 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Scale-wise Text-to-image generation via Auto-Regressive representations
Paper and Code
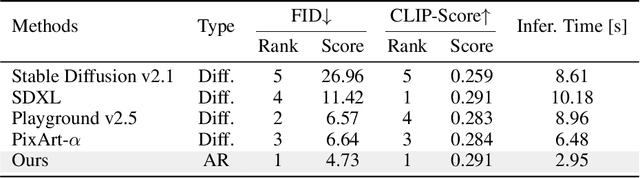
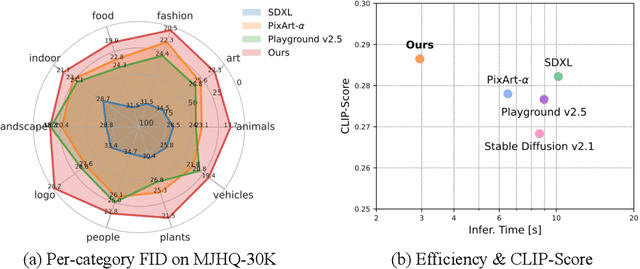
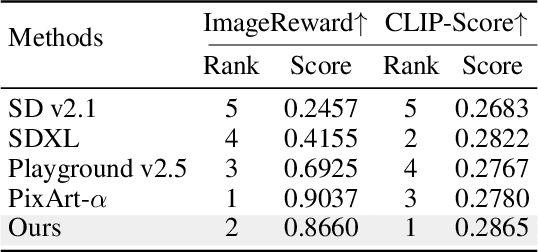
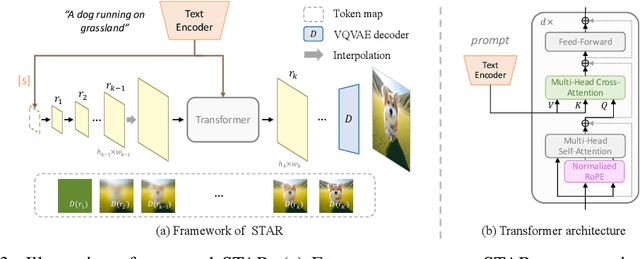
We present STAR, a text-to-image model that employs scale-wise auto-regressive paradigm. Unlike VAR, which is limited to class-conditioned synthesis within a fixed set of predetermined categories, our STAR enables text-driven open-set generation through three key designs: To boost diversity and generalizability with unseen combinations of objects and concepts, we introduce a pre-trained text encoder to extract representations for textual constraints, which we then use as guidance. To improve the interactions between generated images and fine-grained textual guidance, making results more controllable, additional cross-attention layers are incorporated at each scale. Given the natural structure correlation across different scales, we leverage 2D Rotary Positional Encoding (RoPE) and tweak it into a normalized version. This ensures consistent interpretation of relative positions across token maps at different scales and stabilizes the training process. Extensive experiments demonstrate that STAR surpasses existing benchmarks in terms of fidelity,image text consistency, and aesthetic quality. Our findings emphasize the potential of auto-regressive methods in the field of high-quality image synthesis, offering promising new directions for the T2I field currently dominated by diffusion methods.