 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffVC: A Non-autoregressive Framework Based on Diffusion Model for Video Captioning
Apr 09, 2026Current video captioning methods usually use an encoder-decoder structure to generate text autoregressively. However, autoregressive methods have inherent limitations such as slow generation speed and large cumulative error. Furthermore, the few non-autoregressive counterparts suffer from deficiencies in generation quality due to the lack of sufficient multimodal interaction modeling. Therefore, we propose a non-autoregressive framework based on Diffusion model for Video Captioning (DiffVC) to address these issues. Its parallel decoding can effectively solve the problems of generation speed and cumulative error. At the same time, our proposed discriminative conditional Diffusion Model can generate higher-quality textual descriptions. Specifically, we first encode the video into a visual representation. During training, Gaussian noise is added to the textual representation of the ground-truth caption. Then, a new textual representation is generated via the discriminative denoiser with the visual representation as a conditional constraint. Finally, we input the new textual representation into a non-autoregressive language model to generate captions. During inference, we directly sample noise from the Gaussian distribution for generation. Experiments on MSVD, MSR-VTT, and VATEX show that our method can outperform previous non-autoregressive methods and achieve comparable performance to autoregressive methods, e.g., it achieved a maximum improvement of 9.9 on the CIDEr and improvement of 2.6 on the B@4, while having faster generation speed. The source code will be available soon.
EPIR: An Efficient Patch Tokenization, Integration and Representation Framework for Micro-expression Recognition
Apr 09, 2026Micro-expression recognition can obtain the real emotion of the individual at the current moment. Although deep learning-based methods, especially Transformer-based methods, have achieved impressive results, these methods have high computational complexity due to the large number of tokens in the multi-head self-attention. In addition, the existing micro-expression datasets are small-scale, which makes it difficult for Transformer-based models to learn effective micro-expression representations. Therefore, we propose a novel Efficient Patch tokenization, Integration and Representation framework (EPIR), which can balance high recognition performance and low computational complexity. Specifically, we first propose a dual norm shifted tokenization (DNSPT) module to learn the spatial relationship between neighboring pixels in the face region, which is implemented by a refined spatial transformation and dual norm projection. Then, we propose a token integration module to integrate partial tokens among multiple cascaded Transformer blocks, thereby reducing the number of tokens without information loss. Furthermore, we design a discriminative token extractor, which first improves the attention in the Transformer block to reduce the unnecessary focus of the attention calculation on self-tokens, and uses the dynamic token selection module (DTSM) to select key tokens, thereby capturing more discriminative micro-expression representations. We conduct extensive experiments on four popular public datasets (i.e., CASME II, SAMM, SMIC, and CAS(ME)3. The experimental results show that our method achieves significant performance gains over the state-of-the-art methods, such as 9.6% improvement on the CAS(ME)$^3$ dataset in terms of UF1 and 4.58% improvement on the SMIC dataset in terms of UAR metric.
FED-Bench: A Cross-Granular Benchmark for Disentangled Evaluation of Facial Expression Editing
Mar 31, 2026Facial expression image editing requires fine-grained control to strictly preserve human identity and background while precisely manipulating expression. However, existing editing benchmarks primarily focus on general scenarios, lacking high-quality facial images and corresponding editing instructions. Furthermore, current evaluation metrics exhibit systemic biases in this task, often favoring lazy editing or overfit editing. To bridge these gaps, we propose FED-Bench, a comprehensive benchmark featuring rigorous testing and an accurate evaluation suite. First, we carefully construct a benchmark of 747 triplets through a cascaded and scalable pipeline, each comprising an original image, an editing instruction, and a ground-truth image for precise evaluation. Second, we introduce FED-Score, a cross-granularity evaluation protocol that disentangles assessment into three dimensions: Alignment for verifying instruction following, Fidelity for testing image quality and identity preservation, and Relative Expression Gain for quantifying the magnitude of expression changes, effectively mitigating the aforementioned evaluation biases. Third, we benchmark 18 image editing models, revealing that current approaches struggle to simultaneously achieve high fidelity and accurate expression manipulation, with fine-grained instruction following identified as the primary bottleneck. Finally, leveraging the scalable characteristic of introduced benchmark engine, we provide a 20k+ in-the-wild facial training set and demonstrate its effectiveness by fine-tuning a baseline model that achieves significant performance gains. Our benchmark and related code will be made publicly open soon.
eMotions: A Large-Scale Dataset and Audio-Visual Fusion Network for Emotion Analysis in Short-form Videos
Aug 09, 2025Short-form videos (SVs) have become a vital part of our online routine for acquiring and sharing information. Their multimodal complexity poses new challenges for video analysis, highlighting the need for video emotion analysis (VEA) within the community. Given the limited availability of SVs emotion data, we introduce eMotions, a large-scale dataset consisting of 27,996 videos with full-scale annotations. To ensure quality and reduce subjective bias, we emphasize better personnel allocation and propose a multi-stage annotation procedure. Additionally, we provide the category-balanced and test-oriented variants through targeted sampling to meet diverse needs. While there have been significant studies on videos with clear emotional cues (e.g., facial expressions), analyzing emotions in SVs remains a challenging task. The challenge arises from the broader content diversity, which introduces more distinct semantic gaps and complicates the representations learning of emotion-related features. Furthermore, the prevalence of audio-visual co-expressions in SVs leads to the local biases and collective information gaps caused by the inconsistencies in emotional expressions. To tackle this, we propose AV-CANet, an end-to-end audio-visual fusion network that leverages video transformer to capture semantically relevant representations. We further introduce the Local-Global Fusion Module designed to progressively capture the correlations of audio-visual features. Besides, EP-CE Loss is constructed to globally steer optimizations with tripolar penalties. Extensive experiments across three eMotions-related datasets and four public VEA datasets demonstrate the effectiveness of our proposed AV-CANet, while providing broad insights for future research. Moreover, we conduct ablation studies to examine the critical components of our method. Dataset and code will be made available at Github.
