 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeMotions: A Large-Scale Dataset and Audio-Visual Fusion Network for Emotion Analysis in Short-form Videos
Aug 09, 2025Short-form videos (SVs) have become a vital part of our online routine for acquiring and sharing information. Their multimodal complexity poses new challenges for video analysis, highlighting the need for video emotion analysis (VEA) within the community. Given the limited availability of SVs emotion data, we introduce eMotions, a large-scale dataset consisting of 27,996 videos with full-scale annotations. To ensure quality and reduce subjective bias, we emphasize better personnel allocation and propose a multi-stage annotation procedure. Additionally, we provide the category-balanced and test-oriented variants through targeted sampling to meet diverse needs. While there have been significant studies on videos with clear emotional cues (e.g., facial expressions), analyzing emotions in SVs remains a challenging task. The challenge arises from the broader content diversity, which introduces more distinct semantic gaps and complicates the representations learning of emotion-related features. Furthermore, the prevalence of audio-visual co-expressions in SVs leads to the local biases and collective information gaps caused by the inconsistencies in emotional expressions. To tackle this, we propose AV-CANet, an end-to-end audio-visual fusion network that leverages video transformer to capture semantically relevant representations. We further introduce the Local-Global Fusion Module designed to progressively capture the correlations of audio-visual features. Besides, EP-CE Loss is constructed to globally steer optimizations with tripolar penalties. Extensive experiments across three eMotions-related datasets and four public VEA datasets demonstrate the effectiveness of our proposed AV-CANet, while providing broad insights for future research. Moreover, we conduct ablation studies to examine the critical components of our method. Dataset and code will be made available at Github.
3A-YOLO: New Real-Time Object Detectors with Triple Discriminative Awareness and Coordinated Representations
Dec 10, 2024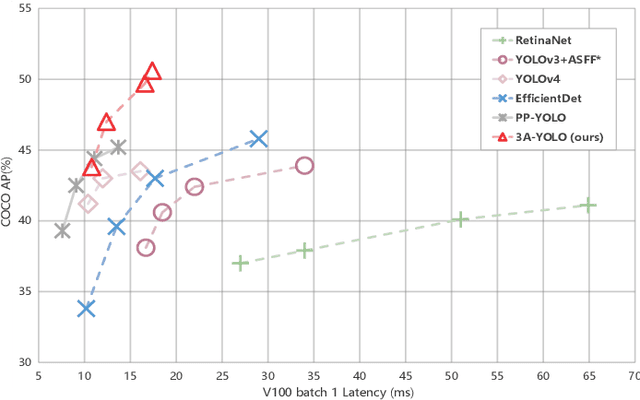
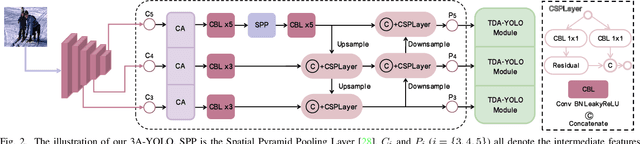
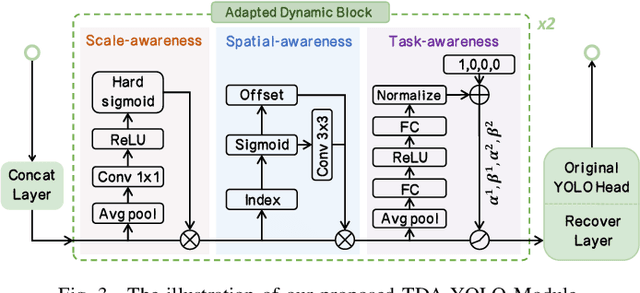
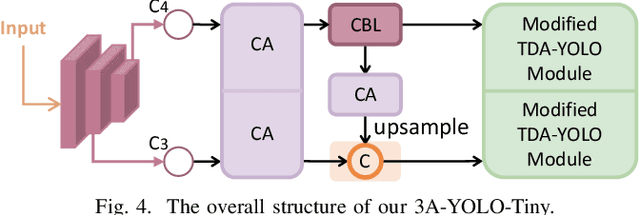
Recent research on real-time object detectors (e.g., YOLO series) has demonstrated the effectiveness of attention mechanisms for elevating model performance. Nevertheless, existing methods neglect to unifiedly deploy hierarchical attention mechanisms to construct a more discriminative YOLO head which is enriched with more useful intermediate features. To tackle this gap, this work aims to leverage multiple attention mechanisms to hierarchically enhance the triple discriminative awareness of the YOLO detection head and complementarily learn the coordinated intermediate representations, resulting in a new series detectors denoted 3A-YOLO. Specifically, we first propose a new head denoted TDA-YOLO Module, which unifiedly enhance the representations learning of scale-awareness, spatial-awareness, and task-awareness. Secondly, we steer the intermediate features to coordinately learn the inter-channel relationships and precise positional information. Finally, we perform neck network improvements followed by introducing various tricks to boost the adaptability of 3A-YOLO. Extensive experiments across COCO and VOC benchmarks indicate the effectiveness of our detectors.
