 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Quality Optimization of Image Super-Resolution
Feb 25, 2026Single-image super-resolution (SR) has achieved remarkable progress with deep learning, yet most approaches rely on distortion-oriented losses or heuristic perceptual priors, which often lead to a trade-off between fidelity and visual quality. To address this issue, we propose an \textit{Efficient Perceptual Bi-directional Attention Network (Efficient-PBAN)} that explicitly optimizes SR towards human-preferred quality. Unlike patch-based quality models, Efficient-PBAN avoids extensive patch sampling and enables efficient image-level perception. The proposed framework is trained on our self-constructed SR quality dataset that covers a wide range of state-of-the-art SR methods with corresponding human opinion scores. Using this dataset, Efficient-PBAN learns to predict perceptual quality in a way that correlates strongly with subjective judgments. The learned metric is further integrated into SR training as a differentiable perceptual loss, enabling closed-loop alignment between reconstruction and perceptual assessment. Extensive experiments demonstrate that our approach delivers superior perceptual quality. Code is publicly available at https://github.com/Lighting-YXLI/Efficient-PBAN.
Is there a relationship between Mean Opinion Score (MOS) and Just Noticeable Difference (JND)?
Feb 19, 2026Evaluating perceived video quality is essential for ensuring high Quality of Experience (QoE) in modern streaming applications. While existing subjective datasets and Video Quality Metrics (VQMs) cover a broad quality range, many practical use cases especially for premium users focus on high quality scenarios requiring finer granularity. Just Noticeable Difference (JND) has emerged as a key concept for modeling perceptual thresholds in these high end regions and plays an important role in perceptual bitrate ladder construction. However, the relationship between JND and the more widely used Mean Opinion Score (MOS) remains unclear. In this paper, we conduct a Degradation Category Rating (DCR) subjective study based on an existing JND dataset to examine how MOS corresponds to the 75% Satisfied User Ratio (SUR) points of the 1st and 2nd JNDs. We find that while MOS values at JND points generally align with theoretical expectations (e.g., 4.75 for the 75% SUR of the 1st JND), the reverse mapping from MOS to JND is ambiguous due to overlapping confidence intervals across PVS indices. Statistical significance analysis further shows that DCR studies with limited participants may not detect meaningful differences between reference and JND videos.
eMotions: A Large-Scale Dataset and Audio-Visual Fusion Network for Emotion Analysis in Short-form Videos
Aug 09, 2025Short-form videos (SVs) have become a vital part of our online routine for acquiring and sharing information. Their multimodal complexity poses new challenges for video analysis, highlighting the need for video emotion analysis (VEA) within the community. Given the limited availability of SVs emotion data, we introduce eMotions, a large-scale dataset consisting of 27,996 videos with full-scale annotations. To ensure quality and reduce subjective bias, we emphasize better personnel allocation and propose a multi-stage annotation procedure. Additionally, we provide the category-balanced and test-oriented variants through targeted sampling to meet diverse needs. While there have been significant studies on videos with clear emotional cues (e.g., facial expressions), analyzing emotions in SVs remains a challenging task. The challenge arises from the broader content diversity, which introduces more distinct semantic gaps and complicates the representations learning of emotion-related features. Furthermore, the prevalence of audio-visual co-expressions in SVs leads to the local biases and collective information gaps caused by the inconsistencies in emotional expressions. To tackle this, we propose AV-CANet, an end-to-end audio-visual fusion network that leverages video transformer to capture semantically relevant representations. We further introduce the Local-Global Fusion Module designed to progressively capture the correlations of audio-visual features. Besides, EP-CE Loss is constructed to globally steer optimizations with tripolar penalties. Extensive experiments across three eMotions-related datasets and four public VEA datasets demonstrate the effectiveness of our proposed AV-CANet, while providing broad insights for future research. Moreover, we conduct ablation studies to examine the critical components of our method. Dataset and code will be made available at Github.
CLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
Feb 03, 2025Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods. The code is available at https://github.com/JunFu1995/CLIP-DQA.
