 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRT: Masked Region Transformer for Layered Image Generation and Editing at Scale
May 26, 2026Layered image generation and editing is a fundamental capability that enables layer-wise reuse, editing, and composition of generated visual content, analogous to word-level editing in natural language. Despite its importance, this remains an underexplored area at scale. To address this gap, we present MRT, a 20B-parameter masked region diffusion model tailored for multi-layer transparent image generation and editing, trained on over 10M multilingual design samples spanning diverse aspect ratios and textual prompts. To fully leverage this scale, we make two key technical contributions. First, we unify three complementary tasks including text-to-layers, image-to-layers, and layers-to-layers within a shared masked region diffusion framework, where selective token masking enables flexible layer-wise generation and editing. Second, to enable overflow layer generation, we introduce an overflow-aware canvas layer that handles boundary inconsistencies and supports semi-transparent background synthesis, enabling complete editable layers extending beyond visible canvas boundaries. Additionally, we apply diffusion distillation to achieve 8-step, real-time multi-layer generation with minimal quality degradation. Extensive experiments demonstrate that our framework substantially outperforms prior state-of-the-art approaches, including various commercial systems, across all three tasks, establishing a new benchmark for multi-layer transparent image generation. Notably, our model significantly outperforms the concurrent Qwen-Image-Layered model in image-to-layers quality according to user-study results, while achieving 10-100\times faster inference and reducing activation GPU memory consumption by 50-90\% during image-to-layer inference.
Pareto-Guided Optimal Transport for Multi-Reward Alignment
May 13, 2026Text-to-image generation models have achieved remarkable progress in preference optimization, yet achieving robust alignment across diverse reward models remains a significant challenge. Existing multi-reward fusion approaches rely on weighted summation, which is costly to tune and insufficient for balancing conflicting objectives. More critically, optimization with reward models is highly susceptible to reward hacking, where reward scores increase while the perceived quality of generated images deteriorates. We demonstrate that optimizing against a unified global target under heterogeneous reward upper bounds can induce reward hacking, a risk further exacerbated by the inherent instability of weak reward models. To mitigate this, we propose a Pareto Frontier-Guided Optimal Transport (PG-OT) framework. Our method constructs a prompt-specific Pareto frontier and maps dominated samples toward it via distribution-aware optimal transport. Furthermore, we develop both online and offline optimization strategies tailored to diverse reward signal characteristics. To provide a more rigorous assessment, we introduce the Joint Domination Rate (JDR) and Joint Collapse Rate (JCR) as principled metrics to quantify multi-reward synergy and reward hacking. Experimental results show that our approach outperforms strong baselines with an 11% gain in JDR and achieves a near 80% win rate in human evaluations.
V2Flow: Unifying Visual Tokenization and Large Language Model Vocabularies for Autoregressive Image Generation
