 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreconditioned Test-Time Adaptation for Out-of-Distribution Debiasing in Narrative Generation
Mar 14, 2026Although debiased LLMs perform well on known bias patterns, they often fail to generalize to unfamiliar bias prompts, producing toxic outputs. We first validate that such high-bias prompts constitute a \emph{distribution shift} via OOD detection, and show static models degrade under this shift. To adapt on-the-fly, we propose \textbf{CAP-TTA}, a test-time adaptation framework that performs context-aware LoRA updates only when the bias-risk \emph{trigger} exceeds a threshold, using a precomputed diagonal \emph{preconditioner} for fast and stable updates. Across toxic-prompt settings and benchmarks, CAP-TTA reduces bias (confirmed by human evaluation) while achieving much lower update latency than AdamW/SGD; it also mitigates catastrophic forgetting by significantly improving narrative fluency over SOTA debiasing baseline while maintaining comparable debiasing effectiveness.
LiteUpdate: A Lightweight Framework for Updating AI-Generated Image Detectors
Nov 10, 2025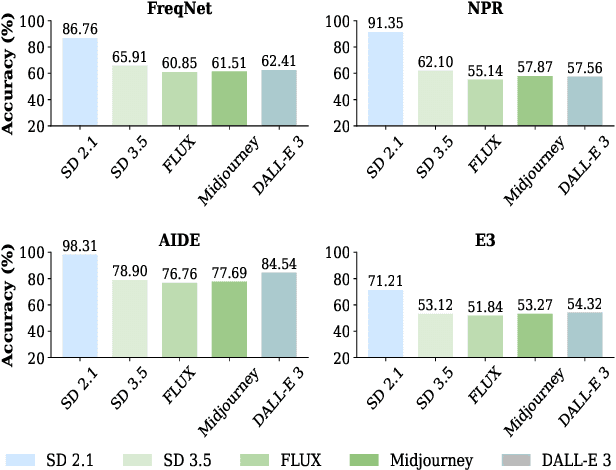
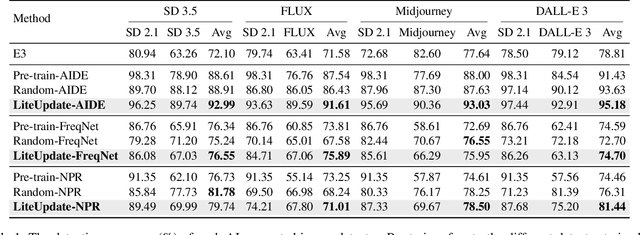
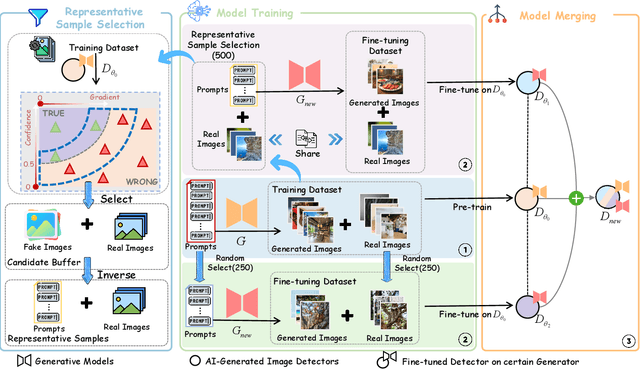
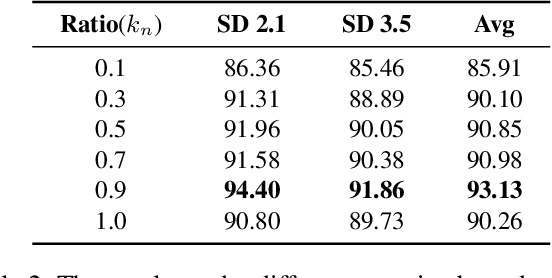
The rapid progress of generative AI has led to the emergence of new generative models, while existing detection methods struggle to keep pace, resulting in significant degradation in the detection performance. This highlights the urgent need for continuously updating AI-generated image detectors to adapt to new generators. To overcome low efficiency and catastrophic forgetting in detector updates, we propose LiteUpdate, a lightweight framework for updating AI-generated image detectors. LiteUpdate employs a representative sample selection module that leverages image confidence and gradient-based discriminative features to precisely select boundary samples. This approach improves learning and detection accuracy on new distributions with limited generated images, significantly enhancing detector update efficiency. Additionally, LiteUpdate incorporates a model merging module that fuses weights from multiple fine-tuning trajectories, including pre-trained, representative, and random updates. This balances the adaptability to new generators and mitigates the catastrophic forgetting of prior knowledge. Experiments demonstrate that LiteUpdate substantially boosts detection performance in various detectors. Specifically, on AIDE, the average detection accuracy on Midjourney improved from 87.63% to 93.03%, a 6.16% relative increase.
Enhancing Scene Transition Awareness in Video Generation via Post-Training
Jul 24, 2025Recent advances in AI-generated video have shown strong performance on \emph{text-to-video} tasks, particularly for short clips depicting a single scene. However, current models struggle to generate longer videos with coherent scene transitions, primarily because they cannot infer when a transition is needed from the prompt. Most open-source models are trained on datasets consisting of single-scene video clips, which limits their capacity to learn and respond to prompts requiring multiple scenes. Developing scene transition awareness is essential for multi-scene generation, as it allows models to identify and segment videos into distinct clips by accurately detecting transitions. To address this, we propose the \textbf{Transition-Aware Video} (TAV) dataset, which consists of preprocessed video clips with multiple scene transitions. Our experiment shows that post-training on the \textbf{TAV} dataset improves prompt-based scene transition understanding, narrows the gap between required and generated scenes, and maintains image quality.
