 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART: Dual-level Autonomous Robotic Topology for Efficient Exploration in Unknown Environments
Mar 17, 2025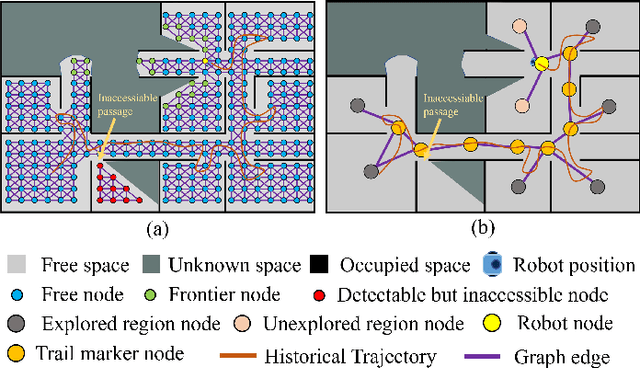
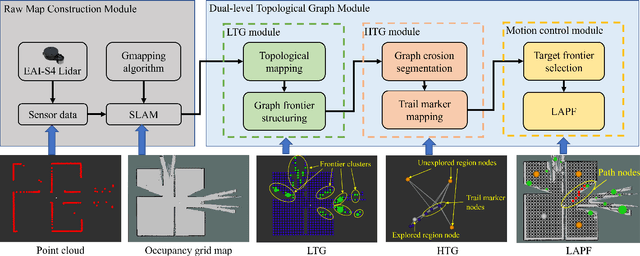

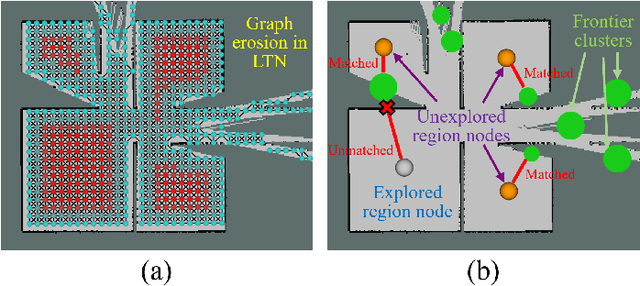
Conventional algorithms in autonomous exploration face challenges due to their inability to accurately and efficiently identify the spatial distribution of convex regions in the real-time map. These methods often prioritize navigation toward the nearest or information-rich frontiers -- the boundaries between known and unknown areas -- resulting in incomplete convex region exploration and requiring excessive backtracking to revisit these missed areas. To address these limitations, this paper introduces an innovative dual-level topological analysis approach. First, we introduce a Low-level Topological Graph (LTG), generated through uniform sampling of the original map data, which captures essential geometric and connectivity details. Next, the LTG is transformed into a High-level Topological Graph (HTG), representing the spatial layout and exploration completeness of convex regions, prioritizing the exploration of convex regions that are not fully explored and minimizing unnecessary backtracking. Finally, an novel Local Artificial Potential Field (LAPF) method is employed for motion control, replacing conventional path planning and boosting overall efficiency. Experimental results highlight the effectiveness of our approach. Simulation tests reveal that our framework significantly reduces exploration time and travel distance, outperforming existing methods in both speed and efficiency. Ablation studies confirm the critical role of each framework component. Real-world tests demonstrate the robustness of our method in environments with poor mapping quality, surpassing other approaches in adaptability to mapping inaccuracies and inaccessible areas.
