 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360-Degree Video Super Resolution and Quality Enhancement Challenge: Methods and Results
Nov 11, 2024Omnidirectional (360-degree) video is rapidly gaining popularity due to advancements in immersive technologies like virtual reality (VR) and extended reality (XR). However, real-time streaming of such videos, especially in live mobile scenarios like unmanned aerial vehicles (UAVs), is challenged by limited bandwidth and strict latency constraints. Traditional methods, such as compression and adaptive resolution, help but often compromise video quality and introduce artifacts that degrade the viewer experience. Additionally, the unique spherical geometry of 360-degree video presents challenges not encountered in traditional 2D video. To address these issues, we initiated the 360-degree Video Super Resolution and Quality Enhancement Challenge. This competition encourages participants to develop efficient machine learning solutions to enhance the quality of low-bitrate compressed 360-degree videos, with two tracks focusing on 2x and 4x super-resolution (SR). In this paper, we outline the challenge framework, detailing the two competition tracks and highlighting the SR solutions proposed by the top-performing models. We assess these models within a unified framework, considering quality enhancement, bitrate gain, and computational efficiency. This challenge aims to drive innovation in real-time 360-degree video streaming, improving the quality and accessibility of immersive visual experiences.
ODVista: An Omnidirectional Video Dataset for super-resolution and Quality Enhancement Tasks
Mar 07, 2024



Omnidirectional or 360-degree video is being increasingly deployed, largely due to the latest advancements in immersive virtual reality (VR) and extended reality (XR) technology. However, the adoption of these videos in streaming encounters challenges related to bandwidth and latency, particularly in mobility conditions such as with unmanned aerial vehicles (UAVs). Adaptive resolution and compression aim to preserve quality while maintaining low latency under these constraints, yet downscaling and encoding can still degrade quality and introduce artifacts. Machine learning (ML)-based super-resolution (SR) and quality enhancement techniques offer a promising solution by enhancing detail recovery and reducing compression artifacts. However, current publicly available 360-degree video SR datasets lack compression artifacts, which limit research in this field. To bridge this gap, this paper introduces omnidirectional video streaming dataset (ODVista), which comprises 200 high-resolution and high quality videos downscaled and encoded at four bitrate ranges using the high-efficiency video coding (HEVC)/H.265 standard. Evaluations show that the dataset not only features a wide variety of scenes but also spans different levels of content complexity, which is crucial for robust solutions that perform well in real-world scenarios and generalize across diverse visual environments. Additionally, we evaluate the performance, considering both quality enhancement and runtime, of two handcrafted and two ML-based SR models on the validation and testing sets of ODVista.
Bitrate Ladder Prediction Methods for Adaptive Video Streaming: A Review and Benchmark
Oct 30, 2023HTTP adaptive streaming (HAS) has emerged as a widely adopted approach for over-the-top (OTT) video streaming services, due to its ability to deliver a seamless streaming experience. A key component of HAS is the bitrate ladder, which provides the encoding parameters (e.g., bitrate-resolution pairs) to encode the source video. The representations in the bitrate ladder allow the client's player to dynamically adjust the quality of the video stream based on network conditions by selecting the most appropriate representation from the bitrate ladder. The most straightforward and lowest complexity approach involves using a fixed bitrate ladder for all videos, consisting of pre-determined bitrate-resolution pairs known as one-size-fits-all. Conversely, the most reliable technique relies on intensively encoding all resolutions over a wide range of bitrates to build the convex hull, thereby optimizing the bitrate ladder for each specific video. Several techniques have been proposed to predict content-based ladders without performing a costly exhaustive search encoding. This paper provides a comprehensive review of various methods, including both conventional and learning-based approaches. Furthermore, we conduct a benchmark study focusing exclusively on various learning-based approaches for predicting content-optimized bitrate ladders across multiple codec settings. The considered methods are evaluated on our proposed large-scale dataset, which includes 300 UHD video shots encoded with software and hardware encoders using three state-of-the-art encoders, including AVC/H.264, HEVC/H.265, and VVC/H.266, at various bitrate points. Our analysis provides baseline methods and insights, which will be valuable for future research in the field of bitrate ladder prediction. The source code of the proposed benchmark and the dataset will be made publicly available upon acceptance of the paper.