EPS: Efficient Patch Sampling for Video Overfitting in Deep Super-Resolution Model Training
Nov 25, 2024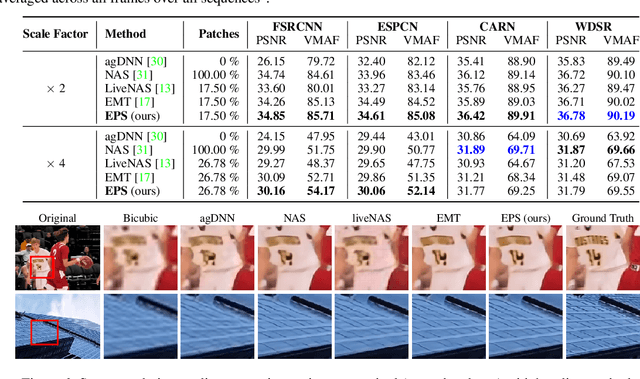
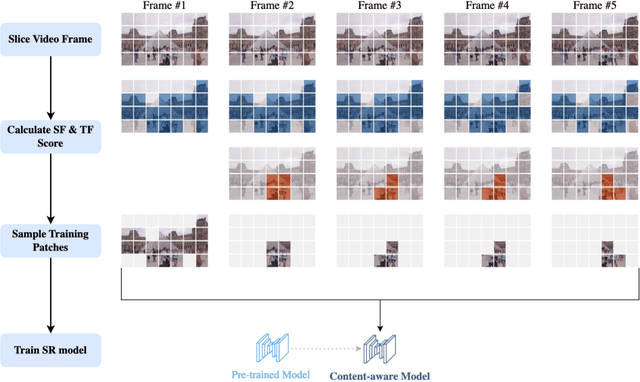

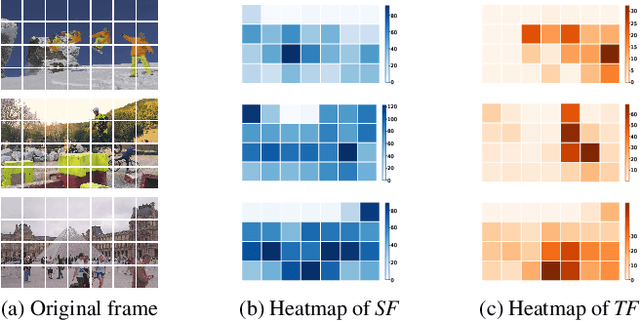
Leveraging the overfitting property of deep neural networks (DNNs) is trending in video delivery systems to enhance quality within bandwidth limits. Existing approaches transmit overfitted super-resolution (SR) model streams for low-resolution (LR) bitstreams, which are used to reconstruct high-resolution (HR) videos at the decoder. Although these approaches show promising results, the huge computational costs of training a large number of video frames limit their practical applications. To overcome this challenge, we propose an efficient patch sampling method named EPS for video SR network overfitting, which identifies the most valuable training patches from video frames. To this end, we first present two low-complexity Discrete Cosine Transform (DCT)-based spatial-temporal features to measure the complexity score of each patch directly. By analyzing the histogram distribution of these features, we then categorize all possible patches into different clusters and select training patches from the cluster with the highest spatial-temporal information. The number of sampled patches is adaptive based on the video content, addressing the trade-off between training complexity and efficiency. Our method reduces the number of patches for the training to 4% to 25%, depending on the resolution and number of clusters, while maintaining high video quality and significantly enhancing training efficiency. Compared to the state-of-the-art patch sampling method, EMT, our approach achieves an 83% decrease in overall run time.
360-Degree Video Super Resolution and Quality Enhancement Challenge: Methods and Results
Nov 11, 2024Omnidirectional (360-degree) video is rapidly gaining popularity due to advancements in immersive technologies like virtual reality (VR) and extended reality (XR). However, real-time streaming of such videos, especially in live mobile scenarios like unmanned aerial vehicles (UAVs), is challenged by limited bandwidth and strict latency constraints. Traditional methods, such as compression and adaptive resolution, help but often compromise video quality and introduce artifacts that degrade the viewer experience. Additionally, the unique spherical geometry of 360-degree video presents challenges not encountered in traditional 2D video. To address these issues, we initiated the 360-degree Video Super Resolution and Quality Enhancement Challenge. This competition encourages participants to develop efficient machine learning solutions to enhance the quality of low-bitrate compressed 360-degree videos, with two tracks focusing on 2x and 4x super-resolution (SR). In this paper, we outline the challenge framework, detailing the two competition tracks and highlighting the SR solutions proposed by the top-performing models. We assess these models within a unified framework, considering quality enhancement, bitrate gain, and computational efficiency. This challenge aims to drive innovation in real-time 360-degree video streaming, improving the quality and accessibility of immersive visual experiences.