eMotions: A Large-Scale Dataset for Emotion Recognition in Short Videos
Nov 29, 2023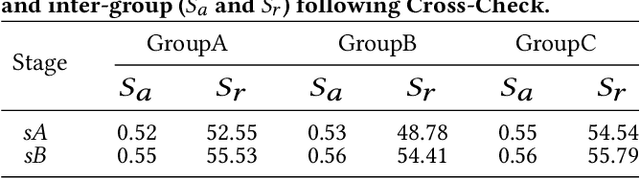
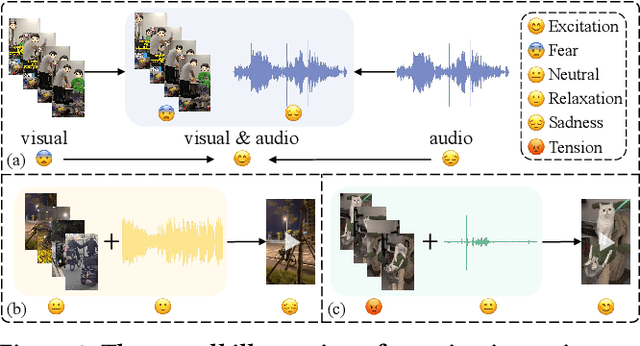
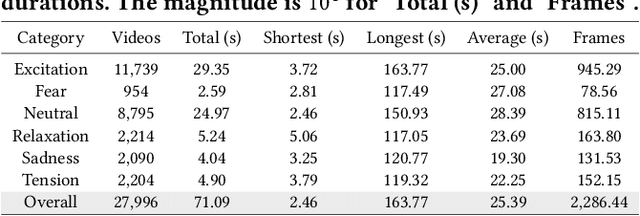
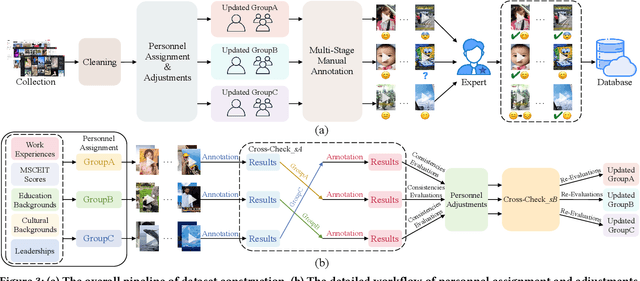
Nowadays, short videos (SVs) are essential to information acquisition and sharing in our life. The prevailing use of SVs to spread emotions leads to the necessity of emotion recognition in SVs. Considering the lack of SVs emotion data, we introduce a large-scale dataset named eMotions, comprising 27,996 videos. Meanwhile, we alleviate the impact of subjectivities on labeling quality by emphasizing better personnel allocations and multi-stage annotations. In addition, we provide the category-balanced and test-oriented variants through targeted data sampling. Some commonly used videos (e.g., facial expressions and postures) have been well studied. However, it is still challenging to understand the emotions in SVs. Since the enhanced content diversity brings more distinct semantic gaps and difficulties in learning emotion-related features, and there exists information gaps caused by the emotion incompleteness under the prevalently audio-visual co-expressions. To tackle these problems, we present an end-to-end baseline method AV-CPNet that employs the video transformer to better learn semantically relevant representations. We further design the two-stage cross-modal fusion module to complementarily model the correlations of audio-visual features. The EP-CE Loss, incorporating three emotion polarities, is then applied to guide model optimization. Extensive experimental results on nine datasets verify the effectiveness of AV-CPNet. Datasets and code will be open on https://github.com/XuecWu/eMotions.