eMotions: A Large-Scale Dataset for Emotion Recognition in Short Videos
Nov 29, 2023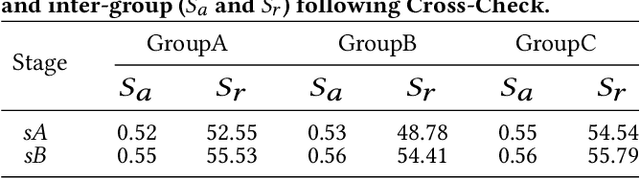
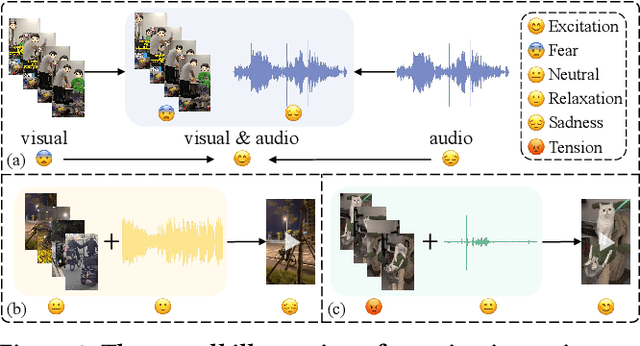
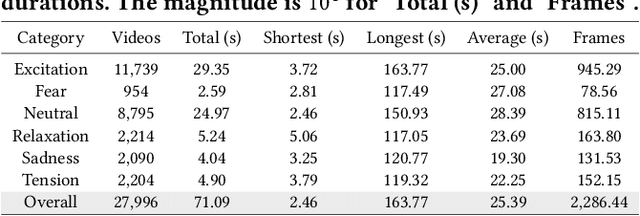
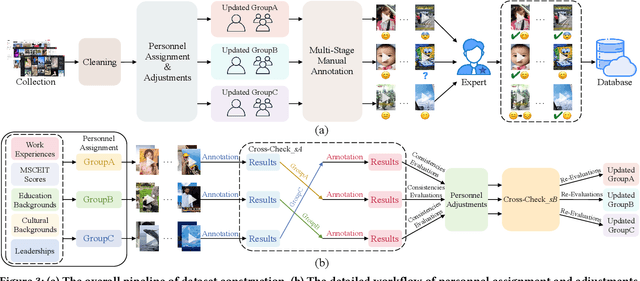
Nowadays, short videos (SVs) are essential to information acquisition and sharing in our life. The prevailing use of SVs to spread emotions leads to the necessity of emotion recognition in SVs. Considering the lack of SVs emotion data, we introduce a large-scale dataset named eMotions, comprising 27,996 videos. Meanwhile, we alleviate the impact of subjectivities on labeling quality by emphasizing better personnel allocations and multi-stage annotations. In addition, we provide the category-balanced and test-oriented variants through targeted data sampling. Some commonly used videos (e.g., facial expressions and postures) have been well studied. However, it is still challenging to understand the emotions in SVs. Since the enhanced content diversity brings more distinct semantic gaps and difficulties in learning emotion-related features, and there exists information gaps caused by the emotion incompleteness under the prevalently audio-visual co-expressions. To tackle these problems, we present an end-to-end baseline method AV-CPNet that employs the video transformer to better learn semantically relevant representations. We further design the two-stage cross-modal fusion module to complementarily model the correlations of audio-visual features. The EP-CE Loss, incorporating three emotion polarities, is then applied to guide model optimization. Extensive experimental results on nine datasets verify the effectiveness of AV-CPNet. Datasets and code will be open on https://github.com/XuecWu/eMotions.