360-Degree Video Super Resolution and Quality Enhancement Challenge: Methods and Results
Nov 11, 2024Omnidirectional (360-degree) video is rapidly gaining popularity due to advancements in immersive technologies like virtual reality (VR) and extended reality (XR). However, real-time streaming of such videos, especially in live mobile scenarios like unmanned aerial vehicles (UAVs), is challenged by limited bandwidth and strict latency constraints. Traditional methods, such as compression and adaptive resolution, help but often compromise video quality and introduce artifacts that degrade the viewer experience. Additionally, the unique spherical geometry of 360-degree video presents challenges not encountered in traditional 2D video. To address these issues, we initiated the 360-degree Video Super Resolution and Quality Enhancement Challenge. This competition encourages participants to develop efficient machine learning solutions to enhance the quality of low-bitrate compressed 360-degree videos, with two tracks focusing on 2x and 4x super-resolution (SR). In this paper, we outline the challenge framework, detailing the two competition tracks and highlighting the SR solutions proposed by the top-performing models. We assess these models within a unified framework, considering quality enhancement, bitrate gain, and computational efficiency. This challenge aims to drive innovation in real-time 360-degree video streaming, improving the quality and accessibility of immersive visual experiences.
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Oct 22, 2024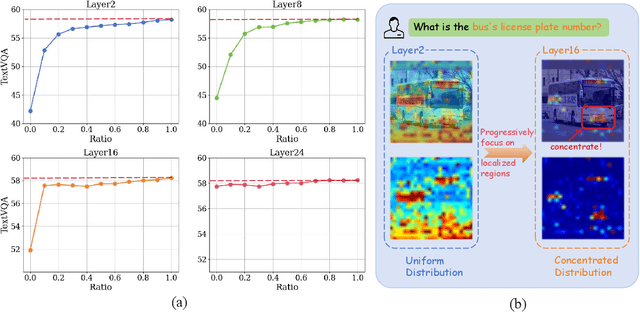
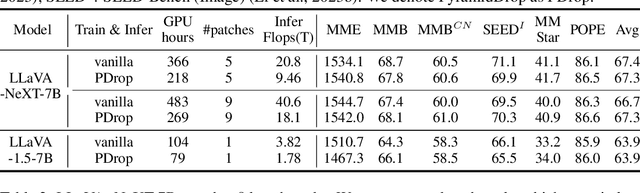
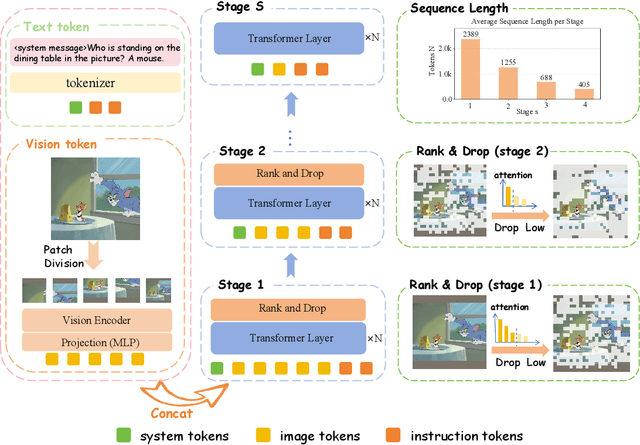
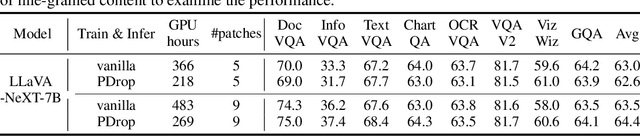
In large vision-language models (LVLMs), images serve as inputs that carry a wealth of information. As the idiom "A picture is worth a thousand words" implies, representing a single image in current LVLMs can require hundreds or even thousands of tokens. This results in significant computational costs, which grow quadratically as input image resolution increases, thereby severely impacting the efficiency of both training and inference. Previous approaches have attempted to reduce the number of image tokens either before or within the early layers of LVLMs. However, these strategies inevitably result in the loss of crucial image information, ultimately diminishing model performance. To address this challenge, we conduct an empirical study revealing that all visual tokens are necessary for LVLMs in the shallow layers, and token redundancy progressively increases in the deeper layers of the model. To this end, we propose PyramidDrop, a visual redundancy reduction strategy for LVLMs to boost their efficiency in both training and inference with neglectable performance loss. Specifically, we partition the LVLM into several stages and drop part of the image tokens at the end of each stage with a pre-defined ratio, creating pyramid-like visual tokens across model layers. The dropping is based on a lightweight similarity calculation with a negligible time overhead. Extensive experiments demonstrate that PyramidDrop can achieve a 40% training time and 55% inference FLOPs acceleration of LLaVA-NeXT with comparable performance. Besides, the PyramidDrop could also serve as a plug-and-play strategy for inference acceleration without training, with better performance and lower inference cost than counterparts. We hope that the insights and approach introduced by PyramidDrop will inspire future research to further investigate the role of image tokens in LVLMs.