3A-YOLO: New Real-Time Object Detectors with Triple Discriminative Awareness and Coordinated Representations
Dec 10, 2024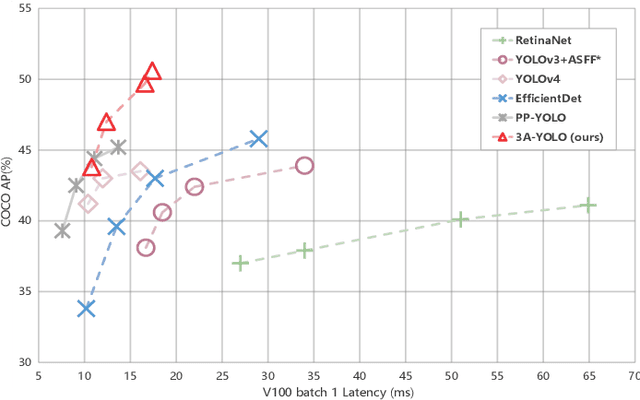
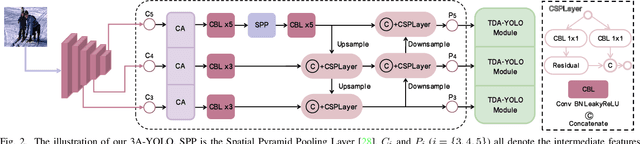
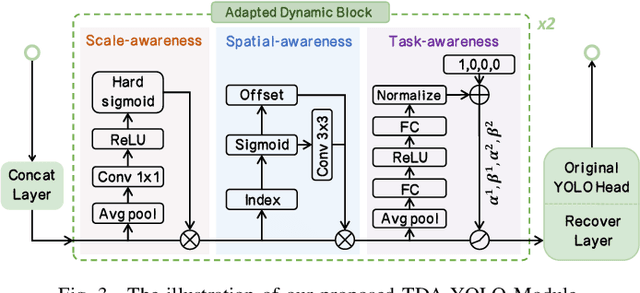
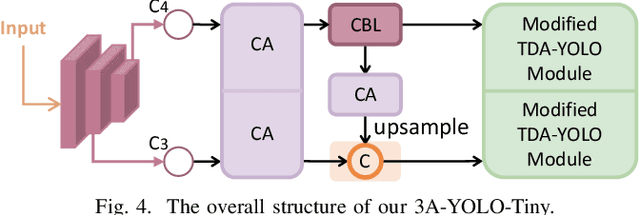
Recent research on real-time object detectors (e.g., YOLO series) has demonstrated the effectiveness of attention mechanisms for elevating model performance. Nevertheless, existing methods neglect to unifiedly deploy hierarchical attention mechanisms to construct a more discriminative YOLO head which is enriched with more useful intermediate features. To tackle this gap, this work aims to leverage multiple attention mechanisms to hierarchically enhance the triple discriminative awareness of the YOLO detection head and complementarily learn the coordinated intermediate representations, resulting in a new series detectors denoted 3A-YOLO. Specifically, we first propose a new head denoted TDA-YOLO Module, which unifiedly enhance the representations learning of scale-awareness, spatial-awareness, and task-awareness. Secondly, we steer the intermediate features to coordinately learn the inter-channel relationships and precise positional information. Finally, we perform neck network improvements followed by introducing various tricks to boost the adaptability of 3A-YOLO. Extensive experiments across COCO and VOC benchmarks indicate the effectiveness of our detectors.
Emotion Recognition by Video: A review
Oct 26, 2023



Video emotion recognition is an important branch of affective computing, and its solutions can be applied in different fields such as human-computer interaction (HCI) and intelligent medical treatment. Although the number of papers published in the field of emotion recognition is increasing, there are few comprehensive literature reviews covering related research on video emotion recognition. Therefore, this paper selects articles published from 2015 to 2023 to systematize the existing trends in video emotion recognition in related studies. In this paper, we first talk about two typical emotion models, then we talk about databases that are frequently utilized for video emotion recognition, including unimodal databases and multimodal databases. Next, we look at and classify the specific structure and performance of modern unimodal and multimodal video emotion recognition methods, talk about the benefits and drawbacks of each, and then we compare them in detail in the tables. Further, we sum up the primary difficulties right now looked by video emotion recognition undertakings and point out probably the most encouraging future headings, such as establishing an open benchmark database and better multimodal fusion strategys. The essential objective of this paper is to assist scholarly and modern scientists with keeping up to date with the most recent advances and new improvements in this speedy, high-influence field of video emotion recognition.