2BiVQA: Double Bi-LSTM based Video Quality Assessment of UGC Videos
Aug 31, 2022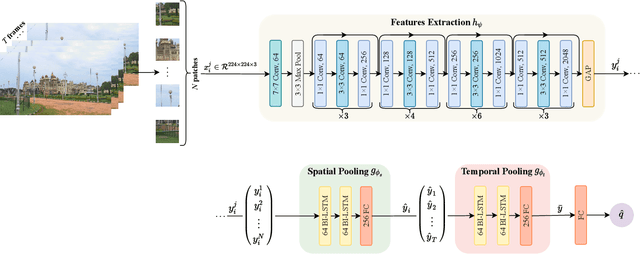
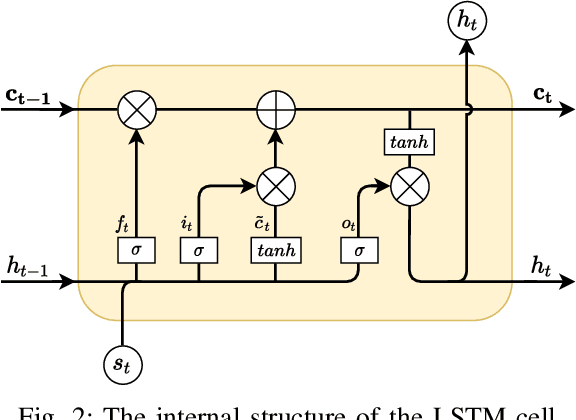
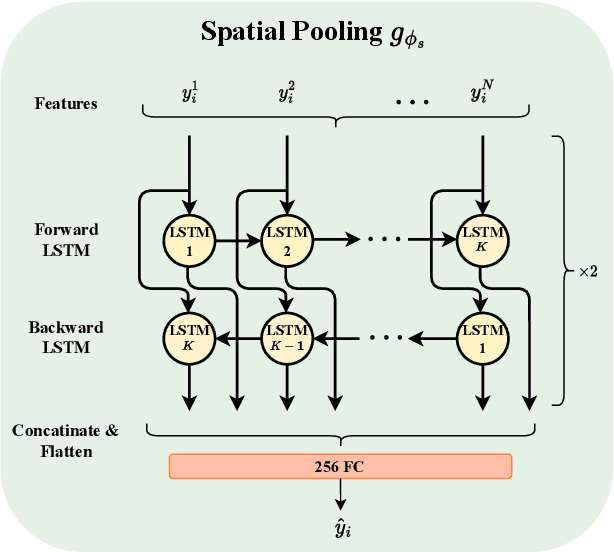
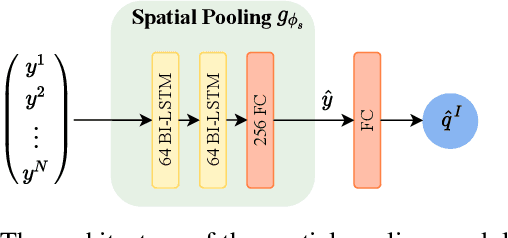
Recently, with the growing popularity of mobile devices as well as video sharing platforms (e.g., YouTube, Facebook, TikTok, and Twitch), User-Generated Content (UGC) videos have become increasingly common and now account for a large portion of multimedia traffic on the internet. Unlike professionally generated videos produced by filmmakers and videographers, typically, UGC videos contain multiple authentic distortions, generally introduced during capture and processing by naive users. Quality prediction of UGC videos is of paramount importance to optimize and monitor their processing in hosting platforms, such as their coding, transcoding, and streaming. However, blind quality prediction of UGC is quite challenging because the degradations of UGC videos are unknown and very diverse, in addition to the unavailability of pristine reference. Therefore, in this paper, we propose an accurate and efficient Blind Video Quality Assessment (BVQA) model for UGC videos, which we name 2BiVQA for double Bi-LSTM Video Quality Assessment. 2BiVQA metric consists of three main blocks, including a pre-trained Convolutional Neural Network (CNN) to extract discriminative features from image patches, which are then fed into two Recurrent Neural Networks (RNNs) for spatial and temporal pooling. Specifically, we use two Bi-directional Long Short Term Memory (Bi-LSTM) networks, the first is used to capture short-range dependencies between image patches, while the second allows capturing long-range dependencies between frames to account for the temporal memory effect. Experimental results on recent large-scale UGC video quality datasets show that 2BiVQA achieves high performance at a lower computational cost than state-of-the-art models. The source code of our 2BiVQA metric is made publicly available at: https://github.com/atelili/2BiVQA.