ODVista: An Omnidirectional Video Dataset for super-resolution and Quality Enhancement Tasks
Mar 07, 2024



Omnidirectional or 360-degree video is being increasingly deployed, largely due to the latest advancements in immersive virtual reality (VR) and extended reality (XR) technology. However, the adoption of these videos in streaming encounters challenges related to bandwidth and latency, particularly in mobility conditions such as with unmanned aerial vehicles (UAVs). Adaptive resolution and compression aim to preserve quality while maintaining low latency under these constraints, yet downscaling and encoding can still degrade quality and introduce artifacts. Machine learning (ML)-based super-resolution (SR) and quality enhancement techniques offer a promising solution by enhancing detail recovery and reducing compression artifacts. However, current publicly available 360-degree video SR datasets lack compression artifacts, which limit research in this field. To bridge this gap, this paper introduces omnidirectional video streaming dataset (ODVista), which comprises 200 high-resolution and high quality videos downscaled and encoded at four bitrate ranges using the high-efficiency video coding (HEVC)/H.265 standard. Evaluations show that the dataset not only features a wide variety of scenes but also spans different levels of content complexity, which is crucial for robust solutions that perform well in real-world scenarios and generalize across diverse visual environments. Additionally, we evaluate the performance, considering both quality enhancement and runtime, of two handcrafted and two ML-based SR models on the validation and testing sets of ODVista.
Bitrate Ladder Prediction Methods for Adaptive Video Streaming: A Review and Benchmark
Oct 30, 2023HTTP adaptive streaming (HAS) has emerged as a widely adopted approach for over-the-top (OTT) video streaming services, due to its ability to deliver a seamless streaming experience. A key component of HAS is the bitrate ladder, which provides the encoding parameters (e.g., bitrate-resolution pairs) to encode the source video. The representations in the bitrate ladder allow the client's player to dynamically adjust the quality of the video stream based on network conditions by selecting the most appropriate representation from the bitrate ladder. The most straightforward and lowest complexity approach involves using a fixed bitrate ladder for all videos, consisting of pre-determined bitrate-resolution pairs known as one-size-fits-all. Conversely, the most reliable technique relies on intensively encoding all resolutions over a wide range of bitrates to build the convex hull, thereby optimizing the bitrate ladder for each specific video. Several techniques have been proposed to predict content-based ladders without performing a costly exhaustive search encoding. This paper provides a comprehensive review of various methods, including both conventional and learning-based approaches. Furthermore, we conduct a benchmark study focusing exclusively on various learning-based approaches for predicting content-optimized bitrate ladders across multiple codec settings. The considered methods are evaluated on our proposed large-scale dataset, which includes 300 UHD video shots encoded with software and hardware encoders using three state-of-the-art encoders, including AVC/H.264, HEVC/H.265, and VVC/H.266, at various bitrate points. Our analysis provides baseline methods and insights, which will be valuable for future research in the field of bitrate ladder prediction. The source code of the proposed benchmark and the dataset will be made publicly available upon acceptance of the paper.