Multi-Agent Path Planning based on MPC and DDPG
Feb 26, 2021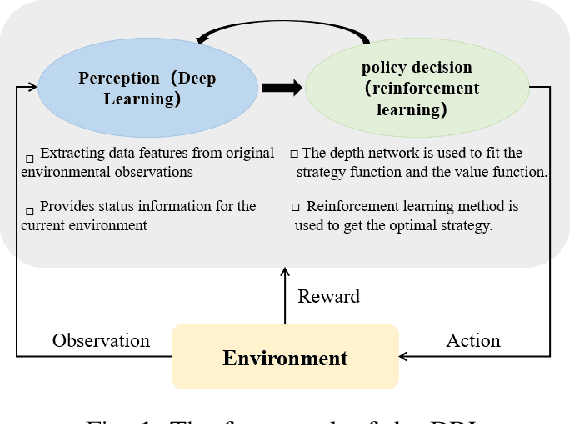
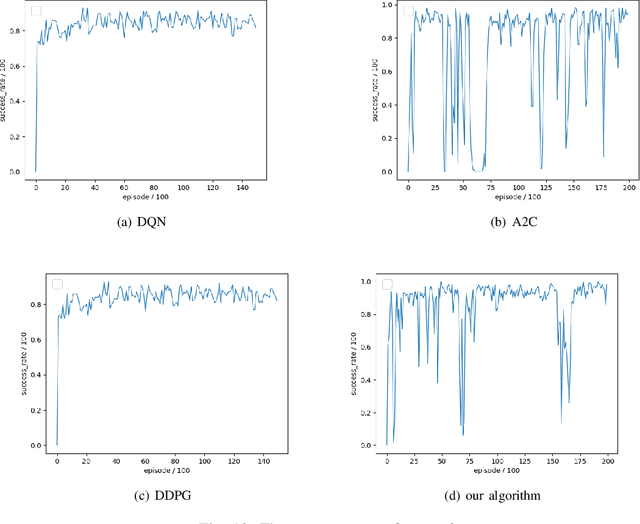
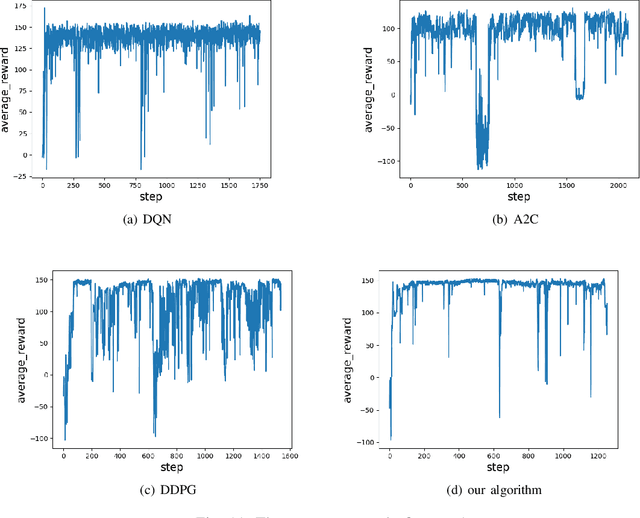
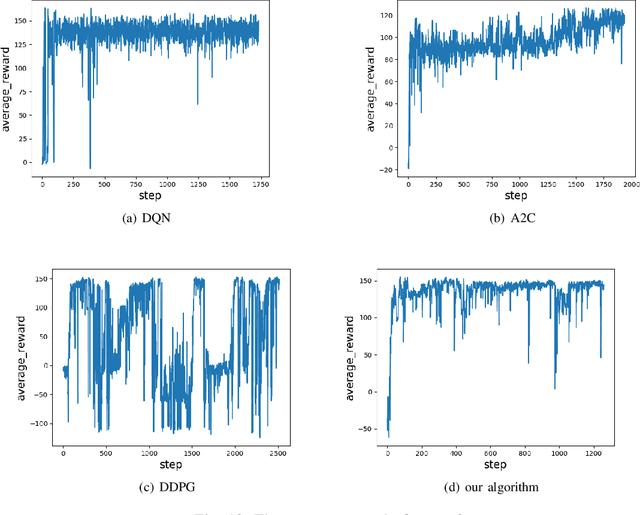
The problem of mixed static and dynamic obstacle avoidance is essential for path planning in highly dynamic environment. However, the paths formed by grid edges can be longer than the true shortest paths in the terrain since their headings are artificially constrained. Existing methods can hardly deal with dynamic obstacles. To address this problem, we propose a new algorithm combining Model Predictive Control (MPC) with Deep Deterministic Policy Gradient (DDPG). Firstly, we apply the MPC algorithm to predict the trajectory of dynamic obstacles. Secondly, the DDPG with continuous action space is designed to provide learning and autonomous decision-making capability for robots. Finally, we introduce the idea of the Artificial Potential Field to set the reward function to improve convergence speed and accuracy. We employ Unity 3D to perform simulation experiments in highly uncertain environment such as aircraft carrier decks and squares. The results show that our method has made great improvement on accuracy by 7%-30% compared with the other methods, and on the length of the path and turning angle by reducing 100 units and 400-450 degrees compared with DQN (Deep Q Network), respectively.