Mar 10, 2025We propose V2Flow, a novel tokenizer that produces discrete visual tokens capable of high-fidelity reconstruction, while ensuring structural and latent distribution alignment with the vocabulary space of large language models (LLMs). Leveraging this tight visual-vocabulary coupling, V2Flow enables autoregressive visual generation on top of existing LLMs. Our approach formulates visual tokenization as a flow-matching problem, aiming to learn a mapping from a standard normal prior to the continuous image distribution, conditioned on token sequences embedded within the LLMs vocabulary space. The effectiveness of V2Flow stems from two core designs. First, we propose a Visual Vocabulary resampler, which compresses visual data into compact token sequences, with each represented as a soft categorical distribution over LLM's vocabulary. This allows seamless integration of visual tokens into existing LLMs for autoregressive visual generation. Second, we present a masked autoregressive Rectified-Flow decoder, employing a masked transformer encoder-decoder to refine visual tokens into contextually enriched embeddings. These embeddings then condition a dedicated velocity field for precise reconstruction. Additionally, an autoregressive rectified-flow sampling strategy is incorporated, ensuring flexible sequence lengths while preserving competitive reconstruction quality. Extensive experiments show that V2Flow outperforms mainstream VQ-based tokenizers and facilitates autoregressive visual generation on top of existing. https://github.com/zhangguiwei610/V2Flow
STAR: Scale-wise Text-to-image generation via Auto-Regressive representations
Jun 16, 2024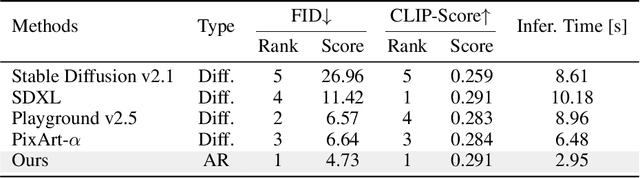
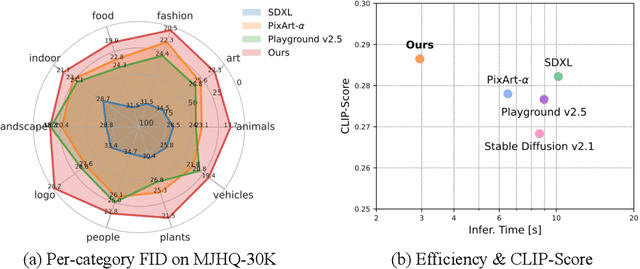
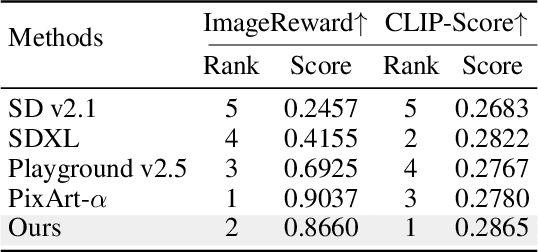
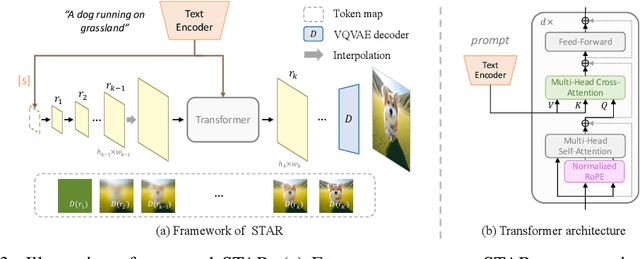
We present STAR, a text-to-image model that employs scale-wise auto-regressive paradigm. Unlike VAR, which is limited to class-conditioned synthesis within a fixed set of predetermined categories, our STAR enables text-driven open-set generation through three key designs: To boost diversity and generalizability with unseen combinations of objects and concepts, we introduce a pre-trained text encoder to extract representations for textual constraints, which we then use as guidance. To improve the interactions between generated images and fine-grained textual guidance, making results more controllable, additional cross-attention layers are incorporated at each scale. Given the natural structure correlation across different scales, we leverage 2D Rotary Positional Encoding (RoPE) and tweak it into a normalized version. This ensures consistent interpretation of relative positions across token maps at different scales and stabilizes the training process. Extensive experiments demonstrate that STAR surpasses existing benchmarks in terms of fidelity,image text consistency, and aesthetic quality. Our findings emphasize the potential of auto-regressive methods in the field of high-quality image synthesis, offering promising new directions for the T2I field currently dominated by diffusion methods.
StyleInject: Parameter Efficient Tuning of Text-to-Image Diffusion Models
Jan 25, 2024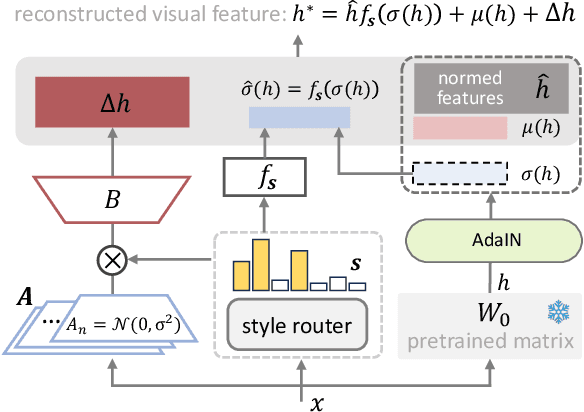



The ability to fine-tune generative models for text-to-image generation tasks is crucial, particularly facing the complexity involved in accurately interpreting and visualizing textual inputs. While LoRA is efficient for language model adaptation, it often falls short in text-to-image tasks due to the intricate demands of image generation, such as accommodating a broad spectrum of styles and nuances. To bridge this gap, we introduce StyleInject, a specialized fine-tuning approach tailored for text-to-image models. StyleInject comprises multiple parallel low-rank parameter matrices, maintaining the diversity of visual features. It dynamically adapts to varying styles by adjusting the variance of visual features based on the characteristics of the input signal. This approach significantly minimizes the impact on the original model's text-image alignment capabilities while adeptly adapting to various styles in transfer learning. StyleInject proves particularly effective in learning from and enhancing a range of advanced, community-fine-tuned generative models. Our comprehensive experiments, including both small-sample and large-scale data fine-tuning as well as base model distillation, show that StyleInject surpasses traditional LoRA in both text-image semantic consistency and human preference evaluation, all while ensuring greater parameter efficiency.