MU-MIMO Grouping For Real-time Applications
Jul 26, 2021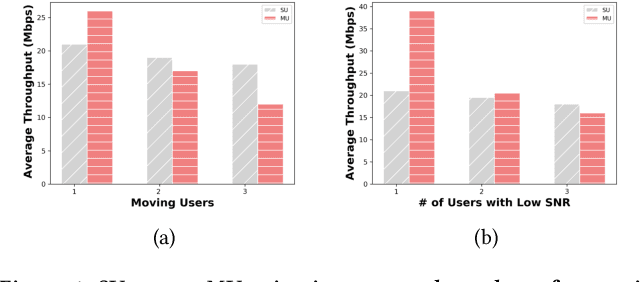
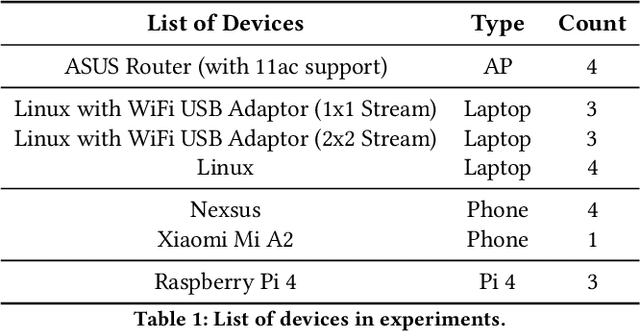
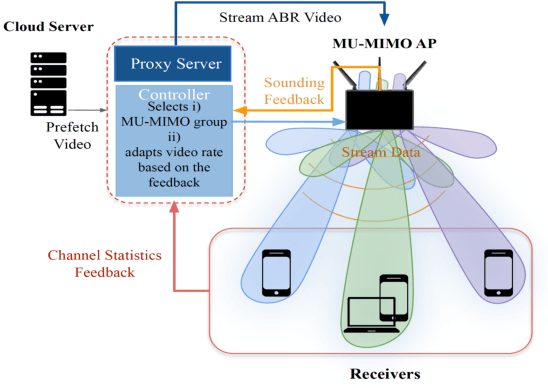
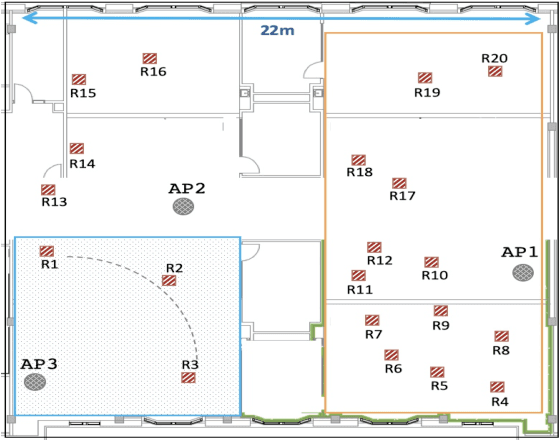
Over the last decade, the bandwidth expansion and MU-MIMO spectral efficiency have promised to increase data throughput by allowing concurrent communication between one Access Point and multiple users. However, we are still a long way from enjoying such MU-MIMO MAC protocol improvements for bandwidth hungry applications such as video streaming in practical WiFi network settings due to heterogeneous channel conditions and devices, unreliable transmissions, and lack of useful feedback exchange among the lower and upper layers' requirements. This paper introduces MuViS, a novel dual-phase optimization framework that proposes a Quality of Experience (QoE) aware MU-MIMO optimization for multi-user video streaming over IEEE 802.11ac. MuViS first employs reinforcement learning to optimize the MU-MIMO user group and mode selection for users based on their PHY/MAC layer characteristics. The video bitrate is then optimized based on the user's mode (Multi-User (MU) or Single-User (SU)). We present our design and its evaluation on smartphones and laptops using 802.11ac WiFi. Our experimental results in various indoor environments and configurations show a scalable framework that can support a large number of users with streaming at high video rates and satisfying QoE requirements.
Fast and Efficient Lenslet Image Compression
Jan 27, 2019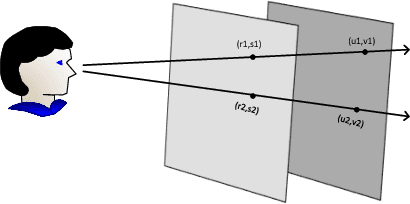

Light field imaging is characterized by capturing brightness, color, and directional information of light rays in a scene. This leads to image representations with huge amount of data that require efficient coding schemes. In this paper, lenslet images are rendered into sub-aperture images. These images are organized as a pseudo-sequence input for the HEVC video codec. To better exploit redundancy among the neighboring sub-aperture images and consequently decrease the distances between a sub-aperture image and its references used for prediction, sub-aperture images are divided into four smaller groups that are scanned in a serpentine order. The most central sub-aperture image, which has the highest similarity to all the other images, is used as the initial reference image for each of the four regions. Furthermore, a structure is defined that selects spatially adjacent sub-aperture images as prediction references with the highest similarity to the current image. In this way, encoding efficiency increases, and furthermore it leads to a higher similarity among the co-located Coding Three Units (CTUs). The similarities among the co-located CTUs are exploited to predict Coding Unit depths.Moreover, independent encoding of each group division enables parallel processing, that along with the proposed coding unit depth prediction decrease the encoding execution time by almost 80% on average. Simulation results show that Rate-Distortion performance of the proposed method has higher compression gain than the other state-of-the-art lenslet compression methods with lower computational complexity.