters within the frozen backbone, Rein achieves a mIoU of 68.1% on the Cityscapes, without accessing any real urban-scene datasets.Code is available at https://github.com/w1oves/Rein.git.