Learning and Evaluating Human Preferences for Conversational Head Generation
Aug 02, 2023



A reliable and comprehensive evaluation metric that aligns with manual preference assessments is crucial for conversational head video synthesis methods development. Existing quantitative evaluations often fail to capture the full complexity of human preference, as they only consider limited evaluation dimensions. Qualitative evaluations and user studies offer a solution but are time-consuming and labor-intensive. This limitation hinders the advancement of conversational head generation algorithms and systems. In this paper, we propose a novel learning-based evaluation metric named Preference Score (PS) for fitting human preference according to the quantitative evaluations across different dimensions. PS can serve as a quantitative evaluation without the need for human annotation. Experimental results validate the superiority of Preference Score in aligning with human perception, and also demonstrate robustness and generalizability to unseen data, making it a valuable tool for advancing conversation head generation. We expect this metric could facilitate new advances in conversational head generation. Project Page: https://https://github.com/dc3ea9f/PreferenceScore.
Interactive Conversational Head Generation
Jul 05, 2023



We introduce a new conversation head generation benchmark for synthesizing behaviors of a single interlocutor in a face-to-face conversation. The capability to automatically synthesize interlocutors which can participate in long and multi-turn conversations is vital and offer benefits for various applications, including digital humans, virtual agents, and social robots. While existing research primarily focuses on talking head generation (one-way interaction), hindering the ability to create a digital human for conversation (two-way) interaction due to the absence of listening and interaction parts. In this work, we construct two datasets to address this issue, ``ViCo'' for independent talking and listening head generation tasks at the sentence level, and ``ViCo-X'', for synthesizing interlocutors in multi-turn conversational scenarios. Based on ViCo and ViCo-X, we define three novel tasks targeting the interaction modeling during the face-to-face conversation: 1) responsive listening head generation making listeners respond actively to the speaker with non-verbal signals, 2) expressive talking head generation guiding speakers to be aware of listeners' behaviors, and 3) conversational head generation to integrate the talking/listening ability in one interlocutor. Along with the datasets, we also propose corresponding baseline solutions to the three aforementioned tasks. Experimental results show that our baseline method could generate responsive and vivid agents that can collaborate with real person to fulfil the whole conversation. Project page: https://vico.solutions/.
Visual-Aware Text-to-Speech
Jun 21, 2023



Dynamically synthesizing talking speech that actively responds to a listening head is critical during the face-to-face interaction. For example, the speaker could take advantage of the listener's facial expression to adjust the tones, stressed syllables, or pauses. In this work, we present a new visual-aware text-to-speech (VA-TTS) task to synthesize speech conditioned on both textual inputs and sequential visual feedback (e.g., nod, smile) of the listener in face-to-face communication. Different from traditional text-to-speech, VA-TTS highlights the impact of visual modality. On this newly-minted task, we devise a baseline model to fuse phoneme linguistic information and listener visual signals for speech synthesis. Extensive experiments on multimodal conversation dataset ViCo-X verify our proposal for generating more natural audio with scenario-appropriate rhythm and prosody.
* accepted as oral and top 3% paper by ICASSP 2023
Responsive Listening Head Generation: A Benchmark Dataset and Baseline
Dec 27, 2021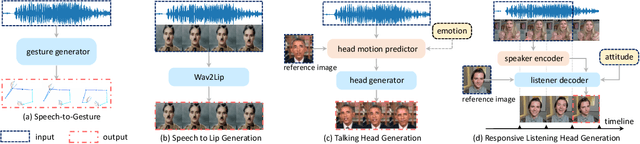
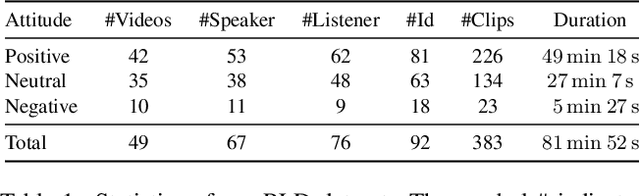

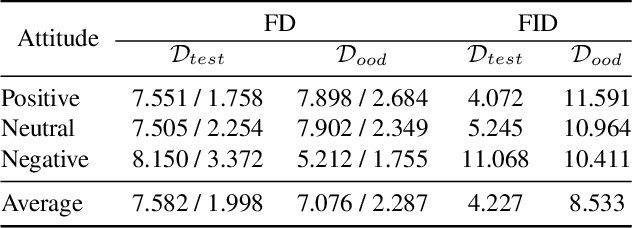
Responsive listening during face-to-face conversations is a critical element of social interaction and is well established in psychological research. Through non-verbal signals response to the speakers' words, intonations, or behaviors in real-time, listeners show how they are engaged in dialogue. In this work, we build the Responsive Listener Dataset (RLD), a conversation video corpus collected from the public resources featuring 67 speakers, 76 listeners with three different attitudes. We define the responsive listening head generation task as the synthesis of a non-verbal head with motions and expressions reacting to the multiple inputs, including the audio and visual signal of the speaker. Unlike speech-driven gesture or talking head generation, we introduce more modals in this task, hoping to benefit several research fields, including human-to-human interaction, video-to-video translation, cross-modal understanding, and generation. Furthermore, we release an attitude conditioned listening head generation baseline. Project page: \url{https://project.mhzhou.com/rld}.
Augmentation Pathways Network for Visual Recognition
Jul 26, 2021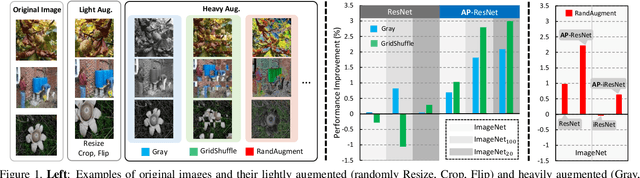

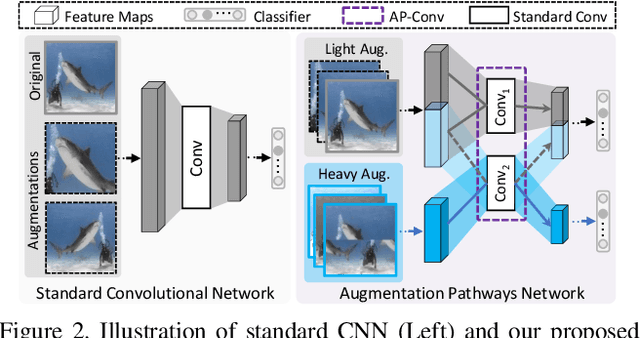
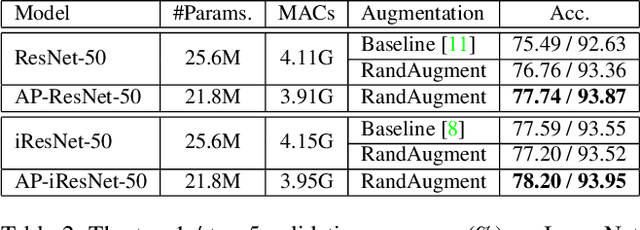
Data augmentation is practically helpful for visual recognition, especially at the time of data scarcity. However, such success is only limited to quite a few light augmentations (e.g., random crop, flip). Heavy augmentations (e.g., gray, grid shuffle) are either unstable or show adverse effects during training, owing to the big gap between the original and augmented images. This paper introduces a novel network design, noted as Augmentation Pathways (AP), to systematically stabilize training on a much wider range of augmentation policies. Notably, AP tames heavy data augmentations and stably boosts performance without a careful selection among augmentation policies. Unlike traditional single pathway, augmented images are processed in different neural paths. The main pathway handles light augmentations, while other pathways focus on heavy augmentations. By interacting with multiple paths in a dependent manner, the backbone network robustly learns from shared visual patterns among augmentations, and suppresses noisy patterns at the same time. Furthermore, we extend AP to a homogeneous version and a heterogeneous version for high-order scenarios, demonstrating its robustness and flexibility in practical usage. Experimental results on ImageNet benchmarks demonstrate the compatibility and effectiveness on a much wider range of augmentations (e.g., Crop, Gray, Grid Shuffle, RandAugment), while consuming fewer parameters and lower computational costs at inference time. Source code:https://github.com/ap-conv/ap-net.